 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias-Aware Mislabeling Detection via Decoupled Confident Learning
Jul 09, 2025
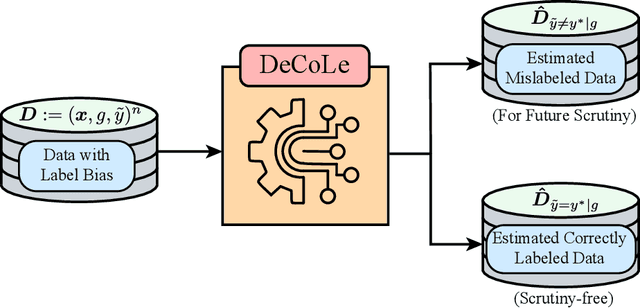

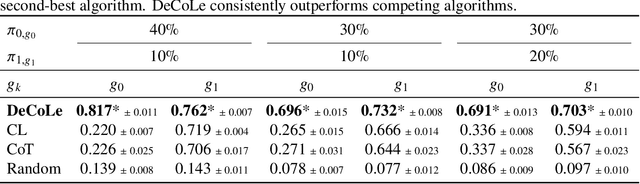
Reliable data is a cornerstone of modern organizational systems. A notable data integrity challenge stems from label bias, which refers to systematic errors in a label, a covariate that is central to a quantitative analysis, such that its quality differs across social groups. This type of bias has been conceptually and empirically explored and is widely recognized as a pressing issue across critical domains. However, effective methodologies for addressing it remain scarce. In this work, we propose Decoupled Confident Learning (DeCoLe), a principled machine learning based framework specifically designed to detect mislabeled instances in datasets affected by label bias, enabling bias aware mislabelling detection and facilitating data quality improvement. We theoretically justify the effectiveness of DeCoLe and evaluate its performance in the impactful context of hate speech detection, a domain where label bias is a well documented challenge. Empirical results demonstrate that DeCoLe excels at bias aware mislabeling detection, consistently outperforming alternative approaches for label error detection. Our work identifies and addresses the challenge of bias aware mislabeling detection and offers guidance on how DeCoLe can be integrated into organizational data management practices as a powerful tool to enhance data reliability.
The Value of AI Advice: Personalized and Value-Maximizing AI Advisors Are Necessary to Reliably Benefit Experts and Organizations
Dec 27, 2024



Despite advances in AI's performance and interpretability, AI advisors can undermine experts' decisions and increase the time and effort experts must invest to make decisions. Consequently, AI systems deployed in high-stakes settings often fail to consistently add value across contexts and can even diminish the value that experts alone provide. Beyond harm in specific domains, such outcomes impede progress in research and practice, underscoring the need to understand when and why different AI advisors add or diminish value. To bridge this gap, we stress the importance of assessing the value AI advice brings to real-world contexts when designing and evaluating AI advisors. Building on this perspective, we characterize key pillars -- pathways through which AI advice impacts value -- and develop a framework that incorporates these pillars to create reliable, personalized, and value-adding advisors. Our results highlight the need for system-level, value-driven development of AI advisors that advise selectively, are tailored to experts' unique behaviors, and are optimized for context-specific trade-offs between decision improvements and advising costs. They also reveal how the lack of inclusion of these pillars in the design of AI advising systems may be contributing to the failures observed in practical applications.
