 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Limits of Preference Data for Post-Training
May 26, 2025Recent progress in strengthening the capabilities of large language models has stemmed from applying reinforcement learning to domains with automatically verifiable outcomes. A key question is whether we can similarly use RL to optimize for outcomes in domains where evaluating outcomes inherently requires human feedback; for example, in tasks like deep research and trip planning, outcome evaluation is qualitative and there are many possible degrees of success. One attractive and scalable modality for collecting human feedback is preference data: ordinal rankings (pairwise or $k$-wise) that indicate, for $k$ given outcomes, which one is preferred. In this work, we study a critical roadblock: preference data fundamentally and significantly limits outcome-based optimization. Even with idealized preference data (infinite, noiseless, and online), the use of ordinal feedback can prevent obtaining even approximately optimal solutions. We formalize this impossibility using voting theory, drawing an analogy between how a model chooses to answer a query with how voters choose a candidate to elect. This indicates that grounded human scoring and algorithmic innovations are necessary for extending the success of RL post-training to domains demanding human feedback. We also explore why these limitations have disproportionately impacted RLHF when it comes to eliciting reasoning behaviors (e.g., backtracking) versus situations where RLHF has been historically successful (e.g., instruction-tuning and safety training), finding that the limitations of preference data primarily suppress RLHF's ability to elicit robust strategies -- a class that encompasses most reasoning behaviors.
From Individual Experience to Collective Evidence: A Reporting-Based Framework for Identifying Systemic Harms
Feb 12, 2025When an individual reports a negative interaction with some system, how can their personal experience be contextualized within broader patterns of system behavior? We study the incident database problem, where individual reports of adverse events arrive sequentially, and are aggregated over time. In this work, our goal is to identify whether there are subgroups--defined by any combination of relevant features--that are disproportionately likely to experience harmful interactions with the system. We formalize this problem as a sequential hypothesis test, and identify conditions on reporting behavior that are sufficient for making inferences about disparities in true rates of harm across subgroups. We show that algorithms for sequential hypothesis tests can be applied to this problem with a standard multiple testing correction. We then demonstrate our method on real-world datasets, including mortgage decisions and vaccine side effects; on each, our method (re-)identifies subgroups known to experience disproportionate harm using only a fraction of the data that was initially used to discover them.
Learning With Multi-Group Guarantees For Clusterable Subpopulations
Oct 18, 2024
A canonical desideratum for prediction problems is that performance guarantees should hold not just on average over the population, but also for meaningful subpopulations within the overall population. But what constitutes a meaningful subpopulation? In this work, we take the perspective that relevant subpopulations should be defined with respect to the clusters that naturally emerge from the distribution of individuals for which predictions are being made. In this view, a population refers to a mixture model whose components constitute the relevant subpopulations. We suggest two formalisms for capturing per-subgroup guarantees: first, by attributing each individual to the component from which they were most likely drawn, given their features; and second, by attributing each individual to all components in proportion to their relative likelihood of having been drawn from each component. Using online calibration as a case study, we study a \variational algorithm that provides guarantees for each of these formalisms by handling all plausible underlying subpopulation structures simultaneously, and achieve an $O(T^{1/2})$ rate even when the subpopulations are not well-separated. In comparison, the more natural cluster-then-predict approach that first recovers the structure of the subpopulations and then makes predictions suffers from a $O(T^{2/3})$ rate and requires the subpopulations to be separable. Along the way, we prove that providing per-subgroup calibration guarantees for underlying clusters can be easier than learning the clusters: separation between median subgroup features is required for the latter but not the former.
Mapping Social Choice Theory to RLHF
Apr 19, 2024
Recent work on the limitations of using reinforcement learning from human feedback (RLHF) to incorporate human preferences into model behavior often raises social choice theory as a reference point. Social choice theory's analysis of settings such as voting mechanisms provides technical infrastructure that can inform how to aggregate human preferences amid disagreement. We analyze the problem settings of social choice and RLHF, identify key differences between them, and discuss how these differences may affect the RLHF interpretation of well-known technical results in social choice.
Can Probabilistic Feedback Drive User Impacts in Online Platforms?
