 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenPlanX. Generation of Plans and Execution
Jun 12, 2025Classical AI Planning techniques generate sequences of actions for complex tasks. However, they lack the ability to understand planning tasks when provided using natural language. The advent of Large Language Models (LLMs) has introduced novel capabilities in human-computer interaction. In the context of planning tasks, LLMs have shown to be particularly good in interpreting human intents among other uses. This paper introduces GenPlanX that integrates LLMs for natural language-based description of planning tasks, with a classical AI planning engine, alongside an execution and monitoring framework. We demonstrate the efficacy of GenPlanX in assisting users with office-related tasks, highlighting its potential to streamline workflows and enhance productivity through seamless human-AI collaboration.
QBD-RankedDataGen: Generating Custom Ranked Datasets for Improving Query-By-Document Search Using LLM-Reranking with Reduced Human Effort
May 07, 2025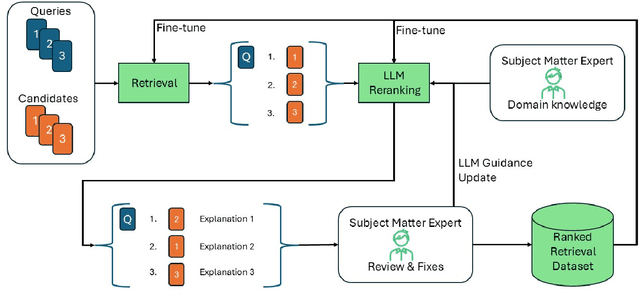
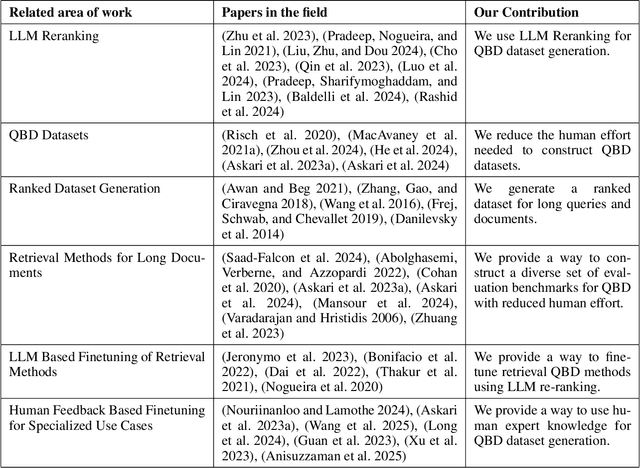
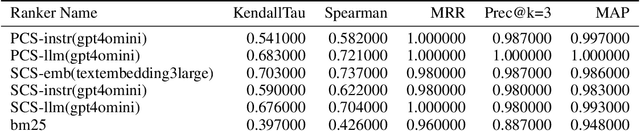
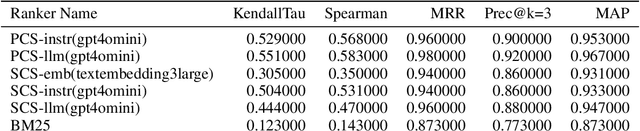
The Query-By-Document (QBD) problem is an information retrieval problem where the query is a document, and the retrieved candidates are documents that match the query document, often in a domain or query specific manner. This can be crucial for tasks such as patent matching, legal or compliance case retrieval, and academic literature review. Existing retrieval methods, including keyword search and document embeddings, can be optimized with domain-specific datasets to improve QBD search performance. However, creating these domain-specific datasets is often costly and time-consuming. Our work introduces a process to generate custom QBD-search datasets and compares a set of methods to use in this problem, which we refer to as QBD-RankedDatagen. We provide a comparative analysis of our proposed methods in terms of cost, speed, and the human interface with the domain experts. The methods we compare leverage Large Language Models (LLMs) which can incorporate domain expert input to produce document scores and rankings, as well as explanations for human review. The process and methods for it that we present can significantly reduce human effort in dataset creation for custom domains while still obtaining sufficient expert knowledge for tuning retrieval models. We evaluate our methods on QBD datasets from the Text Retrieval Conference (TREC) and finetune the parameters of the BM25 model -- which is used in many industrial-strength search engines like OpenSearch -- using the generated data.
