 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairPO: Robust Preference Optimization for Fair Multi-Label Learning
May 05, 2025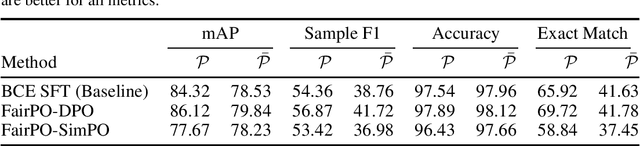

We propose FairPO, a novel framework designed to promote fairness in multi-label classification by directly optimizing preference signals with a group robustness perspective. In our framework, the set of labels is partitioned into privileged and non-privileged groups, and a preference-based loss inspired by Direct Preference Optimization (DPO) is employed to more effectively differentiate true positive labels from confusing negatives within the privileged group, while preserving baseline classification performance for non-privileged labels. By framing the learning problem as a robust optimization over groups, our approach dynamically adjusts the training emphasis toward groups with poorer performance, thereby mitigating bias and ensuring a fairer treatment across diverse label categories. In addition, we outline plans to extend this approach by investigating alternative loss formulations such as Simple Preference Optimisation (SimPO) and Contrastive Preference Optimization (CPO) to exploit reference-free reward formulations and contrastive training signals. Furthermore, we plan to extend FairPO with multilabel generation capabilities, enabling the model to dynamically generate diverse and coherent label sets for ambiguous inputs.
Early Exit and Multi Stage Knowledge Distillation in VLMs for Video Summarization
Apr 30, 2025We introduce DEEVISum (Distilled Early Exit Vision language model for Summarization), a lightweight, efficient, and scalable vision language model designed for segment wise video summarization. Leveraging multi modal prompts that combine textual and audio derived signals, DEEVISum incorporates Multi Stage Knowledge Distillation (MSKD) and Early Exit (EE) to strike a balance between performance and efficiency. MSKD offers a 1.33% absolute F1 improvement over baseline distillation (0.5%), while EE reduces inference time by approximately 21% with a 1.3 point drop in F1. Evaluated on the TVSum dataset, our best model PaLI Gemma2 3B + MSKD achieves an F1 score of 61.1, competing the performance of significantly larger models, all while maintaining a lower computational footprint. We publicly release our code and processed dataset to support further research.
Sculpting Subspaces: Constrained Full Fine-Tuning in LLMs for Continual Learning
Apr 09, 2025Continual learning in large language models (LLMs) is prone to catastrophic forgetting, where adapting to new tasks significantly degrades performance on previously learned ones. Existing methods typically rely on low-rank, parameter-efficient updates that limit the model's expressivity and introduce additional parameters per task, leading to scalability issues. To address these limitations, we propose a novel continual full fine-tuning approach leveraging adaptive singular value decomposition (SVD). Our method dynamically identifies task-specific low-rank parameter subspaces and constrains updates to be orthogonal to critical directions associated with prior tasks, thus effectively minimizing interference without additional parameter overhead or storing previous task gradients. We evaluate our approach extensively on standard continual learning benchmarks using both encoder-decoder (T5-Large) and decoder-only (LLaMA-2 7B) models, spanning diverse tasks including classification, generation, and reasoning. Empirically, our method achieves state-of-the-art results, up to 7% higher average accuracy than recent baselines like O-LoRA, and notably maintains the model's general linguistic capabilities, instruction-following accuracy, and safety throughout the continual learning process by reducing forgetting to near-negligible levels. Our adaptive SVD framework effectively balances model plasticity and knowledge retention, providing a practical, theoretically grounded, and computationally scalable solution for continual learning scenarios in large language models.
Few shot chain-of-thought driven reasoning to prompt LLMs for open ended medical question answering
Mar 07, 2024



Large Language models (LLMs) have demonstrated significant potential in transforming healthcare by automating tasks such as clinical documentation, information retrieval, and decision support. In this aspect, carefully engineered prompts have emerged as a powerful tool for using LLMs for medical scenarios, e.g., patient clinical scenarios. In this paper, we propose a modified version of the MedQA-USMLE dataset, which is subjective, to mimic real-life clinical scenarios. We explore the Chain of Thought (CoT) reasoning based on subjective response generation for the modified MedQA-USMLE dataset with appropriate LM-driven forward reasoning for correct responses to the medical questions. Keeping in mind the importance of response verification in the medical setting, we utilize a reward training mechanism whereby the language model also provides an appropriate verified response for a particular response to a clinical question. In this regard, we also include human-in-the-loop for different evaluation aspects. We develop better in-contrast learning strategies by modifying the 5-shot-codex-CoT-prompt from arXiv:2207.08143 for the subjective MedQA dataset and developing our incremental-reasoning prompt. Our evaluations show that the incremental reasoning prompt performs better than the modified codex prompt in certain scenarios. We also show that greedy decoding with the incremental reasoning method performs better than other strategies, such as prompt chaining and eliminative reasoning.