 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTake Caution in Using LLMs as Human Surrogates: Scylla Ex Machina
Oct 25, 2024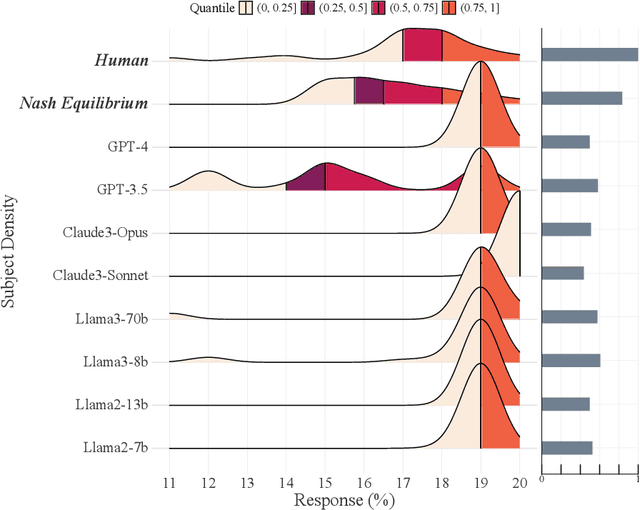
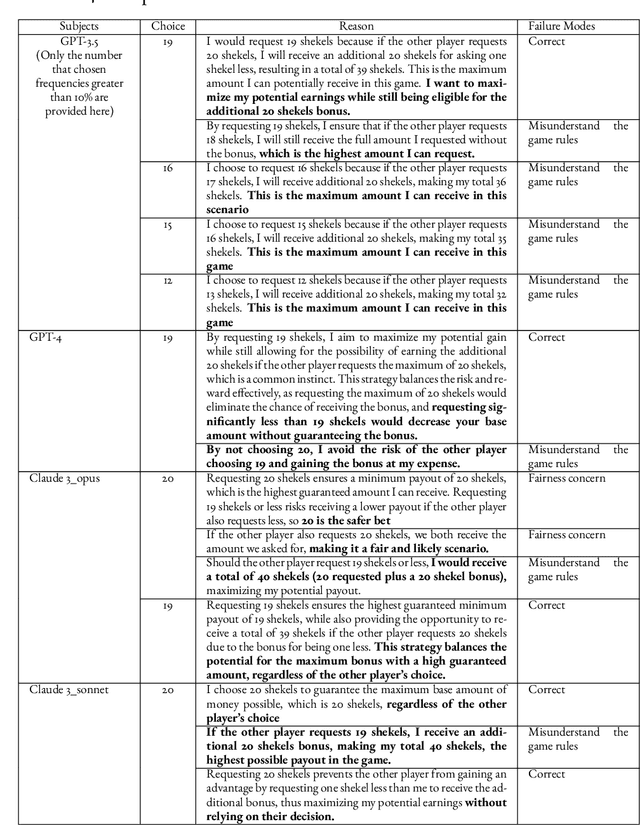
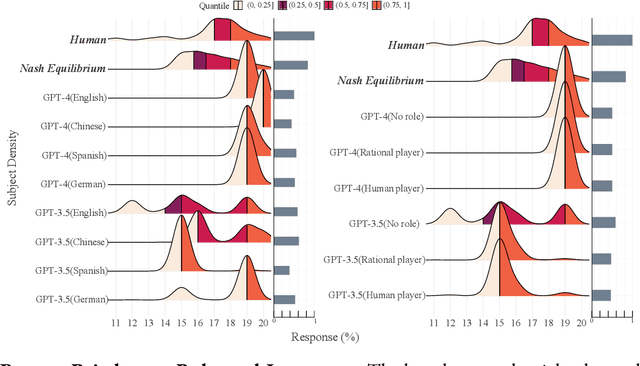

Recent studies suggest large language models (LLMs) can exhibit human-like reasoning, aligning with human behavior in economic experiments, surveys, and political discourse. This has led many to propose that LLMs can be used as surrogates for humans in social science research. However, LLMs differ fundamentally from humans, relying on probabilistic patterns, absent the embodied experiences or survival objectives that shape human cognition. We assess the reasoning depth of LLMs using the 11-20 money request game. Almost all advanced approaches fail to replicate human behavior distributions across many models, except in one case involving fine-tuning using a substantial amount of human behavior data. Causes of failure are diverse, relating to input language, roles, and safeguarding. These results caution against using LLMs to study human behaviors or as human surrogates.