Robust and Efficient Fine-tuning of LLMs with Bayesian Reparameterization of Low-Rank Adaptation
Nov 07, 2024



Large Language Models (LLMs) are highly resource-intensive to fine-tune due to their enormous size. While low-rank adaptation is a prominent parameter-efficient fine-tuning approach, it suffers from sensitivity to hyperparameter choices, leading to instability in model performance on fine-tuning downstream tasks. This paper highlights the importance of effective parameterization in low-rank fine-tuning to reduce estimator variance and enhance the stability of final model outputs. We propose MonteCLoRA, an efficient fine-tuning technique, employing Monte Carlo estimation to learn an unbiased posterior estimation of low-rank parameters with low expected variance, which stabilizes fine-tuned LLMs with only O(1) additional parameters. MonteCLoRA shows significant improvements in accuracy and robustness, achieving up to 3.8% higher accuracy and 8.6% greater robustness than existing efficient fine-tuning methods on natural language understanding tasks with pre-trained RoBERTa-base. Furthermore, in generative tasks with pre-trained LLaMA-1-7B, MonteCLoRA demonstrates robust zero-shot performance with 50% lower variance than the contemporary efficient fine-tuning methods. The theoretical and empirical results presented in the paper underscore how parameterization and hyperpriors balance exploration-exploitation in the low-rank parametric space, therefore leading to more optimal and robust parameter estimation during efficient fine-tuning.
On Learning Action Costs from Input Plans
Aug 20, 2024Most of the work on learning action models focus on learning the actions' dynamics from input plans. This allows us to specify the valid plans of a planning task. However, very little work focuses on learning action costs, which in turn allows us to rank the different plans. In this paper we introduce a new problem: that of learning the costs of a set of actions such that a set of input plans are optimal under the resulting planning model. To solve this problem we present $LACFIP^k$, an algorithm to learn action's costs from unlabeled input plans. We provide theoretical and empirical results showing how $LACFIP^k$ can successfully solve this task.
TRIP-PAL: Travel Planning with Guarantees by Combining Large Language Models and Automated Planners
Jun 14, 2024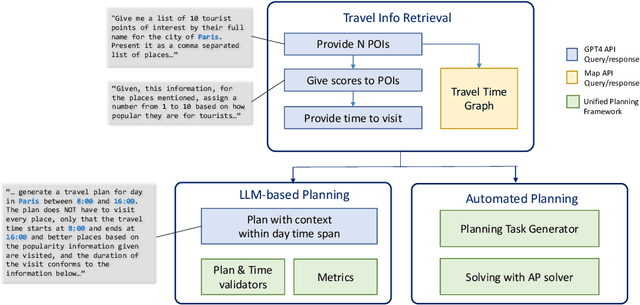

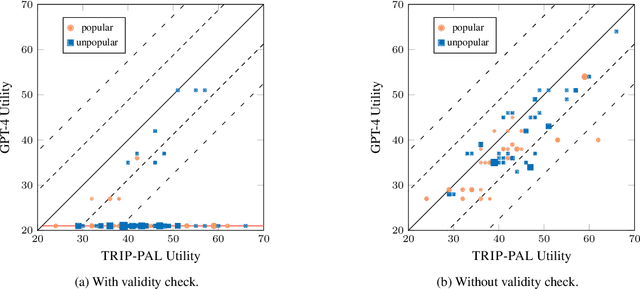
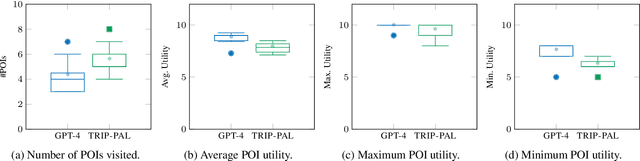
Travel planning is a complex task that involves generating a sequence of actions related to visiting places subject to constraints and maximizing some user satisfaction criteria. Traditional approaches rely on problem formulation in a given formal language, extracting relevant travel information from web sources, and use an adequate problem solver to generate a valid solution. As an alternative, recent Large Language Model (LLM) based approaches directly output plans from user requests using language. Although LLMs possess extensive travel domain knowledge and provide high-level information like points of interest and potential routes, current state-of-the-art models often generate plans that lack coherence, fail to satisfy constraints fully, and do not guarantee the generation of high-quality solutions. We propose TRIP-PAL, a hybrid method that combines the strengths of LLMs and automated planners, where (i) LLMs get and translate travel information and user information into data structures that can be fed into planners; and (ii) automated planners generate travel plans that guarantee constraint satisfaction and optimize for users' utility. Our experiments across various travel scenarios show that TRIP-PAL outperforms an LLM when generating travel plans.
