 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning over Precedents Alongside Statutes: Case-Augmented Deliberative Alignment for LLM Safety
Jan 12, 2026Ensuring that Large Language Models (LLMs) adhere to safety principles without refusing benign requests remains a significant challenge. While OpenAI introduces deliberative alignment (DA) to enhance the safety of its o-series models through reasoning over detailed ``code-like'' safety rules, the effectiveness of this approach in open-source LLMs, which typically lack advanced reasoning capabilities, is understudied. In this work, we systematically evaluate the impact of explicitly specifying extensive safety codes versus demonstrating them through illustrative cases. We find that referencing explicit codes inconsistently improves harmlessness and systematically degrades helpfulness, whereas training on case-augmented simple codes yields more robust and generalized safety behaviors. By guiding LLMs with case-augmented reasoning instead of extensive code-like safety rules, we avoid rigid adherence to narrowly enumerated rules and enable broader adaptability. Building on these insights, we propose CADA, a case-augmented deliberative alignment method for LLMs utilizing reinforcement learning on self-generated safety reasoning chains. CADA effectively enhances harmlessness, improves robustness against attacks, and reduces over-refusal while preserving utility across diverse benchmarks, offering a practical alternative to rule-only DA for improving safety while maintaining helpfulness.
Your Reward Function for RL is Your Best PRM for Search: Unifying RL and Search-Based TTS
Aug 19, 2025Test-time scaling (TTS) for large language models (LLMs) has thus far fallen into two largely separate paradigms: (1) reinforcement learning (RL) methods that optimize sparse outcome-based rewards, yet suffer from instability and low sample efficiency; and (2) search-based techniques guided by independently trained, static process reward models (PRMs), which require expensive human- or LLM-generated labels and often degrade under distribution shifts. In this paper, we introduce AIRL-S, the first natural unification of RL-based and search-based TTS. Central to AIRL-S is the insight that the reward function learned during RL training inherently represents the ideal PRM for guiding downstream search. Specifically, we leverage adversarial inverse reinforcement learning (AIRL) combined with group relative policy optimization (GRPO) to learn a dense, dynamic PRM directly from correct reasoning traces, entirely eliminating the need for labeled intermediate process data. At inference, the resulting PRM simultaneously serves as the critic for RL rollouts and as a heuristic to effectively guide search procedures, facilitating robust reasoning chain extension, mitigating reward hacking, and enhancing cross-task generalization. Experimental results across eight benchmarks, including mathematics, scientific reasoning, and code generation, demonstrate that our unified approach improves performance by 9 % on average over the base model, matching GPT-4o. Furthermore, when integrated into multiple search algorithms, our PRM consistently outperforms all baseline PRMs trained with labeled data. These results underscore that, indeed, your reward function for RL is your best PRM for search, providing a robust and cost-effective solution to complex reasoning tasks in LLMs.
CATP: Contextually Adaptive Token Pruning for Efficient and Enhanced Multimodal In-Context Learning
Aug 11, 2025Modern large vision-language models (LVLMs) convert each input image into a large set of tokens, far outnumbering the text tokens. Although this improves visual perception, it introduces severe image token redundancy. Because image tokens carry sparse information, many add little to reasoning, yet greatly increase inference cost. The emerging image token pruning methods tackle this issue by identifying the most important tokens and discarding the rest. These methods can raise efficiency with only modest performance loss. However, most of them only consider single-image tasks and overlook multimodal in-context learning (ICL), where redundancy is greater and efficiency is more critical. Redundant tokens weaken the advantage of multimodal ICL for rapid domain adaptation and cause unstable performance. Applying existing pruning methods in this setting leads to large accuracy drops, exposing a clear gap and the need for new techniques. Thus, we propose Contextually Adaptive Token Pruning (CATP), a training-free pruning method targeted at multimodal ICL. CATP consists of two stages that perform progressive pruning to fully account for the complex cross-modal interactions in the input sequence. After removing 77.8\% of the image tokens, CATP produces an average performance gain of 0.6\% over the vanilla model on four LVLMs and eight benchmarks, exceeding all baselines remarkably. Meanwhile, it effectively improves efficiency by achieving an average reduction of 10.78\% in inference latency. CATP enhances the practical value of multimodal ICL and lays the groundwork for future progress in interleaved image-text scenarios.
