 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Linear Coregionalization for Realistic Synthetic Multivariate Time Series
Apr 06, 2026Synthetic data is essential for training foundation models for time series (FMTS), but most generators assume static correlations, and are typically missing realistic inter-channel dependencies. We introduce DynLMC, a Dynamic Linear Model of Coregionalization, that incorporates time-varying, regime-switching correlations and cross-channel lag structures. Our approach produces synthetic multivariate time series with correlation dynamics that closely resemble real data. Fine-tuning three foundational models on DynLMC-generated data yields consistent zero-shot forecasting improvements across nine benchmarks. Our results demonstrate that modeling dynamic inter-channel correlations enhances FMTS transferability, highlighting the importance of data-centric pretraining.
TADACap: Time-series Adaptive Domain-Aware Captioning
Apr 15, 2025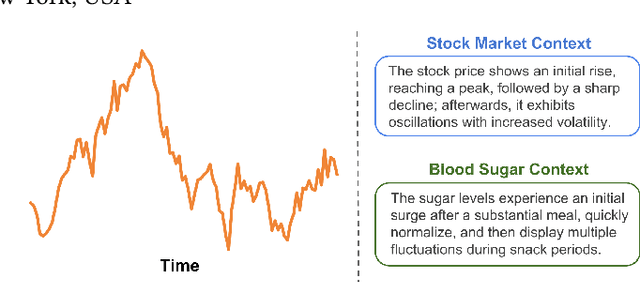



While image captioning has gained significant attention, the potential of captioning time-series images, prevalent in areas like finance and healthcare, remains largely untapped. Existing time-series captioning methods typically offer generic, domain-agnostic descriptions of time-series shapes and struggle to adapt to new domains without substantial retraining. To address these limitations, we introduce TADACap, a retrieval-based framework to generate domain-aware captions for time-series images, capable of adapting to new domains without retraining. Building on TADACap, we propose a novel retrieval strategy that retrieves diverse image-caption pairs from a target domain database, namely TADACap-diverse. We benchmarked TADACap-diverse against state-of-the-art methods and ablation variants. TADACap-diverse demonstrates comparable semantic accuracy while requiring significantly less annotation effort.
A Language Model-Guided Framework for Mining Time Series with Distributional Shifts
Jun 07, 2024Effective utilization of time series data is often constrained by the scarcity of data quantity that reflects complex dynamics, especially under the condition of distributional shifts. Existing datasets may not encompass the full range of statistical properties required for robust and comprehensive analysis. And privacy concerns can further limit their accessibility in domains such as finance and healthcare. This paper presents an approach that utilizes large language models and data source interfaces to explore and collect time series datasets. While obtained from external sources, the collected data share critical statistical properties with primary time series datasets, making it possible to model and adapt to various scenarios. This method enlarges the data quantity when the original data is limited or lacks essential properties. It suggests that collected datasets can effectively supplement existing datasets, especially involving changes in data distribution. We demonstrate the effectiveness of the collected datasets through practical examples and show how time series forecasting foundation models fine-tuned on these datasets achieve comparable performance to those models without fine-tuning.
Evaluating Large Language Models on Time Series Feature Understanding: A Comprehensive Taxonomy and Benchmark
Apr 25, 2024Large Language Models (LLMs) offer the potential for automatic time series analysis and reporting, which is a critical task across many domains, spanning healthcare, finance, climate, energy, and many more. In this paper, we propose a framework for rigorously evaluating the capabilities of LLMs on time series understanding, encompassing both univariate and multivariate forms. We introduce a comprehensive taxonomy of time series features, a critical framework that delineates various characteristics inherent in time series data. Leveraging this taxonomy, we have systematically designed and synthesized a diverse dataset of time series, embodying the different outlined features. This dataset acts as a solid foundation for assessing the proficiency of LLMs in comprehending time series. Our experiments shed light on the strengths and limitations of state-of-the-art LLMs in time series understanding, revealing which features these models readily comprehend effectively and where they falter. In addition, we uncover the sensitivity of LLMs to factors including the formatting of the data, the position of points queried within a series and the overall time series length.
