 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias-Aware Mislabeling Detection via Decoupled Confident Learning
Jul 09, 2025
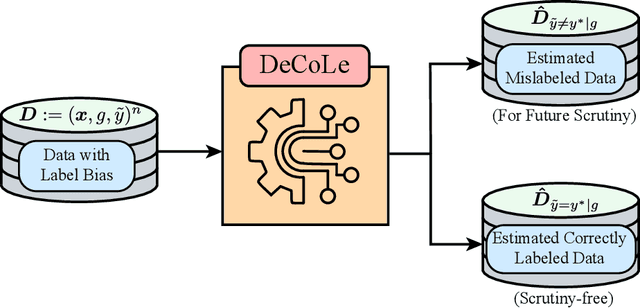

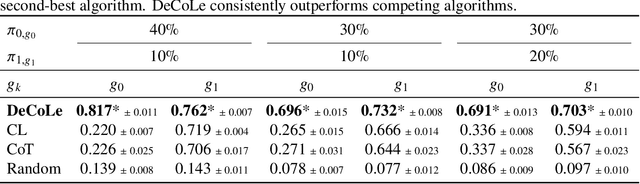
Reliable data is a cornerstone of modern organizational systems. A notable data integrity challenge stems from label bias, which refers to systematic errors in a label, a covariate that is central to a quantitative analysis, such that its quality differs across social groups. This type of bias has been conceptually and empirically explored and is widely recognized as a pressing issue across critical domains. However, effective methodologies for addressing it remain scarce. In this work, we propose Decoupled Confident Learning (DeCoLe), a principled machine learning based framework specifically designed to detect mislabeled instances in datasets affected by label bias, enabling bias aware mislabelling detection and facilitating data quality improvement. We theoretically justify the effectiveness of DeCoLe and evaluate its performance in the impactful context of hate speech detection, a domain where label bias is a well documented challenge. Empirical results demonstrate that DeCoLe excels at bias aware mislabeling detection, consistently outperforming alternative approaches for label error detection. Our work identifies and addresses the challenge of bias aware mislabeling detection and offers guidance on how DeCoLe can be integrated into organizational data management practices as a powerful tool to enhance data reliability.
Perils of Label Indeterminacy: A Case Study on Prediction of Neurological Recovery After Cardiac Arrest
Apr 05, 2025



The design of AI systems to assist human decision-making typically requires the availability of labels to train and evaluate supervised models. Frequently, however, these labels are unknown, and different ways of estimating them involve unverifiable assumptions or arbitrary choices. In this work, we introduce the concept of label indeterminacy and derive important implications in high-stakes AI-assisted decision-making. We present an empirical study in a healthcare context, focusing specifically on predicting the recovery of comatose patients after resuscitation from cardiac arrest. Our study shows that label indeterminacy can result in models that perform similarly when evaluated on patients with known labels, but vary drastically in their predictions for patients where labels are unknown. After demonstrating crucial ethical implications of label indeterminacy in this high-stakes context, we discuss takeaways for evaluation, reporting, and design.
Using Machine Bias To Measure Human Bias
Dec 10, 2024
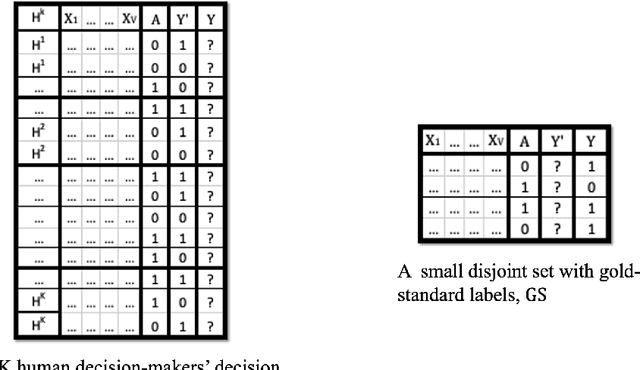
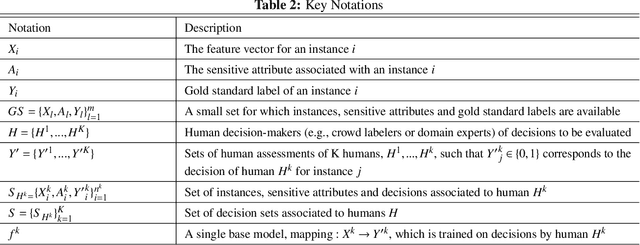

