 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-BizRAG: Rethinking Multimodal Retrieval-Augmented Generation for General Purpose Enterprise Q&A
Jun 02, 2026Recent advances in multimodal retrieval-augmented generation (MM-RAG) have shifted toward minimal parsing, relying on page-level images for producing retriever embeddings and for answer generation. While efficient, this trend often neglects explicit handling of the rich, structured information in complex enterprise documents, instead depending on pre-trained embeddings or vision-language models to implicitly capture such structure. In this work, we take a more direct approach: MM-BizRAG proactively extracts and represents document structure via a document structure-aware split that dynamically routes documents through orientation-specific ingestion pipelines, applying explicit layout-aware parsing for vertically structured documents (e.g., reports) and holistic page-level representations for horizontally structured documents (e.g., slide decks). A unified LLM-driven artifact transformation pipeline with placeholder-based positional alignment preserves natural reading order, while inference-time multimodal assembly decouples retrieval representations from generation context, enabling richer, more grounded answers without any finetuning requirement. Through experiments on a large, heterogeneous enterprise dataset and two public benchmarks (SlideVQA and FinRAGBench-V), MM-BizRAG consistently outperforms state-of-the-art vision-centric baselines by up to 32% points, with especially strong gains on report-style layouts. Furthermore, we introduce FastRAGEval, a single-call LLM Judge metric for fine-grained generative recall that halves RAGChecker's cost while achieving stronger human alignment.
Towards Localized and Disentangled Knowledge Editing for Multimodal Large Language Models
May 28, 2026Existing methods in Multimodal Knowledge Editing (MKE) have advanced the ability to correct outdated or inaccurate knowledge in Multimodal Large Language Models (MLLMs). However, they exhibit a critical limitation: while effectively modifying target factual pairs, they fail to generalize edits to logically related queries and often cause unintended alterations to unrelated but visually or semantically linked information. We identify and formalize two underlying failure modes causing this issue: Causal Misalignment, which confines edits to the specific sample, and Feature Entanglement, which causes unintended alterations to coupled but irrelevant information. To address these issues, we propose Localized and Disentangled Knowledge Editing (LDKE), a new framework that achieves precise and generalized editing by localizing fact-specific model layers and disentangling target-relevant inputs from irrelevant ones. Our approach introduces a Fast Localization module to identify and update critical layers efficiently, along with a Disentanglement Classifier that routes inputs appropriately to preserve unrelated knowledge. Extensive experiments across various benchmarks and MLLMs demonstrate that LDKE achieves superior performance in propagating edits to related contexts while maintaining high locality.
CrossCult-KIBench: A Benchmark for Cross-Cultural Knowledge Insertion in MLLMs
May 07, 2026Multimodal Large Language Models (MLLMs), trained primarily on English-centric data, frequently generate culturally inappropriate or misaligned responses in cross-cultural settings. To mitigate this, we introduce the task of cross-cultural knowledge insertion, which focuses on adapting models to specific cultural contexts while preserving their original behavior in other cultures. To facilitate research in this area, we introduce CrossCult-KIBench, a comprehensive evaluation benchmark for assessing both the effectiveness of knowledge insertion and its unintended side effects on non-target cultures. The benchmark includes 9,800 image-grounded cases covering 49 culturally relevant visual scenarios across English, Chinese, and Arabic language-culture groups. It supports evaluation in both single-insert and sequential-insert settings. We also propose Memory-Conditioned Knowledge Insertion (MCKI) as a baseline method. MCKI retrieves relevant cultural knowledge from an external memory using frozen MLLM representations, prepending matched entries as conditional prompts when applicable. Extensive experiments on CrossCult-KIBench reveal that current approaches struggle to balance effective cultural adaptation with behavioral preservation, highlighting a key challenge in developing culturally-aware MLLMs. Our work thus underscores an important research direction for developing more culturally adaptive and responsible MLLMs.
Scalable Secure Biometric Authentication without Auxiliary Identifiers
Apr 27, 2026The prevalence of biometric authentication has been on the rise due to its ease of use and elimination of weak passwords. To date, most biometric authentication systems have been designed for on-device authentication of the device owner (e.g., smartphones and laptops). Recently, biometric authentication systems have started to emerge that are designed to authenticate users against cloud databases storing representations of biometrics for large numbers of users (potentially millions), such as those facilitating biometric payments. However, the use of a large cloud database introduces a significant attack vector, as a breach of the database could lead to the compromise of all enrolled users' sensitive biometric data. Indeed, all such existing systems either do not adequately protect against such a breach, or are impractical to deploy and use due to their high computational overhead. In this work, we present a new biometric authentication system that provides provable security guarantees against data breaches, while remaining scalable and performant. To do so, we marry artificial intelligence with advanced cryptographic techniques in a novel fashion, providing several optimizations along the way. Our work is the first to show that real-world scalable privacy-preserving biometric authentication without auxiliary identifiers is feasible, and we believe that it will spur widespread industrial adoption and further research in this area.