Synthetic Data Applications in Finance
Dec 29, 2023

Synthetic data has made tremendous strides in various commercial settings including finance, healthcare, and virtual reality. We present a broad overview of prototypical applications of synthetic data in the financial sector and in particular provide richer details for a few select ones. These cover a wide variety of data modalities including tabular, time-series, event-series, and unstructured arising from both markets and retail financial applications. Since finance is a highly regulated industry, synthetic data is a potential approach for dealing with issues related to privacy, fairness, and explainability. Various metrics are utilized in evaluating the quality and effectiveness of our approaches in these applications. We conclude with open directions in synthetic data in the context of the financial domain.
Augment on Manifold: Mixup Regularization with UMAP
Dec 20, 2023

Data augmentation techniques play an important role in enhancing the performance of deep learning models. Despite their proven benefits in computer vision tasks, their application in the other domains remains limited. This paper proposes a Mixup regularization scheme, referred to as UMAP Mixup, designed for "on-manifold" automated data augmentation for deep learning predictive models. The proposed approach ensures that the Mixup operations result in synthesized samples that lie on the data manifold of the features and labels by utilizing a dimensionality reduction technique known as uniform manifold approximation and projection. Evaluations across diverse regression tasks show that UMAP Mixup is competitive with or outperforms other Mixup variants, show promise for its potential as an effective tool for enhancing the generalization performance of deep learning models.
Multi-Modal Financial Time-Series Retrieval Through Latent Space Projections
Sep 28, 2023Financial firms commonly process and store billions of time-series data, generated continuously and at a high frequency. To support efficient data storage and retrieval, specialized time-series databases and systems have emerged. These databases support indexing and querying of time-series by a constrained Structured Query Language(SQL)-like format to enable queries like "Stocks with monthly price returns greater than 5%", and expressed in rigid formats. However, such queries do not capture the intrinsic complexity of high dimensional time-series data, which can often be better described by images or language (e.g., "A stock in low volatility regime"). Moreover, the required storage, computational time, and retrieval complexity to search in the time-series space are often non-trivial. In this paper, we propose and demonstrate a framework to store multi-modal data for financial time-series in a lower-dimensional latent space using deep encoders, such that the latent space projections capture not only the time series trends but also other desirable information or properties of the financial time-series data (such as price volatility). Moreover, our approach allows user-friendly query interfaces, enabling natural language text or sketches of time-series, for which we have developed intuitive interfaces. We demonstrate the advantages of our method in terms of computational efficiency and accuracy on real historical data as well as synthetic data, and highlight the utility of latent-space projections in the storage and retrieval of financial time-series data with intuitive query modalities.
MADS: Modulated Auto-Decoding SIREN for time series imputation
Jul 03, 2023Time series imputation remains a significant challenge across many fields due to the potentially significant variability in the type of data being modelled. Whilst traditional imputation methods often impose strong assumptions on the underlying data generation process, limiting their applicability, researchers have recently begun to investigate the potential of deep learning for this task, inspired by the strong performance shown by these models in both classification and regression problems across a range of applications. In this work we propose MADS, a novel auto-decoding framework for time series imputation, built upon implicit neural representations. Our method leverages the capabilities of SIRENs for high fidelity reconstruction of signals and irregular data, and combines it with a hypernetwork architecture which allows us to generalise by learning a prior over the space of time series. We evaluate our model on two real-world datasets, and show that it outperforms state-of-the-art methods for time series imputation. On the human activity dataset, it improves imputation performance by at least 40%, while on the air quality dataset it is shown to be competitive across all metrics. When evaluated on synthetic data, our model results in the best average rank across different dataset configurations over all baselines.