Using Machine Bias To Measure Human Bias
Dec 10, 2024
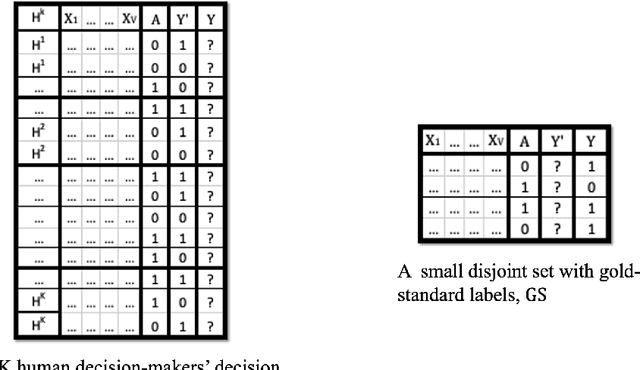
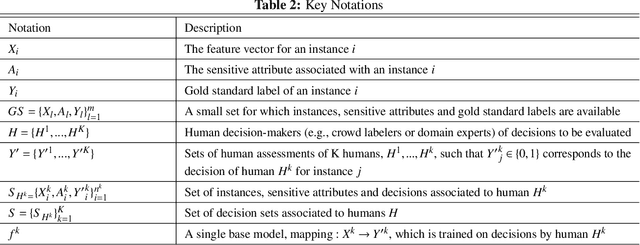

Biased human decisions have consequential impacts across various domains, yielding unfair treatment of individuals and resulting in suboptimal outcomes for organizations and society. In recognition of this fact, organizations regularly design and deploy interventions aimed at mitigating these biases. However, measuring human decision biases remains an important but elusive task. Organizations are frequently concerned with mistaken decisions disproportionately affecting one group. In practice, however, this is typically not possible to assess due to the scarcity of a gold standard: a label that indicates what the correct decision would have been. In this work, we propose a machine learning-based framework to assess bias in human-generated decisions when gold standard labels are scarce. We provide theoretical guarantees and empirical evidence demonstrating the superiority of our method over existing alternatives. This proposed methodology establishes a foundation for transparency in human decision-making, carrying substantial implications for managerial duties, and offering potential for alleviating algorithmic biases when human decisions are used as labels to train algorithms.
Fighting Bias with Bias: A Machine Learning Approach to Assess Human Bias
Dec 02, 2024Biased human decisions have consequential impacts across various domains, yielding unfair treatment of individuals and resulting in suboptimal outcomes for organizations and society. In recognition of this fact, organizations regularly design and deploy interventions aimed at mitigating these biases. However, measuring human decision biases remains an important but elusive task. Organizations are frequently concerned with mistaken decisions disproportionately affecting one group. In practice, however, this is typically not possible to assess due to the scarcity of a gold standard: a label that indicates what the correct decision would have been. In this work, we propose a machine learning-based framework to assess bias in human-generated decisions when gold standard labels are scarce. We provide theoretical guarantees and empirical evidence demonstrating the superiority of our method over existing alternatives. This proposed methodology establishes a foundation for transparency in human decision-making, carrying substantial implications for managerial duties, and offering potential for alleviating algorithmic biases when human decisions are used as labels to train algorithms.
Data-Driven Allocation of Preventive Care With Application to Diabetes Mellitus Type II
Aug 14, 2023

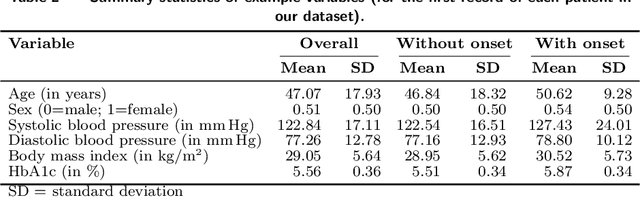
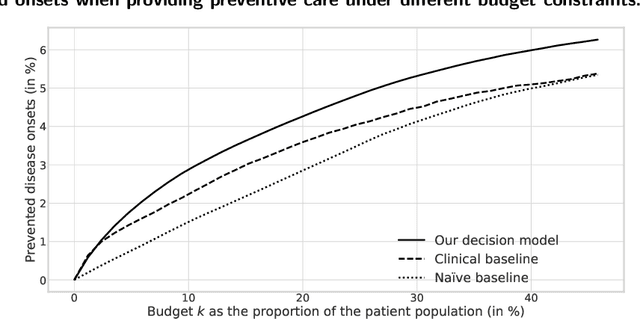
Problem Definition. Increasing costs of healthcare highlight the importance of effective disease prevention. However, decision models for allocating preventive care are lacking. Methodology/Results. In this paper, we develop a data-driven decision model for determining a cost-effective allocation of preventive treatments to patients at risk. Specifically, we combine counterfactual inference, machine learning, and optimization techniques to build a scalable decision model that can exploit high-dimensional medical data, such as the data found in modern electronic health records. Our decision model is evaluated based on electronic health records from 89,191 prediabetic patients. We compare the allocation of preventive treatments (metformin) prescribed by our data-driven decision model with that of current practice. We find that if our approach is applied to the U.S. population, it can yield annual savings of $1.1 billion. Finally, we analyze the cost-effectiveness under varying budget levels. Managerial Implications. Our work supports decision-making in health management, with the goal of achieving effective disease prevention at lower costs. Importantly, our decision model is generic and can thus be used for effective allocation of preventive care for other preventable diseases.
