 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMK > CLS: Landmark Pooling for Dense Embeddings
Jan 29, 2026Representation learning is central to many downstream tasks such as search, clustering, classification, and reranking. State-of-the-art sequence encoders typically collapse a variable-length token sequence to a single vector using a pooling operator, most commonly a special [CLS] token or mean pooling over token embeddings. In this paper, we identify systematic weaknesses of these pooling strategies: [CLS] tends to concentrate information toward the initial positions of the sequence and can under-represent distributed evidence, while mean pooling can dilute salient local signals, sometimes leading to worse short-context performance. To address these issues, we introduce Landmark (LMK) pooling, which partitions a sequence into chunks, inserts landmark tokens between chunks, and forms the final representation by mean-pooling the landmark token embeddings. This simple mechanism improves long-context extrapolation without sacrificing local salient features, at the cost of introducing a small number of special tokens. We empirically demonstrate that LMK pooling matches existing methods on short-context retrieval tasks and yields substantial improvements on long-context tasks, making it a practical and scalable alternative to existing pooling methods.
Systematic Knowledge Injection into Large Language Models via Diverse Augmentation for Domain-Specific RAG
Feb 12, 2025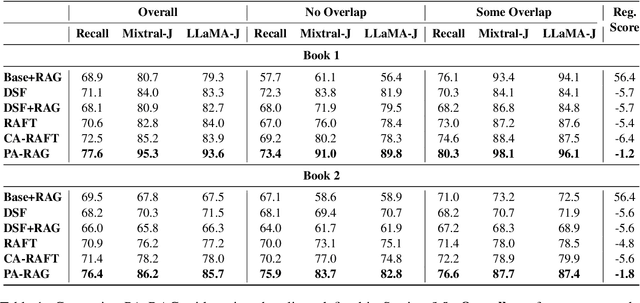

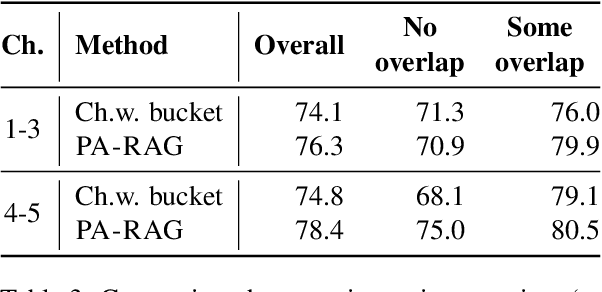
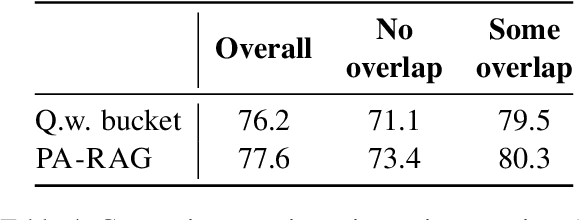
Retrieval-Augmented Generation (RAG) has emerged as a prominent method for incorporating domain knowledge into Large Language Models (LLMs). While RAG enhances response relevance by incorporating retrieved domain knowledge in the context, retrieval errors can still lead to hallucinations and incorrect answers. To recover from retriever failures, domain knowledge is injected by fine-tuning the model to generate the correct response, even in the case of retrieval errors. However, we observe that without systematic knowledge augmentation, fine-tuned LLMs may memorize new information but still fail to extract relevant domain knowledge, leading to poor performance. In this work, we present a novel framework that significantly enhances the fine-tuning process by augmenting the training data in two ways -- context augmentation and knowledge paraphrasing. In context augmentation, we create multiple training samples for a given QA pair by varying the relevance of the retrieved information, teaching the model when to ignore and when to rely on retrieved content. In knowledge paraphrasing, we fine-tune with multiple answers to the same question, enabling LLMs to better internalize specialized knowledge. To mitigate catastrophic forgetting due to fine-tuning, we add a domain-specific identifier to a question and also utilize a replay buffer containing general QA pairs. Experimental results demonstrate the efficacy of our method over existing techniques, achieving up to 10\% relative gain in token-level recall while preserving the LLM's generalization capabilities.