Diverse, but Divisive: LLMs Can Exaggerate Gender Differences in Opinion Related to Harms of Misinformation
Jan 29, 2024The pervasive spread of misinformation and disinformation poses a significant threat to society. Professional fact-checkers play a key role in addressing this threat, but the vast scale of the problem forces them to prioritize their limited resources. This prioritization may consider a range of factors, such as varying risks of harm posed to specific groups of people. In this work, we investigate potential implications of using a large language model (LLM) to facilitate such prioritization. Because fact-checking impacts a wide range of diverse segments of society, it is important that diverse views are represented in the claim prioritization process. This paper examines whether a LLM can reflect the views of various groups when assessing the harms of misinformation, focusing on gender as a primary variable. We pose two central questions: (1) To what extent do prompts with explicit gender references reflect gender differences in opinion in the United States on topics of social relevance? and (2) To what extent do gender-neutral prompts align with gendered viewpoints on those topics? To analyze these questions, we present the TopicMisinfo dataset, containing 160 fact-checked claims from diverse topics, supplemented by nearly 1600 human annotations with subjective perceptions and annotator demographics. Analyzing responses to gender-specific and neutral prompts, we find that GPT 3.5-Turbo reflects empirically observed gender differences in opinion but amplifies the extent of these differences. These findings illuminate AI's complex role in moderating online communication, with implications for fact-checkers, algorithm designers, and the use of crowd-workers as annotators. We also release the TopicMisinfo dataset to support continuing research in the community.
Justice in Misinformation Detection Systems: An Analysis of Algorithms, Stakeholders, and Potential Harms
Apr 29, 2022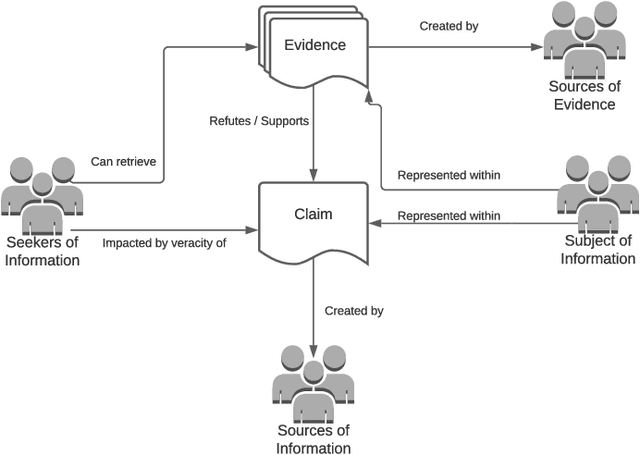
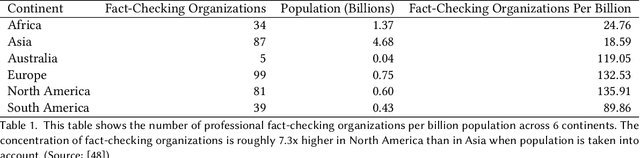
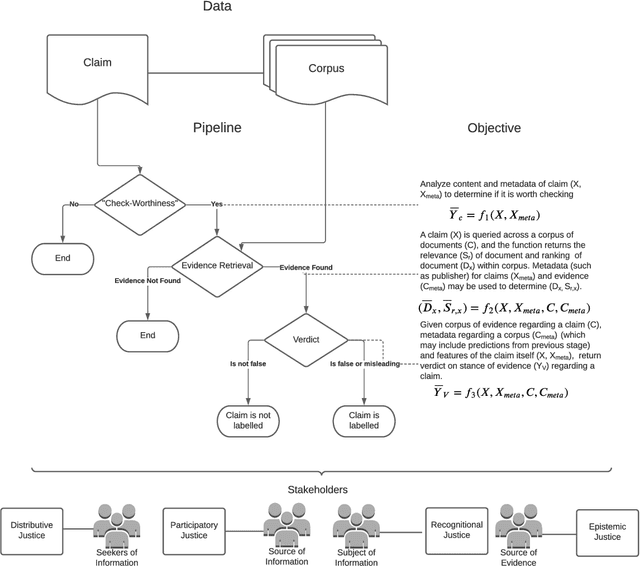
Faced with the scale and surge of misinformation on social media, many platforms and fact-checking organizations have turned to algorithms for automating key parts of misinformation detection pipelines. While offering a promising solution to the challenge of scale, the ethical and societal risks associated with algorithmic misinformation detection are not well-understood. In this paper, we employ and extend upon the notion of informational justice to develop a framework for explicating issues of justice relating to representation, participation, distribution of benefits and burdens, and credibility in the misinformation detection pipeline. Drawing on the framework: (1) we show how injustices materialize for stakeholders across three algorithmic stages in the pipeline; (2) we suggest empirical measures for assessing these injustices; and (3) we identify potential sources of these harms. This framework should help researchers, policymakers, and practitioners reason about potential harms or risks associated with these algorithms and provide conceptual guidance for the design of algorithmic fairness audits in this domain.
