 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliot: Interactively $\underline{E}$xploring Fast-Changing Scientific $\underline{Li}$terature Trends with $\underline{O}$nline Da$\underline{t}$a and Learning
May 26, 2026The rapid growth of scientific publishing has made it increasingly difficult to track how fast-moving areas evolve. Search engines and LLM-based assistants retrieve or summarize papers, but often hide how the corpus was selected, organized, or connected to temporal patterns. We present $\texttt{Eliot}$, a publicly deployed interactive system for traceable exploration of evolving scientific literature. Motivated by two studies on Large Language Models (LLMs) and Automated Planning and Scheduling (APS), $\texttt{Eliot}$ generalizes literature-evolution analysis beyond hand-built taxonomies and domain-specific scripts. Given explicit query terms and filters, it retrieves arXiv papers at query time, represents each paper by title and abstract, clusters the corpus into themes, assigns representative keywords, and visualizes each cluster's publication-year distribution. We evaluate $\texttt{Eliot}$ as both an applied system and an interactive research aid. An offline configuration study across eight arXiv domains compares document representations, dimensionality reduction methods, and clustering algorithms using intrinsic clustering and topic-coherence metrics; the results support MiniLM embeddings with 10-dimensional UMAP and Agglomerative Clustering as a practical default. A scenario-based survey and expert focus group assess interpretability and use contexts: participants rated cluster labels as meaningful in 85% of scenario responses, and feedback indicated that $\texttt{Eliot}$ is most valuable for auditable overviews of rapidly changing technical areas. These results suggest that query-time clustering and temporal inspection can complement search and generation tools by helping researchers inspect and refine the evidence behind literature trends.
On Sample-Efficient Generalized Planning via Learned Transition Models
Feb 26, 2026Generalized planning studies the construction of solution strategies that generalize across families of planning problems sharing a common domain model, formally defined by a transition function $γ: S \times A \rightarrow S$. Classical approaches achieve such generalization through symbolic abstractions and explicit reasoning over $γ$. In contrast, recent Transformer-based planners, such as PlanGPT and Plansformer, largely cast generalized planning as direct action-sequence prediction, bypassing explicit transition modeling. While effective on in-distribution instances, these approaches typically require large datasets and model sizes, and often suffer from state drift in long-horizon settings due to the absence of explicit world-state evolution. In this work, we formulate generalized planning as a transition-model learning problem, in which a neural model explicitly approximates the successor-state function $\hatγ \approx γ$ and generates plans by rolling out symbolic state trajectories. Instead of predicting actions directly, the model autoregressively predicts intermediate world states, thereby learning the domain dynamics as an implicit world model. To study size-invariant generalization and sample efficiency, we systematically evaluate multiple state representations and neural architectures, including relational graph encodings. Our results show that learning explicit transition models yields higher out-of-distribution satisficing-plan success than direct action-sequence prediction in multiple domains, while achieving these gains with significantly fewer training instances and smaller models. This is an extended version of a short paper accepted at ICAPS 2026 under the same title.
Scalable Multi-Agent Path Finding using Collision-Aware Dynamic Alert Mask and a Hybrid Execution Strategy
Oct 10, 2025Multi-agent pathfinding (MAPF) remains a critical problem in robotics and autonomous systems, where agents must navigate shared spaces efficiently while avoiding conflicts. Traditional centralized algorithms that have global information, such as Conflict-Based Search (CBS), provide high-quality solutions but become computationally expensive in large-scale scenarios due to the combinatorial explosion of conflicts that need resolution. Conversely, distributed approaches that have local information, particularly learning-based methods, offer better scalability by operating with relaxed information availability, yet often at the cost of solution quality. To address these limitations, we propose a hybrid framework that combines decentralized path planning with a lightweight centralized coordinator. Our framework leverages reinforcement learning (RL) for decentralized planning, enabling agents to adapt their planning based on minimal, targeted alerts--such as static conflict-cell flags or brief conflict tracks--that are dynamically shared information from the central coordinator for effective conflict resolution. We empirically study the effect of the information available to an agent on its planning performance. Our approach reduces the inter-agent information sharing compared to fully centralized and distributed methods, while still consistently finding feasible, collision-free solutions--even in large-scale scenarios having higher agent counts.