Synthetic Data Applications in Finance
Dec 29, 2023

Synthetic data has made tremendous strides in various commercial settings including finance, healthcare, and virtual reality. We present a broad overview of prototypical applications of synthetic data in the financial sector and in particular provide richer details for a few select ones. These cover a wide variety of data modalities including tabular, time-series, event-series, and unstructured arising from both markets and retail financial applications. Since finance is a highly regulated industry, synthetic data is a potential approach for dealing with issues related to privacy, fairness, and explainability. Various metrics are utilized in evaluating the quality and effectiveness of our approaches in these applications. We conclude with open directions in synthetic data in the context of the financial domain.
Multi-Modal Financial Time-Series Retrieval Through Latent Space Projections
Sep 28, 2023Financial firms commonly process and store billions of time-series data, generated continuously and at a high frequency. To support efficient data storage and retrieval, specialized time-series databases and systems have emerged. These databases support indexing and querying of time-series by a constrained Structured Query Language(SQL)-like format to enable queries like "Stocks with monthly price returns greater than 5%", and expressed in rigid formats. However, such queries do not capture the intrinsic complexity of high dimensional time-series data, which can often be better described by images or language (e.g., "A stock in low volatility regime"). Moreover, the required storage, computational time, and retrieval complexity to search in the time-series space are often non-trivial. In this paper, we propose and demonstrate a framework to store multi-modal data for financial time-series in a lower-dimensional latent space using deep encoders, such that the latent space projections capture not only the time series trends but also other desirable information or properties of the financial time-series data (such as price volatility). Moreover, our approach allows user-friendly query interfaces, enabling natural