 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Machine Bias To Measure Human Bias
Dec 10, 2024

Biased human decisions have consequential impacts across various domains, yielding unfair treatment of individuals and resulting in suboptimal outcomes for organizations and society. In recognition of this fact, organizations regularly design and deploy interventions aimed at mitigating these biases. However, measuring human decision biases remains an important but elusive task. Organizations are frequently concerned with mistaken decisions disproportionately affecting one group. In practice, however, this is typically not possible to assess due to the scarcity of a gold standard: a label that indicates what the correct decision would have been. In this work, we propose a machine learning-based framework to assess bias in human-generated decisions when gold standard labels are scarce. We provide theoretical guarantees and empirical evidence demonstrating the superiority of our method over existing alternatives. This proposed methodology establishes a foundation for transparency in human decision-making, carrying substantial implications for managerial duties, and offering potential for alleviating algorithmic biases when human decisions are used as labels to train algorithms.
Fighting Bias with Bias: A Machine Learning Approach to Assess Human Bias
Dec 02, 2024Biased human decisions have consequential impacts across various domains, yielding unfair treatment of individuals and resulting in suboptimal outcomes for organizations and society. In recognition of this fact, organizations regularly design and deploy interventions aimed at mitigating these biases. However, measuring human decision biases remains an important but elusive task. Organizations are frequently concerned with mistaken decisions disproportionately affecting one group. In practice, however, this is typically not possible to assess due to the scarcity of a gold standard: a label that indicates what the correct decision would have been. In this work, we propose a machine learning-based framework to assess bias in human-generated decisions when gold standard labels are scarce. We provide theoretical guarantees and empirical evidence demonstrating the superiority of our method over existing alternatives. This proposed methodology establishes a foundation for transparency in human decision-making, carrying substantial implications for managerial duties, and offering potential for alleviating algorithmic biases when human decisions are used as labels to train algorithms.
A Machine Learning Framework Towards Transparency in Experts' Decision Quality
Oct 21, 2021
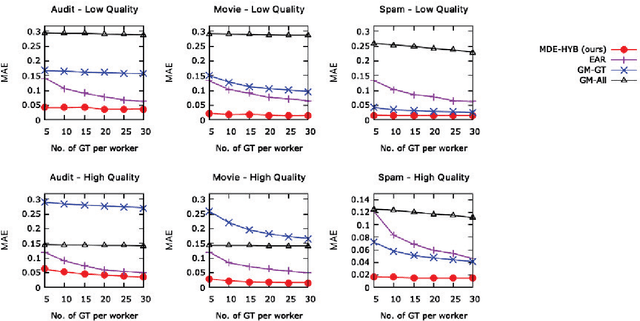
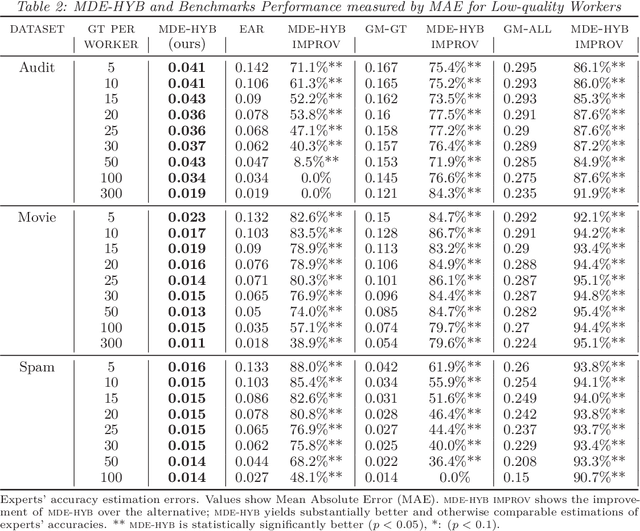

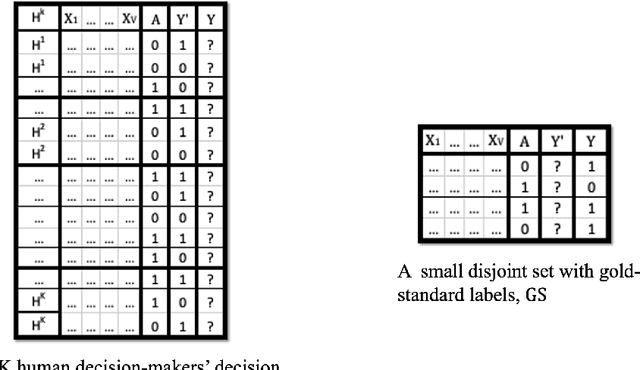
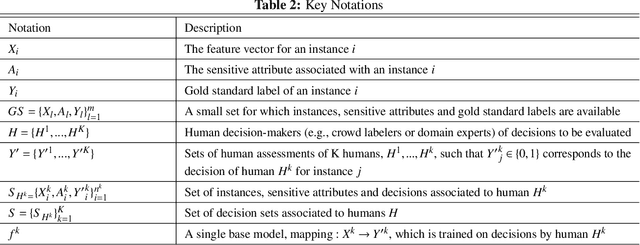
Expert workers make non-trivial decisions with significant implications. Experts' decision accuracy is thus a fundamental aspect of their judgment quality, key to both management and consumers of experts' services. Yet, in many important settings, transparency in experts' decision quality is rarely possible because ground truth data for evaluating the experts' decisions is costly and available only for a limited set of decisions. Furthermore, different experts typically handle exclusive sets of decisions, and thus prior solutions that rely on the aggregation of multiple experts' decisions for the same instance are inapplicable. We first formulate the problem of estimating experts' decision accuracy in this setting and then develop a machine-learning-based framework to address it. Our method effectively leverages both abundant historical data on workers' past decisions, and scarce decision instances with ground truth information. We conduct extensive empirical evaluations of our method's performance relative to alternatives using both semi-synthetic data based on publicly available datasets, and purposefully compiled dataset on real workers' decisions. The results show that our approach is superior to existing alternatives across diverse settings, including different data domains, experts' qualities, and the amount of ground truth data. To our knowledge, this paper is the first to posit and address the problem of estimating experts' decision accuracies from historical data with scarcely available ground truth, and it is the first to offer comprehensive results for this problem setting, establishing the performances that can be achieved across settings, as well as the state-of-the-art performance on which future work can build.