FABLE: A Novel Data-Flow Analysis Benchmark on Procedural Text for Large Language Model Evaluation
May 30, 2025Understanding how data moves, transforms, and persists, known as data flow, is fundamental to reasoning in procedural tasks. Despite their fluency in natural and programming languages, large language models (LLMs), although increasingly being applied to decisions with procedural tasks, have not been systematically evaluated for their ability to perform data-flow reasoning. We introduce FABLE, an extensible benchmark designed to assess LLMs' understanding of data flow using structured, procedural text. FABLE adapts eight classical data-flow analyses from software engineering: reaching definitions, very busy expressions, available expressions, live variable analysis, interval analysis, type-state analysis, taint analysis, and concurrency analysis. These analyses are instantiated across three real-world domains: cooking recipes, travel routes, and automated plans. The benchmark includes 2,400 question-answer pairs, with 100 examples for each domain-analysis combination. We evaluate three types of LLMs: a reasoning-focused model (DeepSeek-R1 8B), a general-purpose model (LLaMA 3.1 8B), and a code-specific model (Granite Code 8B). Each model is tested using majority voting over five sampled completions per prompt. Results show that the reasoning model achieves higher accuracy, but at the cost of over 20 times slower inference compared to the other models. In contrast, the general-purpose and code-specific models perform close to random chance. FABLE provides the first diagnostic benchmark to systematically evaluate data-flow reasoning and offers insights for developing models with stronger procedural understanding.
SafeChat: A Framework for Building Trustworthy Collaborative Assistants and a Case Study of its Usefulness
Apr 15, 2025



Collaborative assistants, or chatbots, are data-driven decision support systems that enable natural interaction for task completion. While they can meet critical needs in modern society, concerns about their reliability and trustworthiness persist. In particular, Large Language Model (LLM)-based chatbots like ChatGPT, Gemini, and DeepSeek are becoming more accessible. However, such chatbots have limitations, including their inability to explain response generation, the risk of generating problematic content, the lack of standardized testing for reliability, and the need for deep AI expertise and extended development times. These issues make chatbots unsuitable for trust-sensitive applications like elections or healthcare. To address these concerns, we introduce SafeChat, a general architecture for building safe and trustworthy chatbots, with a focus on information retrieval use cases. Key features of SafeChat include: (a) safety, with a domain-agnostic design where responses are grounded and traceable to approved sources (provenance), and 'do-not-respond' strategies to prevent harmful answers; (b) usability, with automatic extractive summarization of long responses, traceable to their sources, and automated trust assessments to communicate expected chatbot behavior, such as sentiment; and (c) fast, scalable development, including a CSV-driven workflow, automated testing, and integration with various devices. We implemented SafeChat in an executable framework using the open-source chatbot platform Rasa. A case study demonstrates its application in building ElectionBot-SC, a chatbot designed to safely disseminate official election information. SafeChat is being used in many domains, validating its potential, and is available at: https://github.com/ai4society/trustworthy-chatbot.
On Creating a Causally Grounded Usable Rating Method for Assessing the Robustness of Foundation Models Supporting Time Series
Feb 17, 2025Foundation Models (FMs) have improved time series forecasting in various sectors, such as finance, but their vulnerability to input disturbances can hinder their adoption by stakeholders, such as investors and analysts. To address this, we propose a causally grounded rating framework to study the robustness of Foundational Models for Time Series (FMTS) with respect to input perturbations. We evaluate our approach to the stock price prediction problem, a well-studied problem with easily accessible public data, evaluating six state-of-the-art (some multi-modal) FMTS across six prominent stocks spanning three industries. The ratings proposed by our framework effectively assess the robustness of FMTS and also offer actionable insights for model selection and deployment. Within the scope of our study, we find that (1) multi-modal FMTS exhibit better robustness and accuracy compared to their uni-modal versions and, (2) FMTS pre-trained on time series forecasting task exhibit better robustness and forecasting accuracy compared to general-purpose FMTS pre-trained across diverse settings. Further, to validate our framework's usability, we conduct a user study showcasing FMTS prediction errors along with our computed ratings. The study confirmed that our ratings reduced the difficulty for users in comparing the robustness of different systems.
A Novel Approach to Balance Convenience and Nutrition in Meals With Long-Term Group Recommendations and Reasoning on Multimodal Recipes and its Implementation in BEACON
Dec 23, 2024



"A common decision made by people, whether healthy or with health conditions, is choosing meals like breakfast, lunch, and dinner, comprising combinations of foods for appetizer, main course, side dishes, desserts, and beverages. Often, this decision involves tradeoffs between nutritious choices (e.g., salt and sugar levels, nutrition content) and convenience (e.g., cost and accessibility, cuisine type, food source type). We present a data-driven solution for meal recommendations that considers customizable meal configurations and time horizons. This solution balances user preferences while accounting for food constituents and cooking processes. Our contributions include introducing goodness measures, a recipe conversion method from text to the recently introduced multimodal rich recipe representation (R3) format, learning methods using contextual bandits that show promising preliminary results, and the prototype, usage-inspired, BEACON system."