Selective Self-to-Supervised Fine-Tuning for Generalization in Large Language Models
Feb 12, 2025Fine-tuning Large Language Models (LLMs) on specific datasets is a common practice to improve performance on target tasks. However, this performance gain often leads to overfitting, where the model becomes too specialized in either the task or the characteristics of the training data, resulting in a loss of generalization. This paper introduces Selective Self-to-Supervised Fine-Tuning (S3FT), a fine-tuning approach that achieves better performance than the standard supervised fine-tuning (SFT) while improving generalization. S3FT leverages the existence of multiple valid responses to a query. By utilizing the model's correct responses, S3FT reduces model specialization during the fine-tuning stage. S3FT first identifies the correct model responses from the training set by deploying an appropriate judge. Then, it fine-tunes the model using the correct model responses and the gold response (or its paraphrase) for the remaining samples. The effectiveness of S3FT is demonstrated through experiments on mathematical reasoning, Python programming and reading comprehension tasks. The results show that standard SFT can lead to an average performance drop of up to $4.4$ on multiple benchmarks, such as MMLU and TruthfulQA. In contrast, S3FT reduces this drop by half, i.e. $2.5$, indicating better generalization capabilities than SFT while performing significantly better on the fine-tuning tasks.
Selective Self-Rehearsal: A Fine-Tuning Approach to Improve Generalization in Large Language Models
Sep 07, 2024
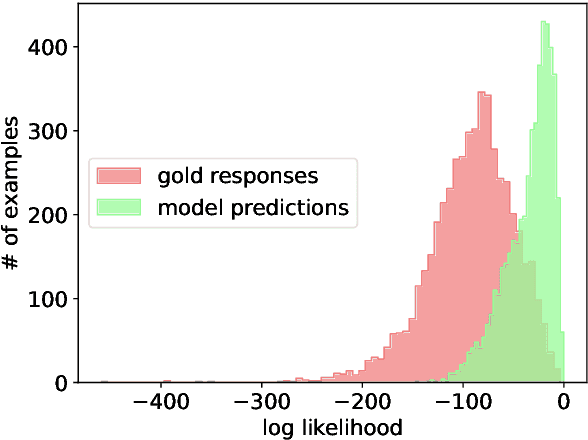
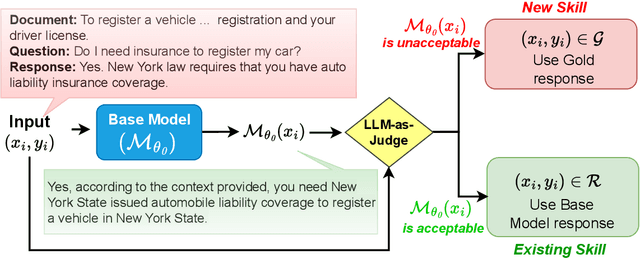
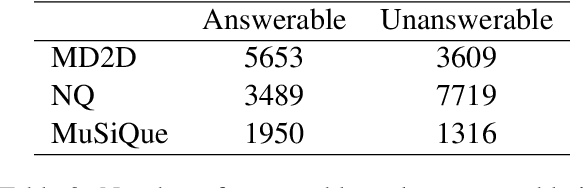
Fine-tuning Large Language Models (LLMs) on specific datasets is a common practice to improve performance on target tasks. However, this performance gain often leads to overfitting, where the model becomes too specialized in either the task or the characteristics of the training data, resulting in a loss of generalization. This paper introduces Selective Self-Rehearsal (SSR), a fine-tuning approach that achieves performance comparable to the standard supervised fine-tuning (SFT) while improving generalization. SSR leverages the fact that there can be multiple valid responses to a query. By utilizing the model's correct responses, SSR reduces model specialization during the fine-tuning stage. SSR first identifies the correct model responses from the training set by deploying an appropriate LLM as a judge. Then, it fine-tunes the model using the correct model responses and the gold response for the remaining samples. The effectiveness of SSR is demonstrated through experiments on the task of identifying unanswerable queries across various datasets. The results show that standard SFT can lead to an average performance drop of up to $16.7\%$ on multiple benchmarks, such as MMLU and TruthfulQA. In contrast, SSR results in close to $2\%$ drop on average, indicating better generalization capabilities compared to standard SFT.
