 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending Diffusion Models Against Membership Inference Attacks via Higher-Order Langevin Dynamics
Sep 17, 2025Recent advances in generative artificial intelligence applications have raised new data security concerns. This paper focuses on defending diffusion models against membership inference attacks. This type of attack occurs when the attacker can determine if a certain data point was used to train the model. Although diffusion models are intrinsically more resistant to membership inference attacks than other generative models, they are still susceptible. The defense proposed here utilizes critically-damped higher-order Langevin dynamics, which introduces several auxiliary variables and a joint diffusion process along these variables. The idea is that the presence of auxiliary variables mixes external randomness that helps to corrupt sensitive input data earlier on in the diffusion process. This concept is theoretically investigated and validated on a toy dataset and a speech dataset using the Area Under the Receiver Operating Characteristic (AUROC) curves and the FID metric.
Mixup Regularization: A Probabilistic Perspective
Feb 19, 2025In recent years, mixup regularization has gained popularity as an effective way to improve the generalization performance of deep learning models by training on convex combinations of training data. While many mixup variants have been explored, the proper adoption of the technique to conditional density estimation and probabilistic machine learning remains relatively unexplored. This work introduces a novel framework for mixup regularization based on probabilistic fusion that is better suited for conditional density estimation tasks. For data distributed according to a member of the exponential family, we show that likelihood functions can be analytically fused using log-linear pooling. We further propose an extension of probabilistic mixup, which allows for fusion of inputs at an arbitrary intermediate layer of the neural network. We provide a theoretical analysis comparing our approach to standard mixup variants. Empirical results on synthetic and real datasets demonstrate the benefits of our proposed framework compared to existing mixup variants.
Variational Neural Stochastic Differential Equations with Change Points
Nov 01, 2024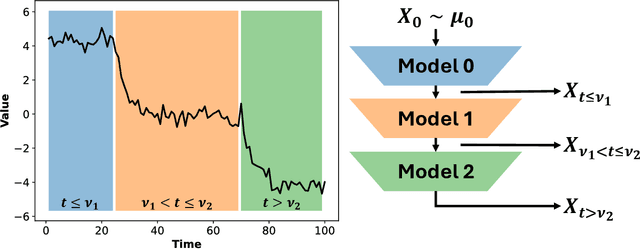


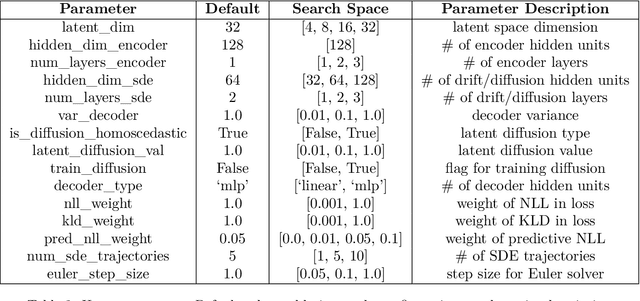
In this work, we explore modeling change points in time-series data using neural stochastic differential equations (neural SDEs). We propose a novel model formulation and training procedure based on the variational autoencoder (VAE) framework for modeling time-series as a neural SDE. Unlike existing algorithms training neural SDEs as VAEs, our proposed algorithm only necessitates a Gaussian prior of the initial state of the latent stochastic process, rather than a Wiener process prior on the entire latent stochastic process. We develop two methodologies for modeling and estimating change points in time-series data with distribution shifts. Our iterative algorithm alternates between updating neural SDE parameters and updating the change points based on either a maximum likelihood-based approach or a change point detection algorithm using the sequential likelihood ratio test. We provide a theoretical analysis of this proposed change point detection scheme. Finally, we present an empirical evaluation that demonstrates the expressive power of our proposed model, showing that it can effectively model both classical parametric SDEs and some real datasets with distribution shifts.
Fusion of Information in Multiple Particle Filtering in the Presence of Unknown Static Parameters
Oct 31, 2024


An important and often overlooked aspect of particle filtering methods is the estimation of unknown static parameters. A simple approach for addressing this problem is to augment the unknown static parameters as auxiliary states that are jointly estimated with the time-varying parameters of interest. This can be impractical, especially when the system of interest is high-dimensional. Multiple particle filtering (MPF) methods were introduced to try to overcome the curse of dimensionality by using a divide and conquer approach, where the vector of unknowns is partitioned into a set of subvectors, each estimated by a separate particle filter. Each particle filter weighs its own particles by using predictions and estimates communicated from the other filters. Currently, there is no principled way to implement MPF methods where the particle filters share unknown parameters or states. In this work, we propose a fusion strategy to allow for the sharing of unknown static parameters in the MPF setting. Specifically, we study the systems which are separable in states and observations. It is proved that optimal Bayesian fusion can be obtained for state-space models with non-interacting states and observations. Simulations are performed to show that MPF with fusion strategy can provide more accurate estimates within fewer time steps comparing to existing algorithms.
A Language Model-Guided Framework for Mining Time Series with Distributional Shifts
Jun 07, 2024Effective utilization of time series data is often constrained by the scarcity of data quantity that reflects complex dynamics, especially under the condition of distributional shifts. Existing datasets may not encompass the full range of statistical properties required for robust and comprehensive analysis. And privacy concerns can further limit their accessibility in domains such as finance and healthcare. This paper presents an approach that utilizes large language models and data source interfaces to explore and collect time series datasets. While obtained from external sources, the collected data share critical statistical properties with primary time series datasets, making it possible to model and adapt to various scenarios. This method enlarges the data quantity when the original data is limited or lacks essential properties. It suggests that collected datasets can effectively supplement existing datasets, especially involving changes in data distribution. We demonstrate the effectiveness of the collected datasets through practical examples and show how time series forecasting foundation models fine-tuned on these datasets achieve comparable performance to those models without fine-tuning.
Synthetic Data Applications in Finance
Dec 29, 2023