Continual Learning of Domain Knowledge from Human Feedback in Text-to-SQL
Nov 10, 2025Large Language Models (LLMs) can generate SQL queries from natural language questions but struggle with database-specific schemas and tacit domain knowledge. We introduce a framework for continual learning from human feedback in text-to-SQL, where a learning agent receives natural language feedback to refine queries and distills the revealed knowledge for reuse on future tasks. This distilled knowledge is stored in a structured memory, enabling the agent to improve execution accuracy over time. We design and evaluate multiple variations of a learning agent architecture that vary in how they capture and retrieve past experiences. Experiments on the BIRD benchmark Dev set show that memory-augmented agents, particularly the Procedural Agent, achieve significant accuracy gains and error reduction by leveraging human-in-the-loop feedback. Our results highlight the importance of transforming tacit human expertise into reusable knowledge, paving the way for more adaptive, domain-aware text-to-SQL systems that continually learn from a human-in-the-loop.
SlideAgent: Hierarchical Agentic Framework for Multi-Page Visual Document Understanding
Oct 30, 2025
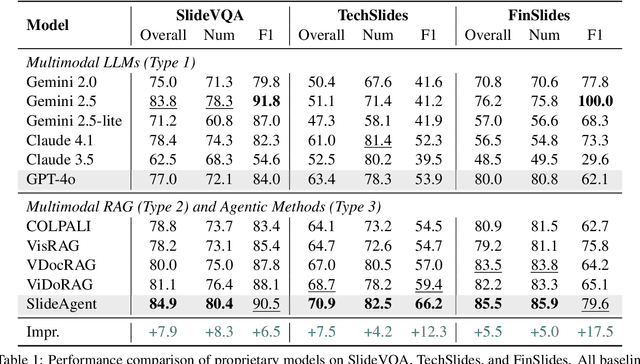


Multi-page visual documents such as manuals, brochures, presentations, and posters convey key information through layout, colors, icons, and cross-slide references. While large language models (LLMs) offer opportunities in document understanding, current systems struggle with complex, multi-page visual documents, particularly in fine-grained reasoning over elements and pages. We introduce SlideAgent, a versatile agentic framework for understanding multi-modal, multi-page, and multi-layout documents, especially slide decks. SlideAgent employs specialized agents and decomposes reasoning into three specialized levels-global, page, and element-to construct a structured, query-agnostic representation that captures both overarching themes and detailed visual or textual cues. During inference, SlideAgent selectively activates specialized agents for multi-level reasoning and integrates their outputs into coherent, context-aware answers. Extensive experiments show that SlideAgent achieves significant improvement over both proprietary (+7.9 overall) and open-source models (+9.8 overall).
ChartAgent: A Multimodal Agent for Visually Grounded Reasoning in Complex Chart Question Answering
Oct 06, 2025Recent multimodal LLMs have shown promise in chart-based visual question answering, but their performance declines sharply on unannotated charts, those requiring precise visual interpretation rather than relying on textual shortcuts. To address this, we introduce ChartAgent, a novel agentic framework that explicitly performs visual reasoning directly within the chart's spatial domain. Unlike textual chain-of-thought reasoning, ChartAgent iteratively decomposes queries into visual subtasks and actively manipulates and interacts with chart images through specialized actions such as drawing annotations, cropping regions (e.g., segmenting pie slices, isolating bars), and localizing axes, using a library of chart-specific vision tools to fulfill each subtask. This iterative reasoning process closely mirrors human cognitive strategies for chart comprehension. ChartAgent achieves state-of-the-art accuracy on the ChartBench and ChartX benchmarks, surpassing prior methods by up to 16.07% absolute gain overall and 17.31% on unannotated, numerically intensive queries. Furthermore, our analyses show that ChartAgent is (a) effective across diverse chart types, (b) achieve the highest scores across varying visual and reasoning complexity levels, and (c) serves as a plug-and-play framework that boosts performance across diverse underlying LLMs. Our work is among the first to demonstrate visually grounded reasoning for chart understanding using tool-augmented multimodal agents.
TADACap: Time-series Adaptive Domain-Aware Captioning
Apr 15, 2025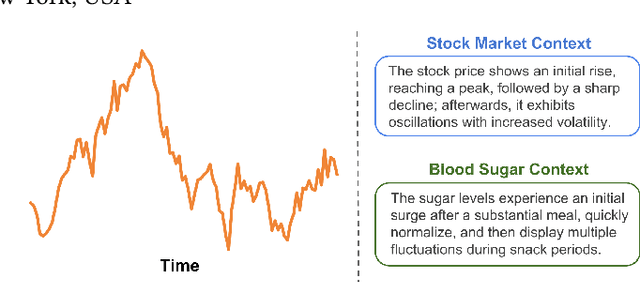



While image captioning has gained significant attention, the potential of captioning time-series images, prevalent in areas like finance and healthcare, remains largely untapped. Existing time-series captioning methods typically offer generic, domain-agnostic descriptions of time-series shapes and struggle to adapt to new domains without substantial retraining. To address these limitations, we introduce TADACap, a retrieval-based framework to generate domain-aware captions for time-series images, capable of adapting to new domains without retraining. Building on TADACap, we propose a novel retrieval strategy that retrieves diverse image-caption pairs from a target domain database, namely TADACap-diverse. We benchmarked TADACap-diverse against state-of-the-art methods and ablation variants. TADACap-diverse demonstrates comparable semantic accuracy while requiring significantly less annotation effort.