An Approach to Build Zero-Shot Slot-Filling System for Industry-Grade Conversational Assistants
Jun 13, 2024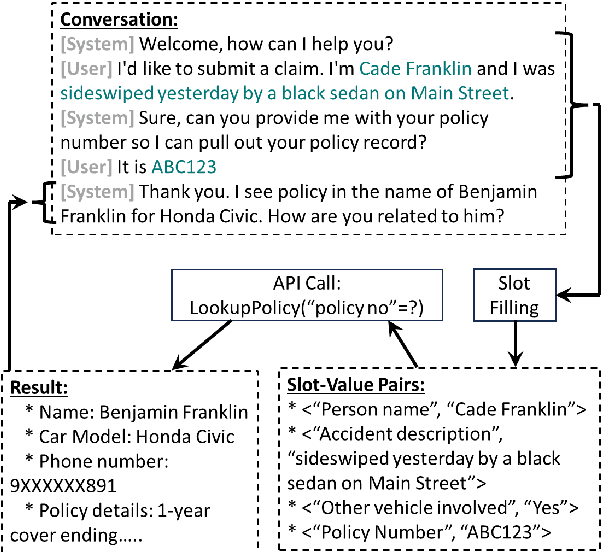
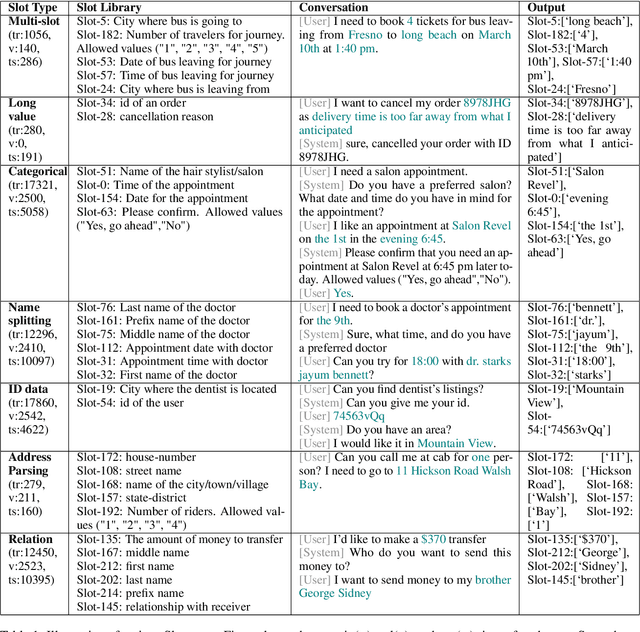
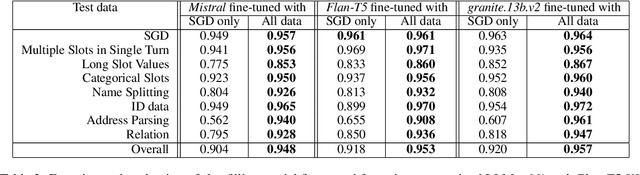

We present an approach to build Large Language Model (LLM) based slot-filling system to perform Dialogue State Tracking in conversational assistants serving across a wide variety of industry-grade applications. Key requirements of this system include: 1) usage of smaller-sized models to meet low latency requirements and to enable convenient and cost-effective cloud and customer premise deployments, and 2) zero-shot capabilities to serve across a wide variety of domains, slot types and conversational scenarios. We adopt a fine-tuning approach where a pre-trained LLM is fine-tuned into a slot-filling model using task specific data. The fine-tuning data is prepared carefully to cover a wide variety of slot-filling task scenarios that the model is expected to face across various domains. We give details of the data preparation and model building process. We also give a detailed analysis of the results of our experimental evaluations. Results show that our prescribed approach for slot-filling model building has resulted in 6.9% relative improvement of F1 metric over the best baseline on a realistic benchmark, while at the same time reducing the latency by 57%. More over, the data we prepared has helped improve F1 on an average by 4.2% relative across various slot-types.