Mitigating Label Bias via Decoupled Confident Learning
Jul 18, 2023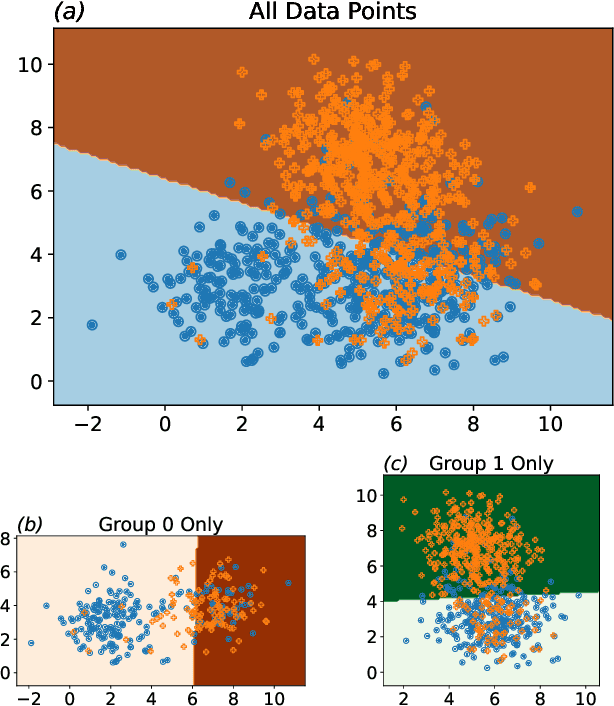
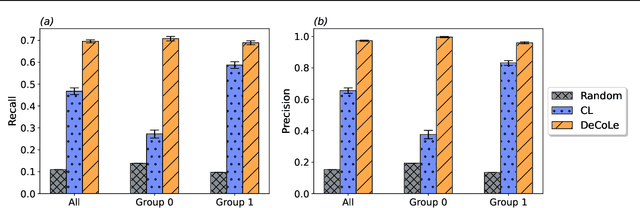
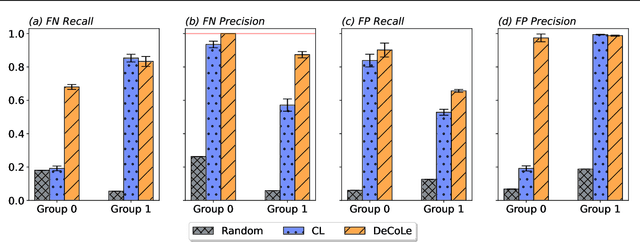
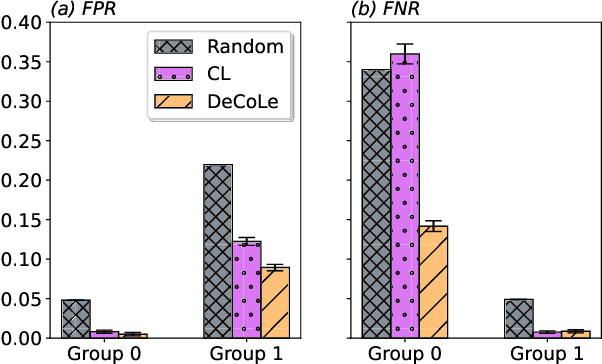
Growing concerns regarding algorithmic fairness have led to a surge in methodologies to mitigate algorithmic bias. However, such methodologies largely assume that observed labels in training data are correct. This is problematic because bias in labels is pervasive across important domains, including healthcare, hiring, and content moderation. In particular, human-generated labels are prone to encoding societal biases. While the presence of labeling bias has been discussed conceptually, there is a lack of methodologies to address this problem. We propose a pruning method -- Decoupled Confident Learning (DeCoLe) -- specifically designed to mitigate label bias. After illustrating its performance on a synthetic dataset, we apply DeCoLe in the context of hate speech detection, where label bias has been recognized as an important challenge, and show that it successfully identifies biased labels and outperforms competing approaches.