Jan 25, 2024A common explanation for negative user impacts of content recommender systems is misalignment between the platform's objective and user welfare. In this work, we show that misalignment in the platform's objective is not the only potential cause of unintended impacts on users: even when the platform's objective is fully aligned with user welfare, the platform's learning algorithm can induce negative downstream impacts on users. The source of these user impacts is that different pieces of content may generate observable user reactions (feedback information) at different rates; these feedback rates may correlate with content properties, such as controversiality or demographic similarity of the creator, that affect the user experience. Since differences in feedback rates can impact how often the learning algorithm engages with different content, the learning algorithm may inadvertently promote content with certain such properties. Using the multi-armed bandit framework with probabilistic feedback, we examine the relationship between feedback rates and a learning algorithm's engagement with individual arms for different no-regret algorithms. We prove that no-regret algorithms can exhibit a wide range of dependencies: if the feedback rate of an arm increases, some no-regret algorithms engage with the arm more, some no-regret algorithms engage with the arm less, and other no-regret algorithms engage with the arm approximately the same number of times. From a platform design perspective, our results highlight the importance of looking beyond regret when measuring an algorithm's performance, and assessing the nature of a learning algorithm's engagement with different types of content as well as their resulting downstream impacts.
Fairness via Explanation Quality: Evaluating Disparities in the Quality of Post hoc Explanations
May 15, 2022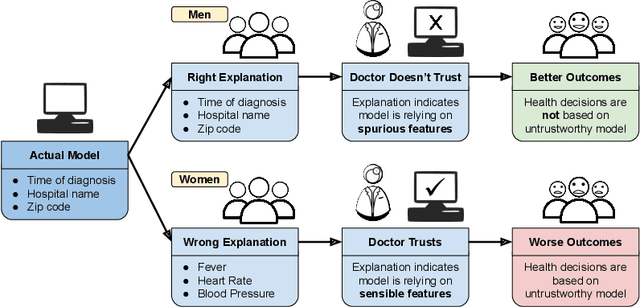
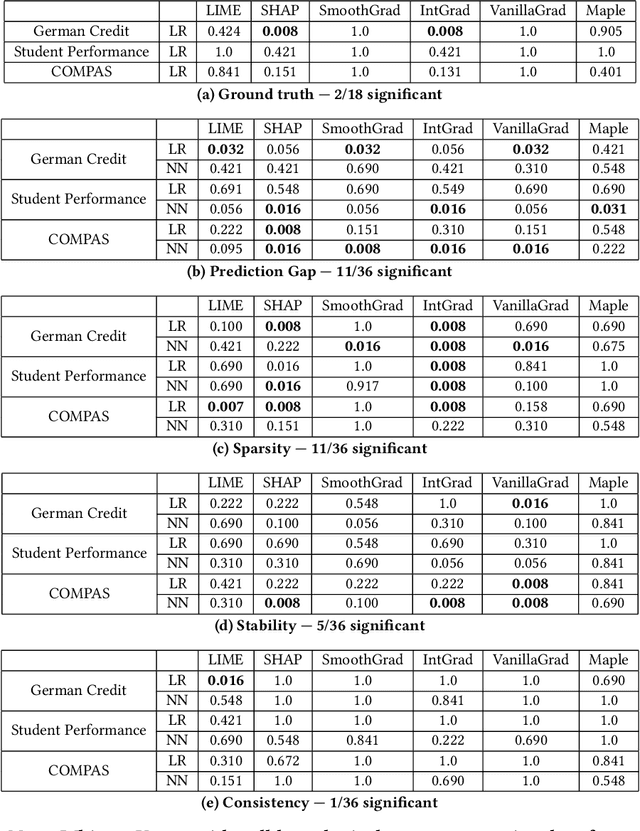
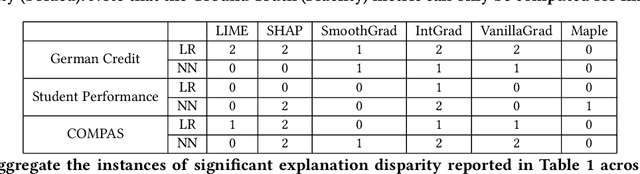
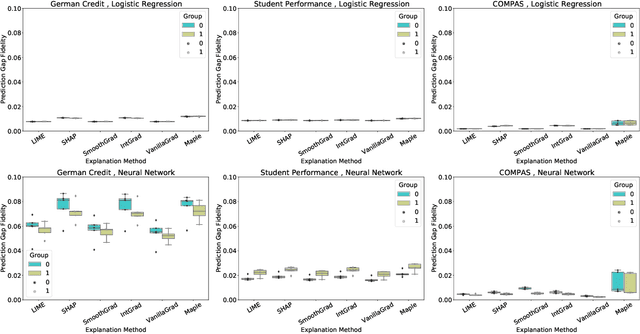
As post hoc explanation methods are increasingly being leveraged to explain complex models in high-stakes settings, it becomes critical to ensure that the quality of the resulting explanations is consistently high across various population subgroups including the minority groups. For instance, it should not be the case that explanations associated with instances belonging to a particular gender subgroup (e.g., female) are less accurate than those associated with other genders. However, there is little to no research that assesses if there exist such group-based disparities in the quality of the explanations output by state-of-the-art explanation methods. In this work, we address the aforementioned gaps by initiating the study of identifying group-based disparities in explanation quality. To this end, we first outline the key properties which constitute explanation quality and where disparities can be particularly problematic. We then leverage these properties to propose a novel evaluation framework which can quantitatively measure disparities in the quality of explanations output by state-of-the-art methods. Using this framework, we carry out a rigorous empirical analysis to understand if and when group-based disparities in explanation quality arise. Our results indicate that such disparities are more likely to occur when the models being explained are complex and highly non-linear. In addition, we also observe that certain post hoc explanation methods (e.g., Integrated Gradients, SHAP) are more likely to exhibit the aforementioned disparities. To the best of our knowledge, this work is the first to highlight and study the problem of group-based disparities in explanation quality. In doing so, our work sheds light on previously unexplored ways in which explanation methods may introduce unfairness in real world decision making.