Token-Level Uncertainty Estimation for Large Language Model Reasoning
May 16, 2025While Large Language Models (LLMs) have demonstrated impressive capabilities, their output quality remains inconsistent across various application scenarios, making it difficult to identify trustworthy responses, especially in complex tasks requiring multi-step reasoning. In this paper, we propose a token-level uncertainty estimation framework to enable LLMs to self-assess and self-improve their generation quality in mathematical reasoning. Specifically, we introduce low-rank random weight perturbation to LLM decoding, generating predictive distributions that we use to estimate token-level uncertainties. We then aggregate these uncertainties to reflect semantic uncertainty of the generated sequences. Experiments on mathematical reasoning datasets of varying difficulty demonstrate that our token-level uncertainty metrics strongly correlate with answer correctness and model robustness. Additionally, we explore using uncertainty to directly enhance the model's reasoning performance through multiple generations and the particle filtering algorithm. Our approach consistently outperforms existing uncertainty estimation methods, establishing effective uncertainty estimation as a valuable tool for both evaluating and improving reasoning generation in LLMs.
Sculpting Subspaces: Constrained Full Fine-Tuning in LLMs for Continual Learning
Apr 09, 2025Continual learning in large language models (LLMs) is prone to catastrophic forgetting, where adapting to new tasks significantly degrades performance on previously learned ones. Existing methods typically rely on low-rank, parameter-efficient updates that limit the model's expressivity and introduce additional parameters per task, leading to scalability issues. To address these limitations, we propose a novel continual full fine-tuning approach leveraging adaptive singular value decomposition (SVD). Our method dynamically identifies task-specific low-rank parameter subspaces and constrains updates to be orthogonal to critical directions associated with prior tasks, thus effectively minimizing interference without additional parameter overhead or storing previous task gradients. We evaluate our approach extensively on standard continual learning benchmarks using both encoder-decoder (T5-Large) and decoder-only (LLaMA-2 7B) models, spanning diverse tasks including classification, generation, and reasoning. Empirically, our method achieves state-of-the-art results, up to 7% higher average accuracy than recent baselines like O-LoRA, and notably maintains the model's general linguistic capabilities, instruction-following accuracy, and safety throughout the continual learning process by reducing forgetting to near-negligible levels. Our adaptive SVD framework effectively balances model plasticity and knowledge retention, providing a practical, theoretically grounded, and computationally scalable solution for continual learning scenarios in large language models.
SQuat: Subspace-orthogonal KV Cache Quantization
Mar 31, 2025The key-value (KV) cache accelerates LLMs decoding by storing KV tensors from previously generated tokens. It reduces redundant computation at the cost of increased memory usage. To mitigate this overhead, existing approaches compress KV tensors into lower-bit representations; however, quantization errors can accumulate as more tokens are generated, potentially resulting in undesired outputs. In this paper, we introduce SQuat (Subspace-orthogonal KV cache quantization). It first constructs a subspace spanned by query tensors to capture the most critical task-related information. During key tensor quantization, it enforces that the difference between the (de)quantized and original keys remains orthogonal to this subspace, minimizing the impact of quantization errors on the attention mechanism's outputs. SQuat requires no model fine-tuning, no additional calibration dataset for offline learning, and is grounded in a theoretical framework we develop. Through numerical experiments, we show that our method reduces peak memory by 2.17 to 2.82, improves throughput by 2.45 to 3.60, and achieves more favorable benchmark scores than existing KV cache quantization algorithms.
Can Large Vision-Language Models Detect Images Copyright Infringement from GenAI?
Feb 23, 2025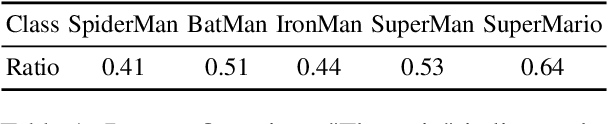


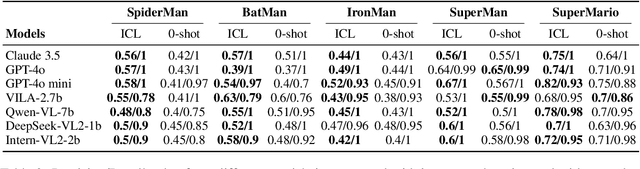
Generative AI models, renowned for their ability to synthesize high-quality content, have sparked growing concerns over the improper generation of copyright-protected material. While recent studies have proposed various approaches to address copyright issues, the capability of large vision-language models (LVLMs) to detect copyright infringements remains largely unexplored. In this work, we focus on evaluating the copyright detection abilities of state-of-the-art LVLMs using a various set of image samples. Recognizing the absence of a comprehensive dataset that includes both IP-infringement samples and ambiguous non-infringement negative samples, we construct a benchmark dataset comprising positive samples that violate the copyright protection of well-known IP figures, as well as negative samples that resemble these figures but do not raise copyright concerns. This dataset is created using advanced prompt engineering techniques. We then evaluate leading LVLMs using our benchmark dataset. Our experimental results reveal that LVLMs are prone to overfitting, leading to the misclassification of some negative samples as IP-infringement cases. In the final section, we analyze these failure cases and propose potential solutions to mitigate the overfitting problem.