Biased human decisions have consequential impacts across various domains, yielding unfair treatment of individuals and resulting in suboptimal outcomes for organizations and society. In recognition of this fact, organizations regularly design and deploy interventions aimed at mitigating these biases. However, measuring human decision biases remains an important but elusive task. Organizations are frequently concerned with mistaken decisions disproportionately affecting one group. In practice, however, this is typically not possible to assess due to the scarcity of a gold standard: a label that indicates what the correct decision would have been. In this work, we propose a machine learning-based framework to assess bias in human-generated decisions when gold standard labels are scarce. We provide theoretical guarantees and empirical evidence demonstrating the superiority of our method over existing alternatives. This proposed methodology establishes a foundation for transparency in human decision-making, carrying substantial implications for managerial duties, and offering potential for alleviating algorithmic biases when human decisions are used as labels to train algorithms.
Fairly Accurate: Optimizing Accuracy Parity in Fair Target-Group Detection
Jul 16, 2024



In algorithmic toxicity detection pipelines, it is important to identify which demographic group(s) are the subject of a post, a task commonly known as \textit{target (group) detection}. While accurate detection is clearly important, we further advocate a fairness objective: to provide equal protection to all groups who may be targeted. To this end, we adopt \textit{Accuracy Parity} (AP) -- balanced detection accuracy across groups -- as our fairness objective. However, in order to align model training with our AP fairness objective, we require an equivalent loss function. Moreover, for gradient-based models such as neural networks, this loss function needs to be differentiable. Because no such loss function exists today for AP, we propose \emph{Group Accuracy Parity} (GAP): the first differentiable loss function having a one-on-one mapping to AP. We empirically show that GAP addresses disparate impact on groups for target detection. Furthermore, because a single post often targets multiple groups in practice, we also provide a mathematical extension of GAP to larger multi-group settings, something typically requiring heuristics in prior work. Our findings show that by optimizing AP, GAP better mitigates bias in comparison with other commonly employed loss functions.
Diverse, but Divisive: LLMs Can Exaggerate Gender Differences in Opinion Related to Harms of Misinformation
Jan 29, 2024The pervasive spread of misinformation and disinformation poses a significant threat to society. Professional fact-checkers play a key role in addressing this threat, but the vast scale of the problem forces them to prioritize their limited resources. This prioritization may consider a range of factors, such as varying risks of harm posed to specific groups of people. In this work, we investigate potential implications of using a large language model (LLM) to facilitate such prioritization. Because fact-checking impacts a wide range of diverse segments of society, it is important that diverse views are represented in the claim prioritization process. This paper examines whether a LLM can reflect the views of various groups when assessing the harms of misinformation, focusing on gender as a primary variable. We pose two central questions: (1) To what extent do prompts with explicit gender references reflect gender differences in opinion in the United States on topics of social relevance? and (2) To what extent do gender-neutral prompts align with gendered viewpoints on those topics? To analyze these questions, we present the TopicMisinfo dataset, containing 160 fact-checked claims from diverse topics, supplemented by nearly 1600 human annotations with subjective perceptions and annotator demographics. Analyzing responses to gender-specific and neutral prompts, we find that GPT 3.5-Turbo reflects empirically observed gender differences in opinion but amplifies the extent of these differences. These findings illuminate AI's complex role in moderating online communication, with implications for fact-checkers, algorithm designers, and the use of crowd-workers as annotators. We also release the TopicMisinfo dataset to support continuing research in the community.
A Critical Survey on Fairness Benefits of XAI
Oct 15, 2023