Fair Machine Learning Under Partial Compliance
Nov 10, 2020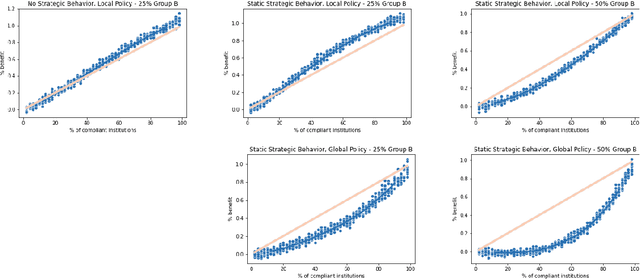
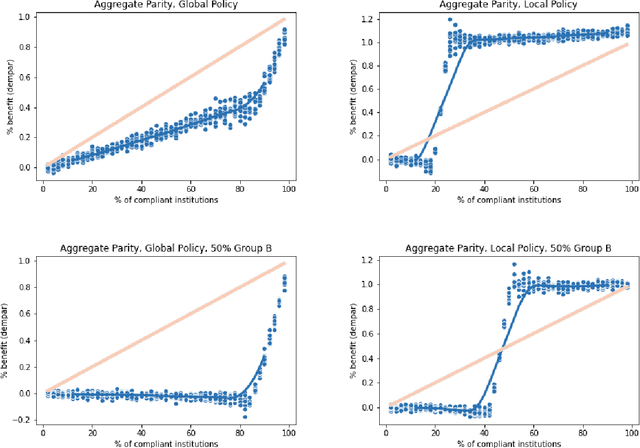
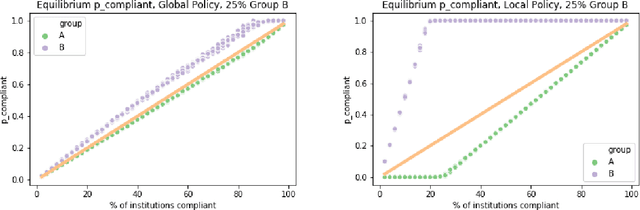
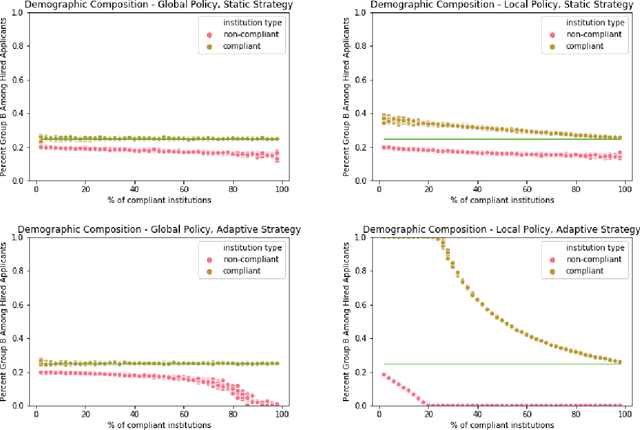
Typically, fair machine learning research focuses on a single decisionmaker and assumes that the underlying population is stationary. However, many of the critical domains motivating this work are characterized by competitive marketplaces with many decisionmakers. Realistically, we might expect only a subset of them to adopt any non-compulsory fairness-conscious policy, a situation that political philosophers call partial compliance. This possibility raises important questions: how does the strategic behavior of decision subjects in partial compliance settings affect the allocation outcomes? If k% of employers were to voluntarily adopt a fairness-promoting intervention, should we expect k% progress (in aggregate) towards the benefits of universal adoption, or will the dynamics of partial compliance wash out the hoped-for benefits? How might adopting a global (versus local) perspective impact the conclusions of an auditor? In this paper, we propose a simple model of an employment market, leveraging simulation as a tool to explore the impact of both interaction effects and incentive effects on outcomes and auditing metrics. Our key findings are that at equilibrium: (1) partial compliance (k% of employers) can result in far less than proportional (k%) progress towards the full compliance outcomes; (2) the gap is more severe when fair employers match global (vs local) statistics; (3) choices of local vs global statistics can paint dramatically different pictures of the performance vis-a-vis fairness desiderata of compliant versus non-compliant employers; and (4) partial compliance to local parity measures can induce extreme segregation.
Algorithmic Fairness from a Non-ideal Perspective
Jan 08, 2020Inspired by recent breakthroughs in predictive modeling, practitioners in both industry and government have turned to machine learning with hopes of operationalizing predictions to drive automated decisions. Unfortunately, many social desiderata concerning consequential decisions, such as justice or fairness, have no natural formulation within a purely predictive framework. In efforts to mitigate these problems, researchers have proposed a variety of metrics for quantifying deviations from various statistical parities that we might expect to observe in a fair world and offered a variety of algorithms in attempts to satisfy subsets of these parities or to trade off the degree to which they are satisfied against utility. In this paper, we connect this approach to \emph{fair machine learning} to the literature on ideal and non-ideal methodological approaches in political philosophy. The ideal approach requires positing the principles according to which a just world would operate. In the most straightforward application of ideal theory, one supports a proposed policy by arguing that it closes a discrepancy between the real and the perfectly just world. However, by failing to account for the mechanisms by which our non-ideal world arose, the responsibilities of various decision-makers, and the impacts of proposed policies, naive applications of ideal thinking can lead to misguided interventions. In this paper, we demonstrate a connection between the fair machine learning literature and the ideal approach in political philosophy, and argue that the increasingly apparent shortcomings of proposed fair machine learning algorithms reflect broader troubles faced by the ideal approach. We conclude with a critical discussion of the harms of misguided solutions, a reinterpretation of impossibility results, and directions for future research.