Achieving Downstream Fairness with Geometric Repair
Mar 14, 2022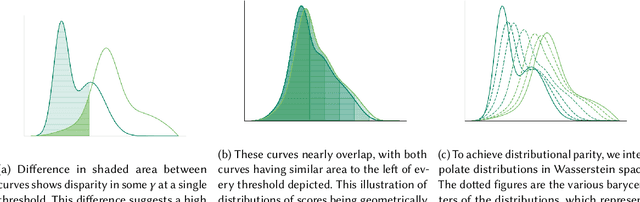
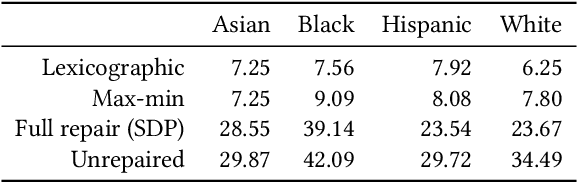
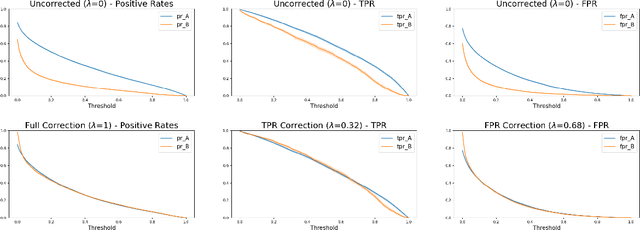

Consider a scenario where some upstream model developer must train a fair model, but is unaware of the fairness requirements of a downstream model user or stakeholder. In the context of fair classification, we present a technique that specifically addresses this setting, by post-processing a regressor's scores such they yield fair classifications for any downstream choice in decision threshold. To begin, we leverage ideas from optimal transport to show how this can be achieved for binary protected groups across a broad class of fairness metrics. Then, we extend our approach to address the setting where a protected attribute takes on multiple values, by re-recasting our technique as a convex optimization problem that leverages lexicographic fairness.
What will it take to generate fairness-preserving explanations?
Jun 24, 2021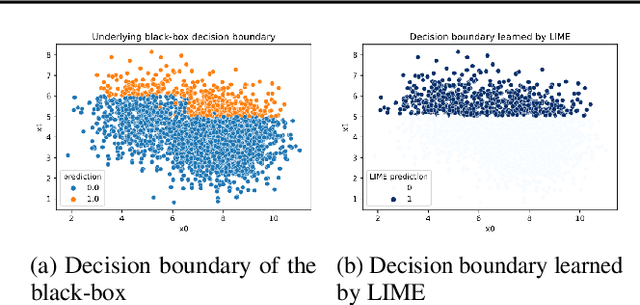
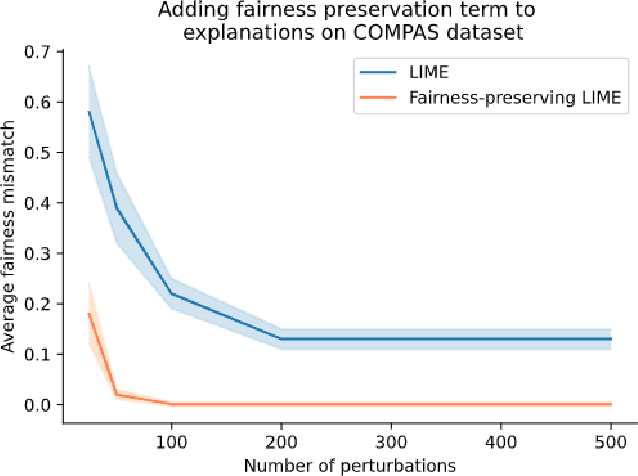
In situations where explanations of black-box models may be useful, the fairness of the black-box is also often a relevant concern. However, the link between the fairness of the black-box model and the behavior of explanations for the black-box is unclear. We focus on explanations applied to tabular datasets, suggesting that explanations do not necessarily preserve the fairness properties of the black-box algorithm. In other words, explanation algorithms can ignore or obscure critical relevant properties, creating incorrect or misleading explanations. More broadly, we propose future research directions for evaluating and generating explanations such that they are informative and relevant from a fairness perspective.