LoR-VP: Low-Rank Visual Prompting for Efficient Vision Model Adaptation
Feb 04, 2025Visual prompting has gained popularity as a method for adapting pre-trained models to specific tasks, particularly in the realm of parameter-efficient tuning. However, existing visual prompting techniques often pad the prompt parameters around the image, limiting the interaction between the visual prompts and the original image to a small set of patches while neglecting the inductive bias present in shared information across different patches. In this study, we conduct a thorough preliminary investigation to identify and address these limitations. We propose a novel visual prompt design, introducing Low-Rank matrix multiplication for Visual Prompting (LoR-VP), which enables shared and patch-specific information across rows and columns of image pixels. Extensive experiments across seven network architectures and four datasets demonstrate significant improvements in both performance and efficiency compared to state-of-the-art visual prompting methods, achieving up to 6 times faster training times, utilizing 18 times fewer visual prompt parameters, and delivering a 3.1% improvement in performance. The code is available as https://github.com/jincan333/LoR-VP.
Rate-My-LoRA: Efficient and Adaptive Federated Model Tuning for Cardiac MRI Segmentation
Jan 06, 2025Cardiovascular disease (CVD) and cardiac dyssynchrony are major public health problems in the United States. Precise cardiac image segmentation is crucial for extracting quantitative measures that help categorize cardiac dyssynchrony. However, achieving high accuracy often depends on centralizing large datasets from different hospitals, which can be challenging due to privacy concerns. To solve this problem, Federated Learning (FL) is proposed to enable decentralized model training on such data without exchanging sensitive information. However, bandwidth limitations and data heterogeneity remain as significant challenges in conventional FL algorithms. In this paper, we propose a novel efficient and adaptive federate learning method for cardiac segmentation that improves model performance while reducing the bandwidth requirement. Our method leverages the low-rank adaptation (LoRA) to regularize model weight update and reduce communication overhead. We also propose a \mymethod{} aggregation technique to address data heterogeneity among clients. This technique adaptively penalizes the aggregated weights from different clients by comparing the validation accuracy in each client, allowing better generalization performance and fast local adaptation. In-client and cross-client evaluations on public cardiac MR datasets demonstrate the superiority of our method over other LoRA-based federate learning approaches.
MLLM-as-a-Judge for Image Safety without Human Labeling
Dec 31, 2024



Image content safety has become a significant challenge with the rise of visual media on online platforms. Meanwhile, in the age of AI-generated content (AIGC), many image generation models are capable of producing harmful content, such as images containing sexual or violent material. Thus, it becomes crucial to identify such unsafe images based on established safety rules. Pre-trained Multimodal Large Language Models (MLLMs) offer potential in this regard, given their strong pattern recognition abilities. Existing approaches typically fine-tune MLLMs with human-labeled datasets, which however brings a series of drawbacks. First, relying on human annotators to label data following intricate and detailed guidelines is both expensive and labor-intensive. Furthermore, users of safety judgment systems may need to frequently update safety rules, making fine-tuning on human-based annotation more challenging. This raises the research question: Can we detect unsafe images by querying MLLMs in a zero-shot setting using a predefined safety constitution (a set of safety rules)? Our research showed that simply querying pre-trained MLLMs does not yield satisfactory results. This lack of effectiveness stems from factors such as the subjectivity of safety rules, the complexity of lengthy constitutions, and the inherent biases in the models. To address these challenges, we propose a MLLM-based method includes objectifying safety rules, assessing the relevance between rules and images, making quick judgments based on debiased token probabilities with logically complete yet simplified precondition chains for safety rules, and conducting more in-depth reasoning with cascaded chain-of-thought processes if necessary. Experiment results demonstrate that our method is highly effective for zero-shot image safety judgment tasks.