Learning Complementary Policies for Human-AI Teams
Feb 06, 2023

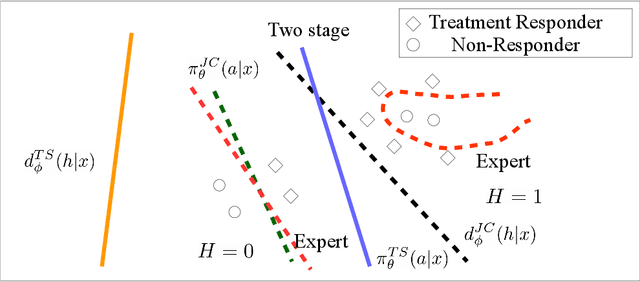
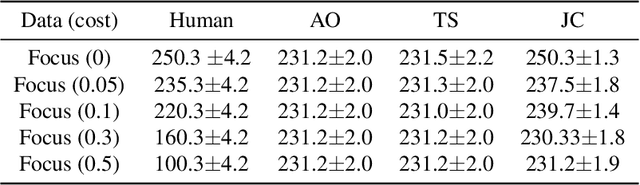
Human-AI complementarity is important when neither the algorithm nor the human yields dominant performance across all instances in a given context. Recent work that explored human-AI collaboration has considered decisions that correspond to classification tasks. However, in many important contexts where humans can benefit from AI complementarity, humans undertake course of action. In this paper, we propose a framework for a novel human-AI collaboration for selecting advantageous course of action, which we refer to as Learning Complementary Policy for Human-AI teams (\textsc{lcp-hai}). Our solution aims to exploit the human-AI complementarity to maximize decision rewards by learning both an algorithmic policy that aims to complement humans by a routing model that defers decisions to either a human or the AI to leverage the resulting complementarity. We then extend our approach to leverage opportunities and mitigate risks that arise in important contexts in practice: 1) when a team is composed of multiple humans with differential and potentially complementary abilities, 2) when the observational data includes consistent deterministic actions, and 3) when the covariate distribution of future decisions differ from that in the historical data. We demonstrate the effectiveness of our proposed methods using data on real human responses and semi-synthetic, and find that our methods offer reliable and advantageous performance across setting, and that it is superior to when either the algorithm or the AI make decisions on their own. We also find that the extensions we propose effectively improve the robustness of the human-AI collaboration performance in the presence of different challenging settings.