Do Voters Get the Information They Want? Understanding Authentic Voter FAQs in the US and How to Improve for Informed Electoral Participation
Dec 17, 2024Accurate information is crucial for democracy as it empowers voters to make informed decisions about their representatives and keeping them accountable. In the US, state election commissions (SECs), often required by law, are the primary providers of Frequently Asked Questions (FAQs) to voters, and secondary sources like non-profits such as League of Women Voters (LWV) try to complement their information shortfall. However, surprisingly, to the best of our knowledge, there is neither a single source with comprehensive FAQs nor a study analyzing the data at national level to identify current practices and ways to improve the status quo. This paper addresses it by providing the {\bf first dataset on Voter FAQs covering all the US states}. Second, we introduce metrics for FAQ information quality (FIQ) with respect to questions, answers, and answers to corresponding questions. Third, we use FIQs to analyze US FAQs to identify leading, mainstream and lagging content practices and corresponding states. Finally, we identify what states across the spectrum can do to improve FAQ quality and thus, the overall information ecosystem. Across all 50 U.S. states, 12% were identified as leaders and 8% as laggards for FIQS\textsubscript{voter}, while 14% were leaders and 12% laggards for FIQS\textsubscript{developer}.
A Neurosymbolic Fast and Slow Architecture for Graph Coloring
Dec 02, 2024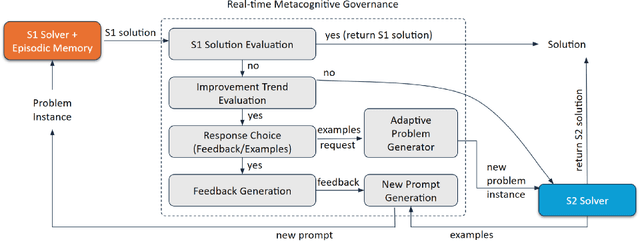


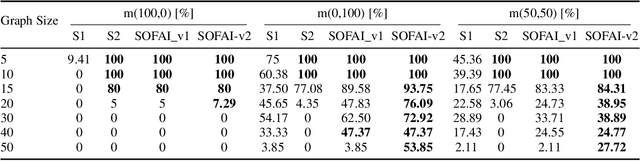
Constraint Satisfaction Problems (CSPs) present significant challenges to artificial intelligence due to their intricate constraints and the necessity for precise solutions. Existing symbolic solvers are often slow, and prior research has shown that Large Language Models (LLMs) alone struggle with CSPs because of their complexity. To bridge this gap, we build upon the existing SOFAI architecture (or SOFAI-v1), which adapts Daniel Kahneman's ''Thinking, Fast and Slow'' cognitive model to AI. Our enhanced architecture, SOFAI-v2, integrates refined metacognitive governance mechanisms to improve adaptability across complex domains, specifically tailored for solving CSPs like graph coloring. SOFAI-v2 combines a fast System 1 (S1) based on LLMs with a deliberative System 2 (S2) governed by a metacognition module. S1's initial solutions, often limited by non-adherence to constraints, are enhanced through metacognitive governance, which provides targeted feedback and examples to adapt S1 to CSP requirements. If S1 fails to solve the problem, metacognition strategically invokes S2, ensuring accurate and reliable solutions. With empirical results, we show that SOFAI-v2 for graph coloring problems achieves a 16.98% increased success rate and is 32.42% faster than symbolic solvers.
Towards Effective Planning Strategies for Dynamic Opinion Networks
Oct 18, 2024



In this study, we investigate the under-explored intervention planning aimed at disseminating accurate information within dynamic opinion networks by leveraging learning strategies. Intervention planning involves identifying key nodes (search) and exerting control (e.g., disseminating accurate/official information through the nodes) to mitigate the influence of misinformation. However, as network size increases, the problem becomes computationally intractable. To address this, we first introduce a novel ranking algorithm (search) to identify key nodes for disseminating accurate information, which facilitates the training of neural network (NN) classifiers for scalable and generalized solutions. Second, we address the complexity of label generation (through search) by developing a Reinforcement Learning (RL)-based dynamic planning framework. We investigate NN-based RL planners tailored for dynamic opinion networks governed by two propagation models for the framework. Each model incorporates both binary and continuous opinion and trust representations. Our experimental results demonstrate that our ranking algorithm-based classifiers provide plans that enhance infection rate control, especially with increased action budgets. Moreover, reward strategies focusing on key metrics, such as the number of susceptible nodes and infection rates, outperform those prioritizing faster blocking strategies. Additionally, our findings reveal that Graph Convolutional Networks (GCNs)-based planners facilitate scalable centralized plans that achieve lower infection rates (higher control) across various network scenarios (e.g., Watts-Strogatz topology, varying action budgets, varying initial infected nodes, and varying degree of infected nodes).