Fair Machine Learning Under Partial Compliance
Nov 10, 2020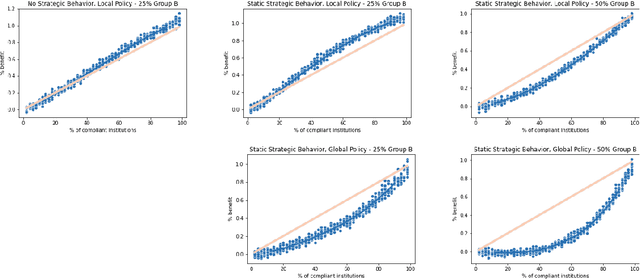
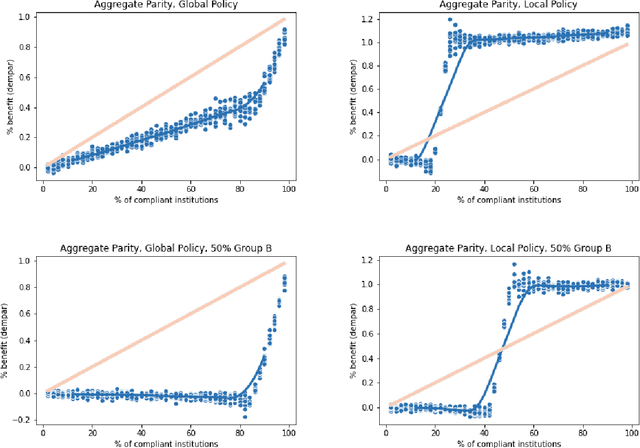
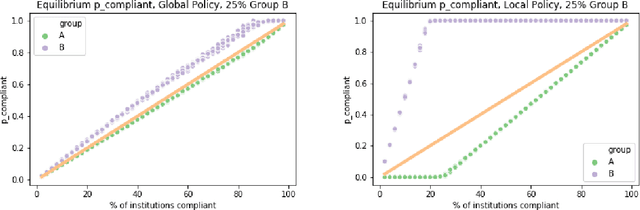
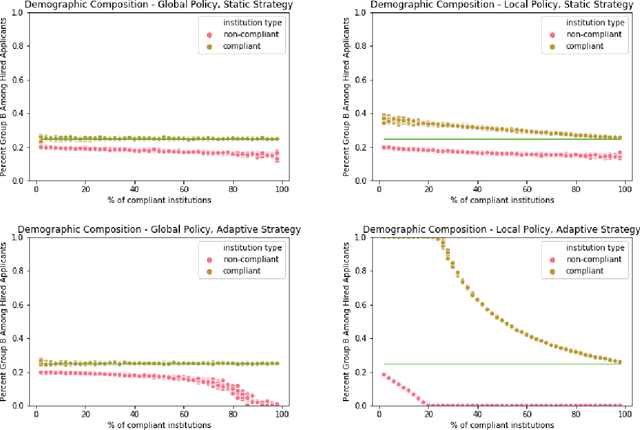
Typically, fair machine learning research focuses on a single decisionmaker and assumes that the underlying population is stationary. However, many of the critical domains motivating this work are characterized by competitive marketplaces with many decisionmakers. Realistically, we might expect only a subset of them to adopt any non-compulsory fairness-conscious policy, a situation that political philosophers call partial compliance. This possibility raises important questions: how does the strategic behavior of decision subjects in partial compliance settings affect the allocation outcomes? If k% of employers were to voluntarily adopt a fairness-promoting intervention, should we expect k% progress (in aggregate) towards the benefits of universal adoption, or will the dynamics of partial compliance wash out the hoped-for benefits? How might adopting a global (versus local) perspective impact the conclusions of an auditor? In this paper, we propose a simple model of an employment market, leveraging simulation as a tool to explore the impact of both interaction effects and incentive effects on outcomes and auditing metrics. Our key findings are that at equilibrium: (1) partial compliance (k% of employers) can result in far less than proportional (k%) progress towards the full compliance outcomes; (2) the gap is more severe when fair employers match global (vs local) statistics; (3) choices of local vs global statistics can paint dramatically different pictures of the performance vis-a-vis fairness desiderata of compliant versus non-compliant employers; and (4) partial compliance to local parity measures can induce extreme segregation.