Deep Gaussian Mixture Ensembles
Jun 12, 2023



This work introduces a novel probabilistic deep learning technique called deep Gaussian mixture ensembles (DGMEs), which enables accurate quantification of both epistemic and aleatoric uncertainty. By assuming the data generating process follows that of a Gaussian mixture, DGMEs are capable of approximating complex probability distributions, such as heavy-tailed or multimodal distributions. Our contributions include the derivation of an expectation-maximization (EM) algorithm used for learning the model parameters, which results in an upper-bound on the log-likelihood of training data over that of standard deep ensembles. Additionally, the proposed EM training procedure allows for learning of mixture weights, which is not commonly done in ensembles. Our experimental results demonstrate that DGMEs outperform state-of-the-art uncertainty quantifying deep learning models in handling complex predictive densities.
HyperTime: Implicit Neural Representation for Time Series
Aug 11, 2022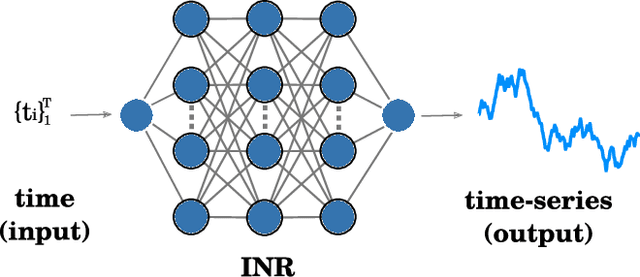
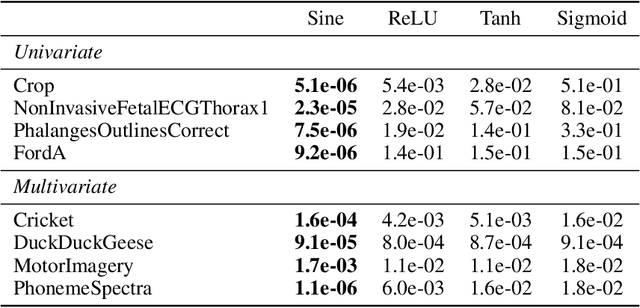
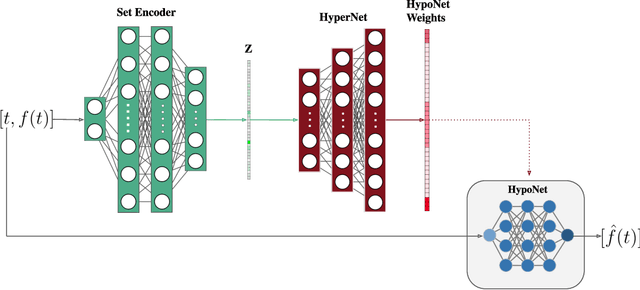
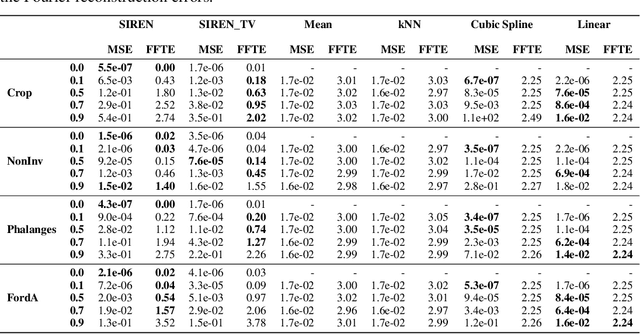
Implicit neural representations (INRs) have recently emerged as a powerful tool that provides an accurate and resolution-independent encoding of data. Their robustness as general approximators has been shown in a wide variety of data sources, with applications on image, sound, and 3D scene representation. However, little attention has been given to leveraging these architectures for the representation and analysis of time series data. In this paper, we analyze the representation of time series using INRs, comparing different activation functions in terms of reconstruction accuracy and training convergence speed. We show how these networks can be leveraged for the imputation of time series, with applications on both univariate and multivariate data. Finally, we propose a hypernetwork architecture that leverages INRs to learn a compressed latent representation of an entire time series dataset. We introduce an FFT-based loss to guide training so that all frequencies are preserved in the time series. We show that this network can be used to encode time series as INRs, and their embeddings can be interpolated to generate new time series from existing ones. We evaluate our generative method by using it for data augmentation, and show that it is competitive against current state-of-the-art approaches for augmentation of time series.