Few shot chain-of-thought driven reasoning to prompt LLMs for open ended medical question answering
Mar 07, 2024



Large Language models (LLMs) have demonstrated significant potential in transforming healthcare by automating tasks such as clinical documentation, information retrieval, and decision support. In this aspect, carefully engineered prompts have emerged as a powerful tool for using LLMs for medical scenarios, e.g., patient clinical scenarios. In this paper, we propose a modified version of the MedQA-USMLE dataset, which is subjective, to mimic real-life clinical scenarios. We explore the Chain of Thought (CoT) reasoning based on subjective response generation for the modified MedQA-USMLE dataset with appropriate LM-driven forward reasoning for correct responses to the medical questions. Keeping in mind the importance of response verification in the medical setting, we utilize a reward training mechanism whereby the language model also provides an appropriate verified response for a particular response to a clinical question. In this regard, we also include human-in-the-loop for different evaluation aspects. We develop better in-contrast learning strategies by modifying the 5-shot-codex-CoT-prompt from arXiv:2207.08143 for the subjective MedQA dataset and developing our incremental-reasoning prompt. Our evaluations show that the incremental reasoning prompt performs better than the modified codex prompt in certain scenarios. We also show that greedy decoding with the incremental reasoning method performs better than other strategies, such as prompt chaining and eliminative reasoning.
BRAIn: Bayesian Reward-conditioned Amortized Inference for natural language generation from feedback
Feb 04, 2024



Following the success of Proximal Policy Optimization (PPO) for Reinforcement Learning from Human Feedback (RLHF), new techniques such as Sequence Likelihood Calibration (SLiC) and Direct Policy Optimization (DPO) have been proposed that are offline in nature and use rewards in an indirect manner. These techniques, in particular DPO, have recently become the tools of choice for LLM alignment due to their scalability and performance. However, they leave behind important features of the PPO approach. Methods such as SLiC or RRHF make use of the Reward Model (RM) only for ranking/preference, losing fine-grained information and ignoring the parametric form of the RM (eg., Bradley-Terry, Plackett-Luce), while methods such as DPO do not use even a separate reward model. In this work, we propose a novel approach, named BRAIn, that re-introduces the RM as part of a distribution matching approach.BRAIn considers the LLM distribution conditioned on the assumption of output goodness and applies Bayes theorem to derive an intractable posterior distribution where the RM is explicitly represented. BRAIn then distills this posterior into an amortized inference network through self-normalized importance sampling, leading to a scalable offline algorithm that significantly outperforms prior art in summarization and AntropicHH tasks. BRAIn also has interesting connections to PPO and DPO for specific RM choices.
Evaluating Robustness of Dialogue Summarization Models in the Presence of Naturally Occurring Variations
Nov 15, 2023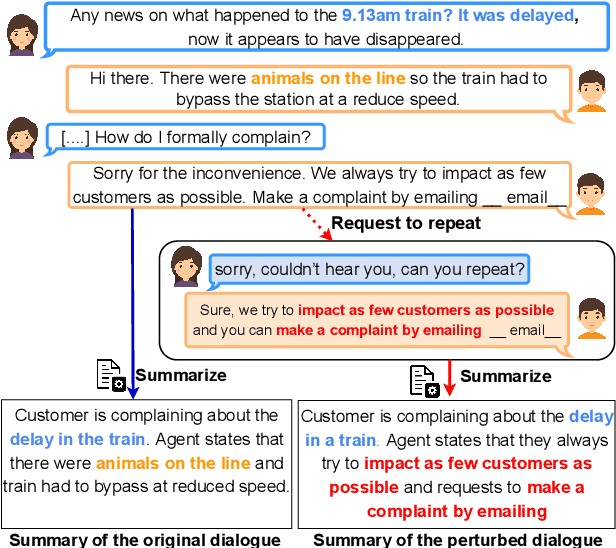
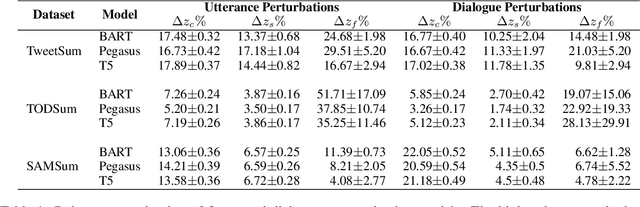
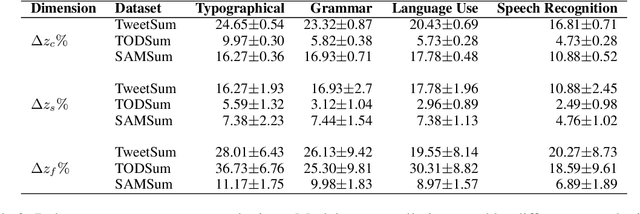
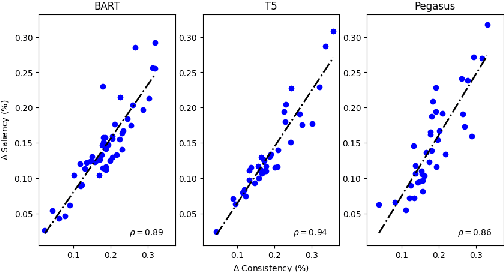