In this critical survey, we analyze typical claims on the relationship between explainable AI (XAI) and fairness to disentangle the multidimensional relationship between these two concepts. Based on a systematic literature review and a subsequent qualitative content analysis, we identify seven archetypal claims from 175 papers on the alleged fairness benefits of XAI. We present crucial caveats with respect to these claims and provide an entry point for future discussions around the potentials and limitations of XAI for specific fairness desiderata. While the literature often suggests XAI to be an enabler for several fairness desiderata, we notice a misalignment between these desiderata and the capabilities of XAI. We encourage to conceive XAI as one of many tools to approach the multidimensional, sociotechnical challenge of algorithmic fairness and to be more specific about how exactly what kind of XAI method enables whom to address which fairness desideratum.
Mitigating Label Bias via Decoupled Confident Learning
Jul 18, 2023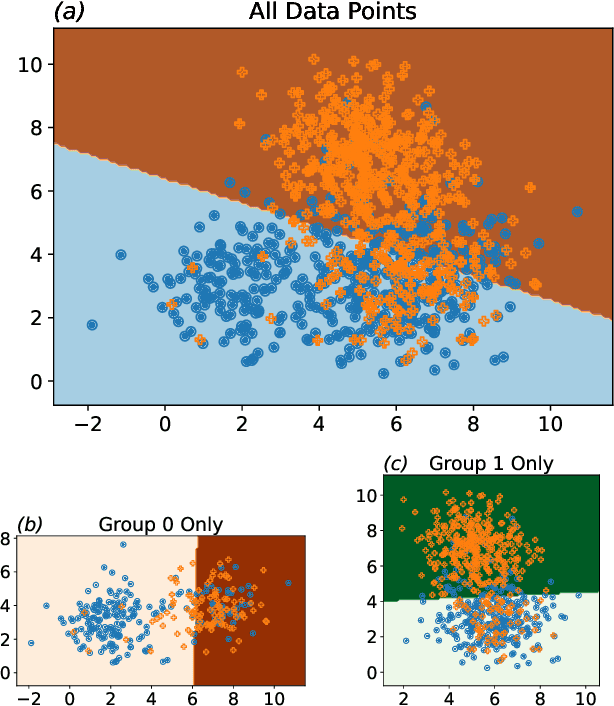
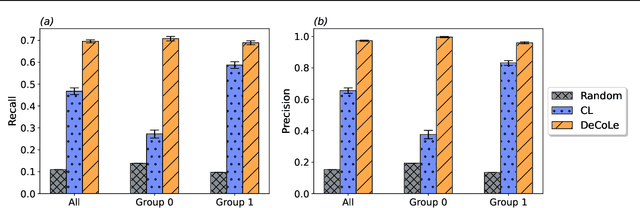
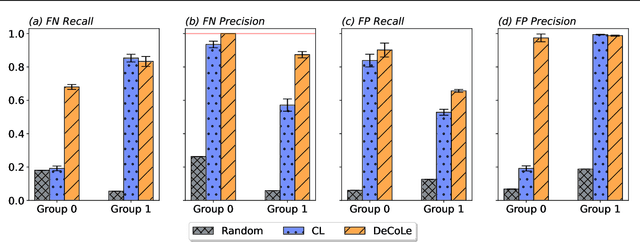
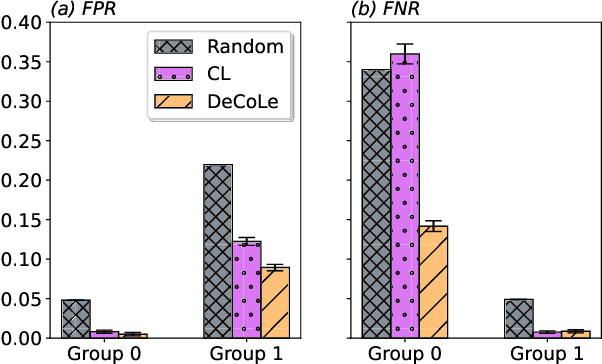
Growing concerns regarding algorithmic fairness have led to a surge in methodologies to mitigate algorithmic bias. However, such methodologies largely assume that observed labels in training data are correct. This is problematic because bias in labels is pervasive across important domains, including healthcare, hiring, and content moderation. In particular, human-generated labels are prone to encoding societal biases. While the presence of labeling bias has been discussed conceptually, there is a lack of methodologies to address this problem. We propose a pruning method -- Decoupled Confident Learning (DeCoLe) -- specifically designed to mitigate label bias. After illustrating its performance on a synthetic dataset, we apply DeCoLe in the context of hate speech detection, where label bias has been recognized as an important challenge, and show that it successfully identifies biased labels and outperforms competing approaches.
Human-Centered Responsible Artificial Intelligence: Current & Future Trends
Feb 16, 2023
In recent years, the CHI community has seen significant growth in research on Human-Centered Responsible Artificial Intelligence. While different research communities may use different terminology to discuss similar topics, all of this work is ultimately aimed at developing AI that benefits humanity while being grounded in human rights and ethics, and reducing the potential harms of AI. In this special interest group, we aim to bring together researchers from academia and industry interested in these topics to map current and future research trends to advance this important area of research by fostering collaboration and sharing ideas.
Same Same, But Different: Conditional Multi-Task Learning for Demographic-Specific Toxicity Detection
Feb 14, 2023