Learning to Advise Humans By Leveraging Algorithm Discretion
Oct 26, 2022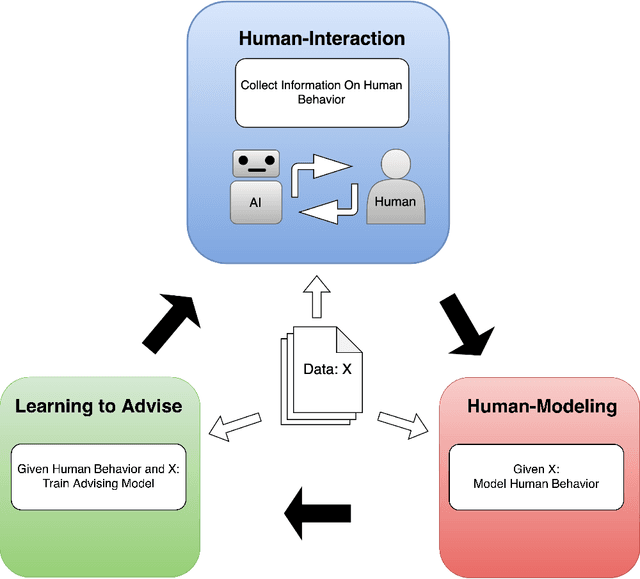
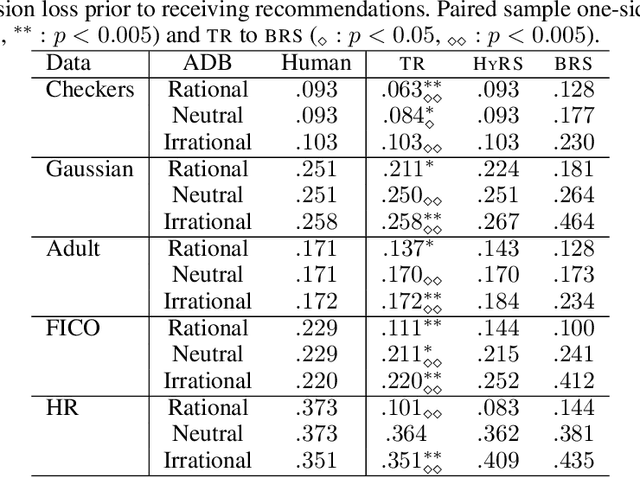

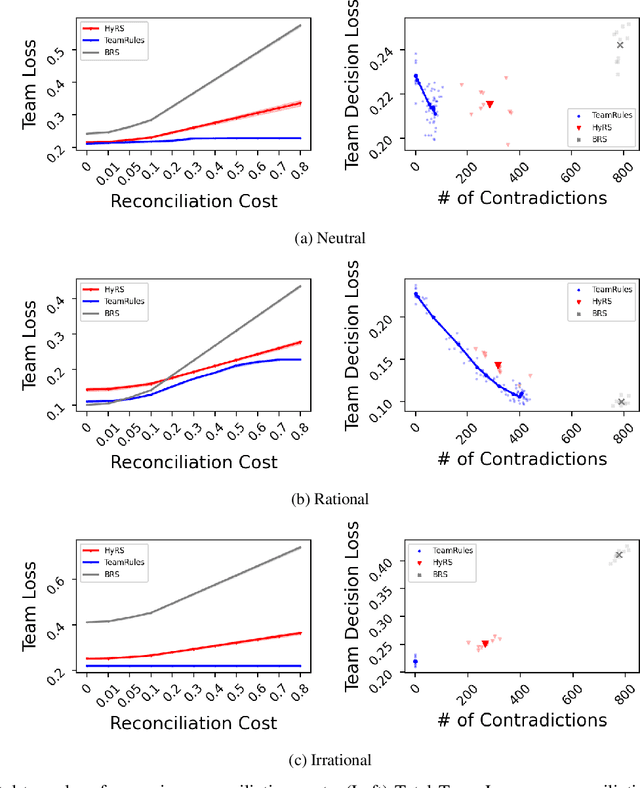
Expert decision-makers (DMs) in high-stakes AI-advised (AIDeT) settings receive and reconcile recommendations from AI systems before making their final decisions. We identify distinct properties of these settings which are key to developing AIDeT models that effectively benefit team performance. First, DMs in AIDeT settings exhibit algorithm discretion behavior (ADB), i.e., an idiosyncratic tendency to imperfectly accept or reject algorithmic recommendations for any given decision task. Second, DMs incur contradiction costs from exerting decision-making resources (e.g., time and effort) when reconciling AI recommendations that contradict their own judgment. Third, the human's imperfect discretion and reconciliation costs introduce the need for the AI to offer advice selectively. We refer to the task of developing AI to advise humans in AIDeT settings as learning to advise and we address this task by first introducing the AIDeT-Learning Framework. Additionally, we argue that leveraging the human partner's ADB is key to maximizing the AIDeT's decision accuracy while regularizing for contradiction costs. Finally, we instantiate our framework to develop TeamRules (TR): an algorithm that produces rule-based models and recommendations for AIDeT settings. TR is optimized to selectively advise a human and to trade-off contradiction costs and team accuracy for a given environment by leveraging the human partner's ADB. Evaluations on synthetic and real-world benchmark datasets with a variety of simulated human accuracy and discretion behaviors show that TR robustly improves the team's objective across settings over interpretable, rule-based alternatives.