Synthetic data has made tremendous strides in various commercial settings including finance, healthcare, and virtual reality. We present a broad overview of prototypical applications of synthetic data in the financial sector and in particular provide richer details for a few select ones. These cover a wide variety of data modalities including tabular, time-series, event-series, and unstructured arising from both markets and retail financial applications. Since finance is a highly regulated industry, synthetic data is a potential approach for dealing with issues related to privacy, fairness, and explainability. Various metrics are utilized in evaluating the quality and effectiveness of our approaches in these applications. We conclude with open directions in synthetic data in the context of the financial domain.
Augment on Manifold: Mixup Regularization with UMAP
Dec 20, 2023

Data augmentation techniques play an important role in enhancing the performance of deep learning models. Despite their proven benefits in computer vision tasks, their application in the other domains remains limited. This paper proposes a Mixup regularization scheme, referred to as UMAP Mixup, designed for "on-manifold" automated data augmentation for deep learning predictive models. The proposed approach ensures that the Mixup operations result in synthesized samples that lie on the data manifold of the features and labels by utilizing a dimensionality reduction technique known as uniform manifold approximation and projection. Evaluations across diverse regression tasks show that UMAP Mixup is competitive with or outperforms other Mixup variants, show promise for its potential as an effective tool for enhancing the generalization performance of deep learning models.
Neural Stochastic Differential Equations with Change Points: A Generative Adversarial Approach
Dec 20, 2023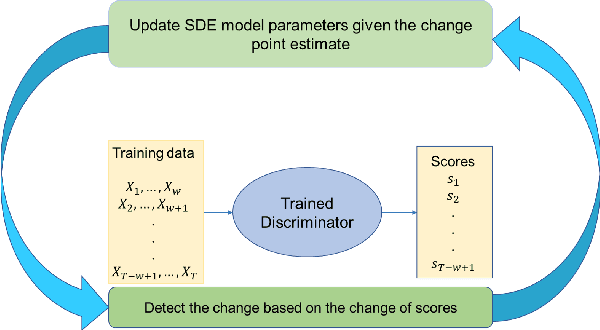
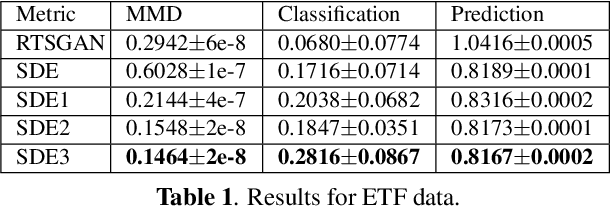

Stochastic differential equations (SDEs) have been widely used to model real world random phenomena. Existing works mainly focus on the case where the time series is modeled by a single SDE, which might be restrictive for modeling time series with distributional shift. In this work, we propose a change point detection algorithm for time series modeled as neural SDEs. Given a time series dataset, the proposed method jointly learns the unknown change points and the parameters of distinct neural SDE models corresponding to each change point. Specifically, the SDEs are learned under the framework of generative adversarial networks (GANs) and the change points are detected based on the output of the GAN discriminator in a forward pass. At each step of the proposed algorithm, the change points and the SDE model parameters are updated in an alternating fashion. Numerical results on both synthetic and real datasets are provided to validate the performance of our algorithm in comparison to classical change point detection benchmarks, standard GAN-based neural SDEs, and other state-of-the-art deep generative models for time series data.
MADS: Modulated Auto-Decoding SIREN for time series imputation
Jul 03, 2023Time series imputation remains a significant challenge across many fields due to the potentially significant variability in the type of data being modelled. Whilst traditional imputation methods often impose strong assumptions on the underlying data generation process, limiting their applicability, researchers have recently begun to investigate the potential of deep learning for this task, inspired by the strong performance shown by these models in both classification and regression problems across a range of applications. In this work we propose MADS, a novel auto-decoding framework for time series imputation, built upon implicit neural representations. Our method leverages the capabilities of SIRENs for high fidelity reconstruction of signals and irregular data, and combines it with a hypernetwork architecture which allows us to generalise by learning a prior over the space of time series. We evaluate our model on two real-world datasets, and show that it outperforms state-of-the-art methods for time series imputation. On the human activity dataset, it improves imputation performance by at least 40%, while on the air quality dataset it is shown to be competitive across all metrics. When evaluated on synthetic data, our model results in the best average rank across different dataset configurations over all baselines.
Deep Gaussian Mixture Ensembles
Jun 12, 2023



This work introduces a novel probabilistic deep learning technique called deep Gaussian mixture ensembles (DGMEs), which enables accurate quantification of both epistemic and aleatoric uncertainty. By assuming the data generating process follows that of a Gaussian mixture, DGMEs are capable of approximating complex probability distributions, such as heavy-tailed or multimodal distributions. Our contributions include the derivation of an expectation-maximization (EM) algorithm used for learning the model parameters, which results in an upper-bound on the log-likelihood of training data over that of standard deep ensembles. Additionally, the proposed EM training procedure allows for learning of mixture weights, which is not commonly done in ensembles. Our experimental results demonstrate that DGMEs outperform state-of-the-art uncertainty quantifying deep learning models in handling complex predictive densities.