 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Label Bias via Decoupled Confident Learning
Paper and Code
Jul 18, 2023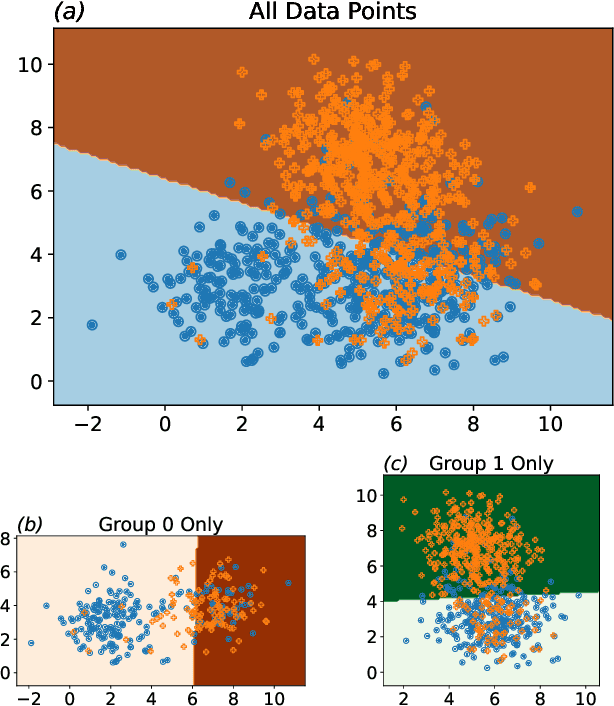
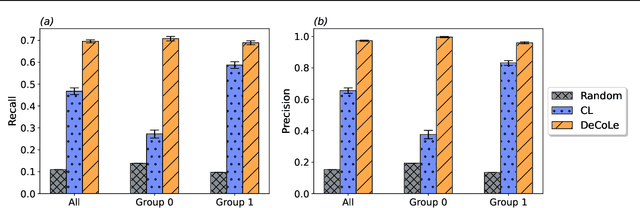
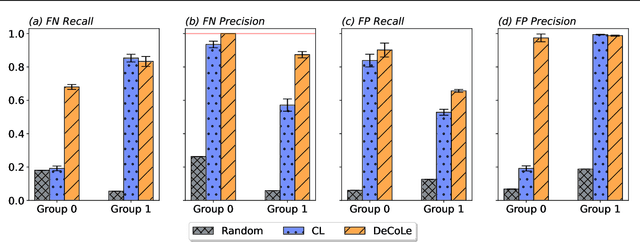
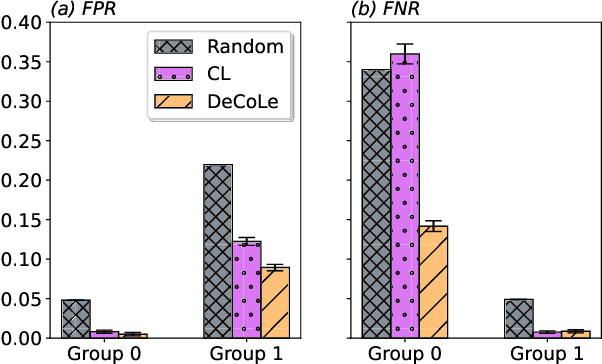
Growing concerns regarding algorithmic fairness have led to a surge in methodologies to mitigate algorithmic bias. However, such methodologies largely assume that observed labels in training data are correct. This is problematic because bias in labels is pervasive across important domains, including healthcare, hiring, and content moderation. In particular, human-generated labels are prone to encoding societal biases. While the presence of labeling bias has been discussed conceptually, there is a lack of methodologies to address this problem. We propose a pruning method -- Decoupled Confident Learning (DeCoLe) -- specifically designed to mitigate label bias. After illustrating its performance on a synthetic dataset, we apply DeCoLe in the context of hate speech detection, where label bias has been recognized as an important challenge, and show that it successfully identifies biased labels and outperforms competing approaches.