Dialogue summarization task involves summarizing long conversations while preserving the most salient information. Real-life dialogues often involve naturally occurring variations (e.g., repetitions, hesitations) and existing dialogue summarization models suffer from performance drop on such conversations. In this study, we systematically investigate the impact of such variations on state-of-the-art dialogue summarization models using publicly available datasets. To simulate real-life variations, we introduce two types of perturbations: utterance-level perturbations that modify individual utterances with errors and language variations, and dialogue-level perturbations that add non-informative exchanges (e.g., repetitions, greetings). We conduct our analysis along three dimensions of robustness: consistency, saliency, and faithfulness, which capture different aspects of the summarization model's performance. We find that both fine-tuned and instruction-tuned models are affected by input variations, with the latter being more susceptible, particularly to dialogue-level perturbations. We also validate our findings via human evaluation. Finally, we investigate if the robustness of fine-tuned models can be improved by training them with a fraction of perturbed data and observe that this approach is insufficient to address robustness challenges with current models and thus warrants a more thorough investigation to identify better solutions. Overall, our work highlights robustness challenges in dialogue summarization and provides insights for future research.
Evaluating Chatbots to Promote Users' Trust -- Practices and Open Problems
Sep 14, 2023Chatbots, the common moniker for collaborative assistants, are Artificial Intelligence (AI) software that enables people to naturally interact with them to get tasks done. Although chatbots have been studied since the dawn of AI, they have particularly caught the imagination of the public and businesses since the launch of easy-to-use and general-purpose Large Language Model-based chatbots like ChatGPT. As businesses look towards chatbots as a potential technology to engage users, who may be end customers, suppliers, or even their own employees, proper testing of chatbots is important to address and mitigate issues of trust related to service or product performance, user satisfaction and long-term unintended consequences for society. This paper reviews current practices for chatbot testing, identifies gaps as open problems in pursuit of user trust, and outlines a path forward.
Pointwise Mutual Information Based Metric and Decoding Strategy for Faithful Generation in Document Grounded Dialogs
May 20, 2023



A major concern in using deep learning based generative models for document-grounded dialogs is the potential generation of responses that are not \textit{faithful} to the underlying document. Existing automated metrics used for evaluating the faithfulness of response with respect to the grounding document measure the degree of similarity between the generated response and the document's content. However, these automated metrics are far from being well aligned with human judgments. Therefore, to improve the measurement of faithfulness, we propose a new metric that utilizes (Conditional) Point-wise Mutual Information (PMI) between the generated response and the source document, conditioned on the dialogue. PMI quantifies the extent to which the document influences the generated response -- with a higher PMI indicating a more faithful response. We build upon this idea to create a new decoding technique that incorporates PMI into the response generation process to predict more faithful responses. Our experiments on the BEGIN benchmark demonstrate an improved correlation of our metric with human evaluation. We also show that our decoding technique is effective in generating more faithful responses when compared to standard decoding techniques on a set of publicly available document-grounded dialog datasets.