On Creating a Causally Grounded Usable Rating Method for Assessing the Robustness of Foundation Models Supporting Time Series
Feb 17, 2025Foundation Models (FMs) have improved time series forecasting in various sectors, such as finance, but their vulnerability to input disturbances can hinder their adoption by stakeholders, such as investors and analysts. To address this, we propose a causally grounded rating framework to study the robustness of Foundational Models for Time Series (FMTS) with respect to input perturbations. We evaluate our approach to the stock price prediction problem, a well-studied problem with easily accessible public data, evaluating six state-of-the-art (some multi-modal) FMTS across six prominent stocks spanning three industries. The ratings proposed by our framework effectively assess the robustness of FMTS and also offer actionable insights for model selection and deployment. Within the scope of our study, we find that (1) multi-modal FMTS exhibit better robustness and accuracy compared to their uni-modal versions and, (2) FMTS pre-trained on time series forecasting task exhibit better robustness and forecasting accuracy compared to general-purpose FMTS pre-trained across diverse settings. Further, to validate our framework's usability, we conduct a user study showcasing FMTS prediction errors along with our computed ratings. The study confirmed that our ratings reduced the difficulty for users in comparing the robustness of different systems.
LAW: Legal Agentic Workflows for Custody and Fund Services Contracts
Dec 15, 2024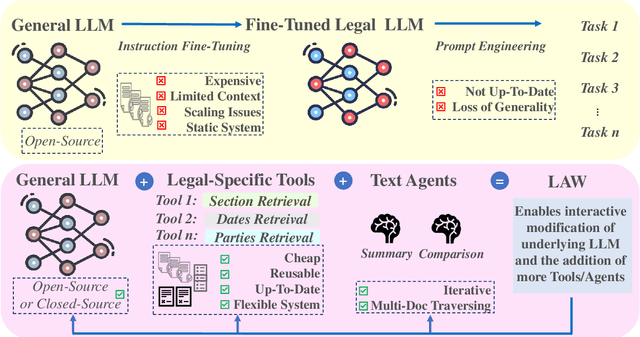
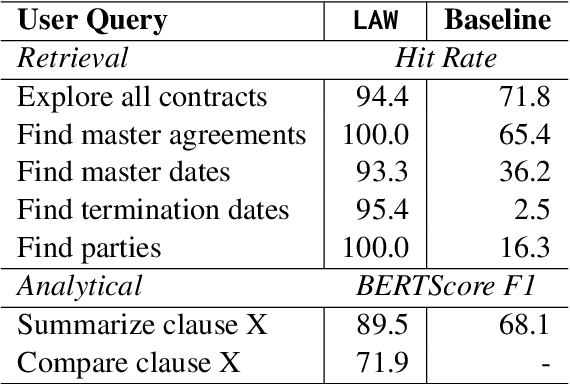
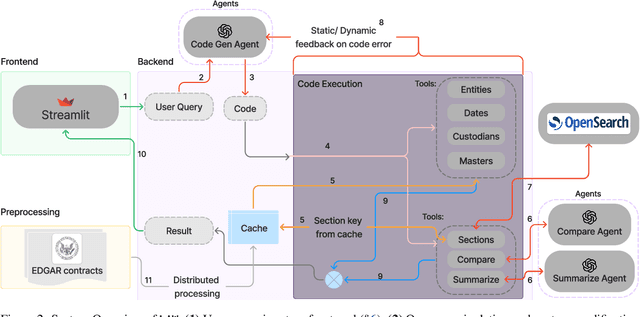

Legal contracts in the custody and fund services domain govern critical aspects such as key provider responsibilities, fee schedules, and indemnification rights. However, it is challenging for an off-the-shelf Large Language Model (LLM) to ingest these contracts due to the lengthy unstructured streams of text, limited LLM context windows, and complex legal jargon. To address these challenges, we introduce LAW (Legal Agentic Workflows for Custody and Fund Services Contracts). LAW features a modular design that responds to user queries by orchestrating a suite of domain-specific tools and text agents. Our experiments demonstrate that LAW, by integrating multiple specialized agents and tools, significantly outperforms the baseline. LAW excels particularly in complex tasks such as calculating a contract's termination date, surpassing the baseline by 92.9% points. Furthermore, LAW offers a cost-effective alternative to traditional fine-tuned legal LLMs by leveraging reusable, domain-specific tools.