language text or sketches of time-series, for which we have developed intuitive interfaces. We demonstrate the advantages of our method in terms of computational efficiency and accuracy on real historical data as well as synthetic data, and highlight the utility of latent-space projections in the storage and retrieval of financial time-series data with intuitive query modalities.
SafeAR: Towards Safer Algorithmic Recourse by Risk-Aware Policies
Aug 23, 2023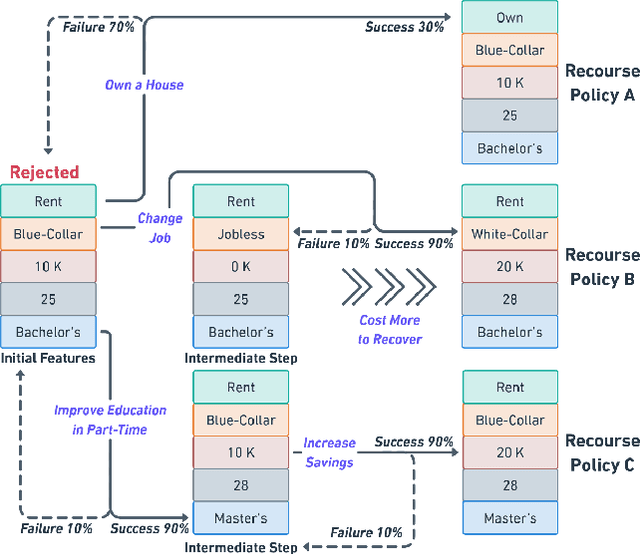
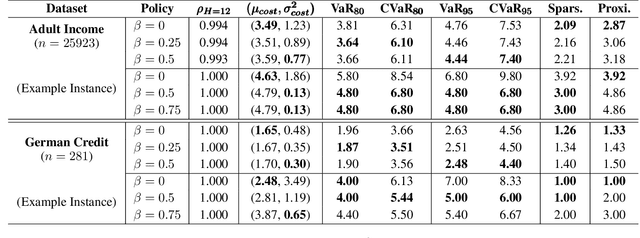
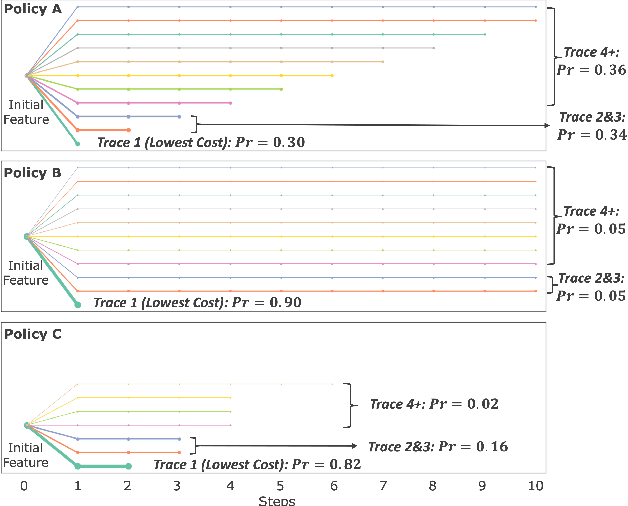

With the growing use of machine learning (ML) models in critical domains such as finance and healthcare, the need to offer recourse for those adversely affected by the decisions of ML models has become more important; individuals ought to be provided with recommendations on actions to take for improving their situation and thus receive a favorable decision. Prior work on sequential algorithmic recourse -- which recommends a series of changes -- focuses on action feasibility and uses the proximity of feature changes to determine action costs. However, the uncertainties of feature changes and the risk of higher than average costs in recourse have not been considered. It is undesirable if a recourse could (with some probability) result in a worse situation from which recovery requires an extremely high cost. It is essential to incorporate risks when computing and evaluating recourse. We call the recourse computed with such risk considerations as Safer Algorithmic Recourse (SafeAR). The objective is to empower people to choose a recourse based on their risk tolerance. In this work, we discuss and show how existing recourse desiderata can fail to capture the risk of higher costs. We present a method to compute recourse policies that consider variability in cost and connect algorithmic recourse literature with risk-sensitive reinforcement learning. We also adopt measures ``Value at Risk'' and ``Conditional Value at Risk'' from the financial literature to summarize risk concisely. We apply our method to two real-world datasets and compare policies with different levels of risk-aversion using risk measures and recourse desiderata (sparsity and proximity).