Algorithmic bias often arises as a result of differential subgroup validity, in which predictive relationships vary across groups. For example, in toxic language detection, comments targeting different demographic groups can vary markedly across groups. In such settings, trained models can be dominated by the relationships that best fit the majority group, leading to disparate performance. We propose framing toxicity detection as multi-task learning (MTL), allowing a model to specialize on the relationships that are relevant to each demographic group while also leveraging shared properties across groups. With toxicity detection, each task corresponds to identifying toxicity against a particular demographic group. However, traditional MTL requires labels for all tasks to be present for every data point. To address this, we propose Conditional MTL (CondMTL), wherein only training examples relevant to the given demographic group are considered by the loss function. This lets us learn group specific representations in each branch which are not cross contaminated by irrelevant labels. Results on synthetic and real data show that using CondMTL improves predictive recall over various baselines in general and for the minority demographic group in particular, while having similar overall accuracy.
Learning Complementary Policies for Human-AI Teams
Feb 06, 2023

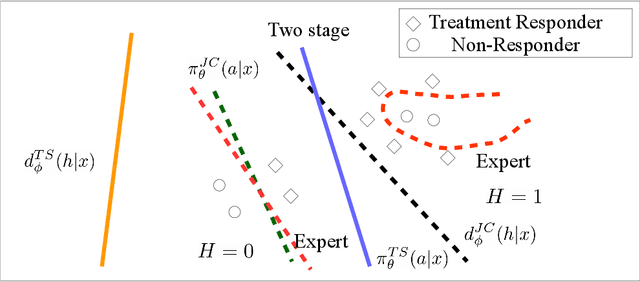
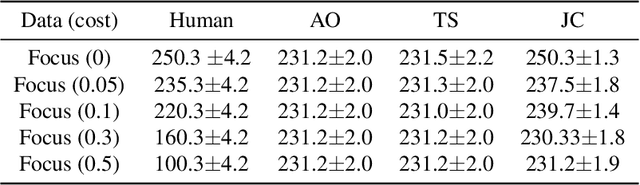
Human-AI complementarity is important when neither the algorithm nor the human yields dominant performance across all instances in a given context. Recent work that explored human-AI collaboration has considered decisions that correspond to classification tasks. However, in many important contexts where humans can benefit from AI complementarity, humans undertake course of action. In this paper, we propose a framework for a novel human-AI collaboration for selecting advantageous course of action, which we refer to as Learning Complementary Policy for Human-AI teams (\textsc{lcp-hai}). Our solution aims to exploit the human-AI complementarity to maximize decision rewards by learning both an algorithmic policy that aims to complement humans by a routing model that defers decisions to either a human or the AI to leverage the resulting complementarity. We then extend our approach to leverage opportunities and mitigate risks that arise in important contexts in practice: 1) when a team is composed of multiple humans with differential and potentially complementary abilities, 2) when the observational data includes consistent deterministic actions, and 3) when the covariate distribution of future decisions differ from that in the historical data. We demonstrate the effectiveness of our proposed methods using data on real human responses and semi-synthetic, and find that our methods offer reliable and advantageous performance across setting, and that it is superior to when either the algorithm or the AI make decisions on their own. We also find that the extensions we propose effectively improve the robustness of the human-AI collaboration performance in the presence of different challenging settings.