Algorithmic Fairness in Business Analytics: Directions for Research and Practice
Jul 22, 2022

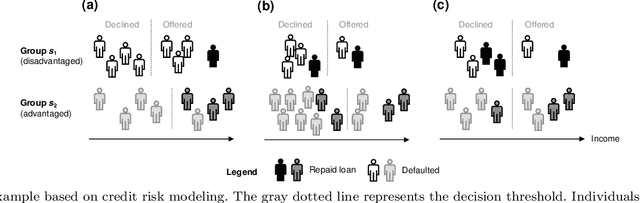
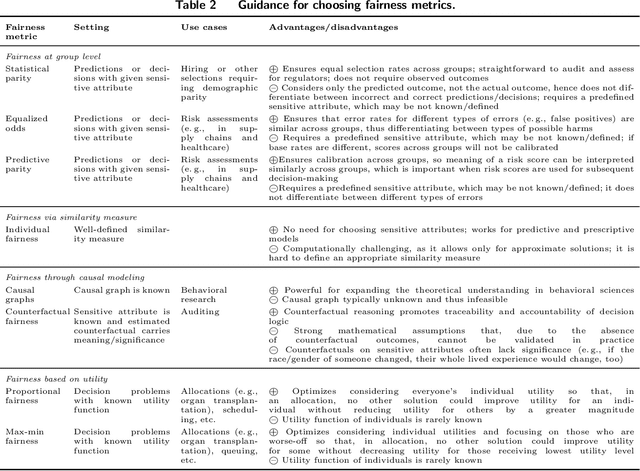
The extensive adoption of business analytics (BA) has brought financial gains and increased efficiencies. However, these advances have simultaneously drawn attention to rising legal and ethical challenges when BA inform decisions with fairness implications. As a response to these concerns, the emerging study of algorithmic fairness deals with algorithmic outputs that may result in disparate outcomes or other forms of injustices for subgroups of the population, especially those who have been historically marginalized. Fairness is relevant on the basis of legal compliance, social responsibility, and utility; if not adequately and systematically addressed, unfair BA systems may lead to societal harms and may also threaten an organization's own survival, its competitiveness, and overall performance. This paper offers a forward-looking, BA-focused review of algorithmic fairness. We first review the state-of-the-art research on sources and measures of bias, as well as bias mitigation algorithms. We then provide a detailed discussion of the utility-fairness relationship, emphasizing that the frequent assumption of a trade-off between these two constructs is often mistaken or short-sighted. Finally, we chart a path forward by identifying opportunities for business scholars to address impactful, open challenges that are key to the effective and responsible deployment of BA.
More Data Can Lead Us Astray: Active Data Acquisition in the Presence of Label Bias
Jul 15, 2022

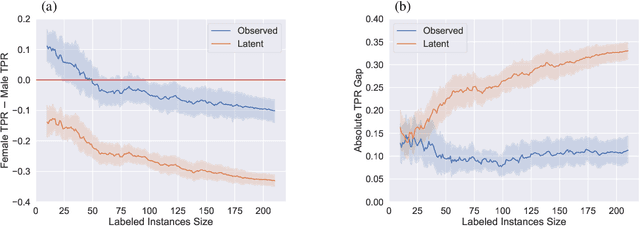
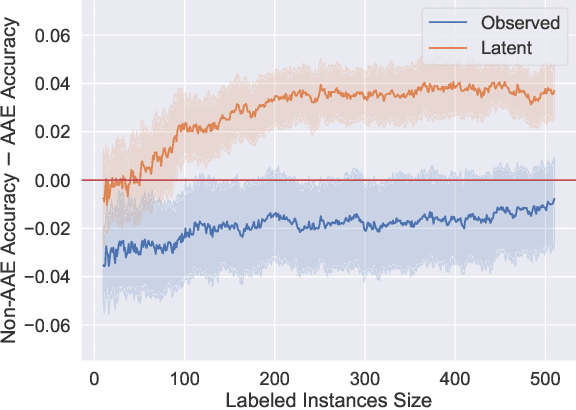
An increased awareness concerning risks of algorithmic bias has driven a surge of efforts around bias mitigation strategies. A vast majority of the proposed approaches fall under one of two categories: (1) imposing algorithmic fairness constraints on predictive models, and (2) collecting additional training samples. Most recently and at the intersection of these two categories, methods that propose active learning under fairness constraints have been developed. However, proposed bias mitigation strategies typically overlook the bias presented in the observed labels. In this work, we study fairness considerations of active data collection strategies in the presence of label bias. We first present an overview of different types of label bias in the context of supervised learning systems. We then empirically show that, when overlooking label bias, collecting more data can aggravate bias, and imposing fairness constraints that rely on the observed labels in the data collection process may not address the problem. Our results illustrate the unintended consequences of deploying a model that attempts to mitigate a single type of bias while neglecting others, emphasizing the importance of explicitly differentiating between the types of bias that fairness-aware algorithms aim to address, and highlighting the risks of neglecting label bias during data collection.