Methods and Mechanisms for Interactive Novelty Handling in Adversarial Environments
Mar 06, 2023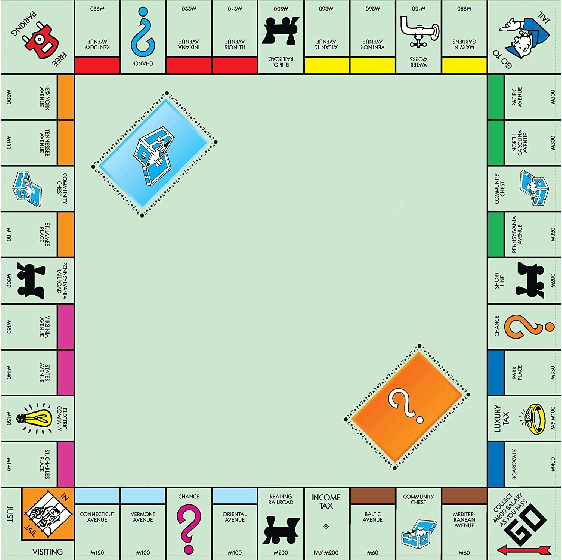
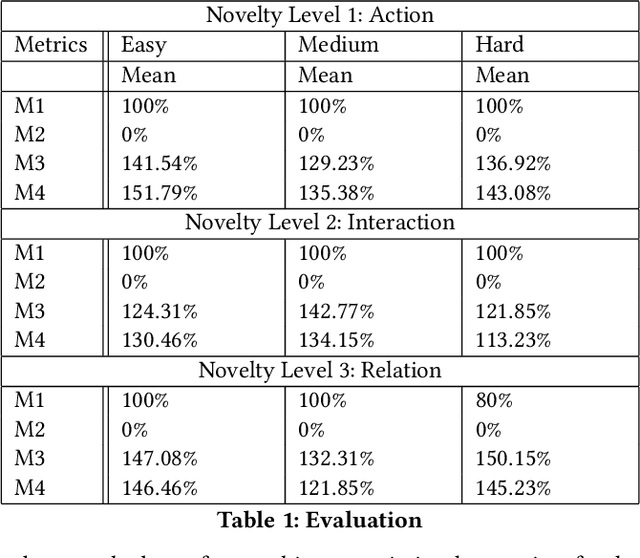
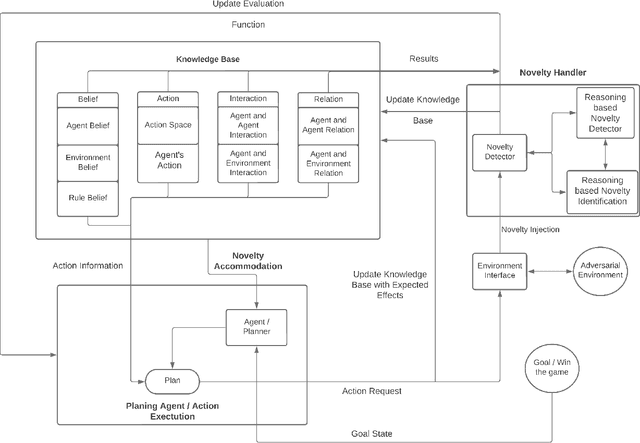
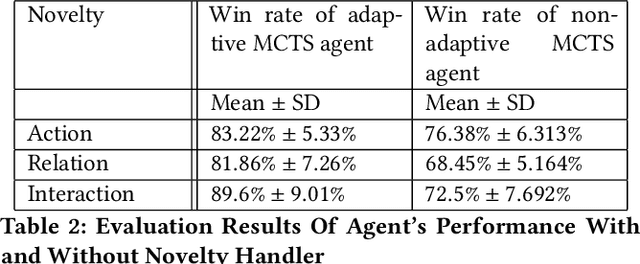
Learning to detect, characterize and accommodate novelties is a challenge that agents operating in open-world domains need to address to be able to guarantee satisfactory task performance. Certain novelties (e.g., changes in environment dynamics) can interfere with the performance or prevent agents from accomplishing task goals altogether. In this paper, we introduce general methods and architectural mechanisms for detecting and characterizing different types of novelties, and for building an appropriate adaptive model to accommodate them utilizing logical representations and reasoning methods. We demonstrate the effectiveness of the proposed methods in evaluations performed by a third party in the adversarial multi-agent board game Monopoly. The results show high novelty detection and accommodation rates across a variety of novelty types, including changes to the rules of the game, as well as changes to the agent's action capabilities.
pyRDDLGym: From RDDL to Gym Environments
Nov 14, 2022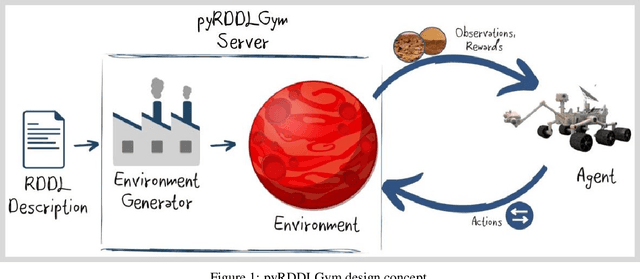



We present pyRDDLGym, a Python framework for auto-generation of OpenAI Gym environments from RDDL declerative description. The discrete time step evolution of variables in RDDL is described by conditional probability functions, which fits naturally into the Gym step scheme. Furthermore, since RDDL is a lifted description, the modification and scaling up of environments to support multiple entities and different configurations becomes trivial rather than a tedious process prone to errors. We hope that pyRDDLGym will serve as a new wind in the reinforcement learning community by enabling easy and rapid development of benchmarks due to the unique expressive power of RDDL. By providing explicit access to the model in the RDDL description, pyRDDLGym can also facilitate research on hybrid approaches for learning from interaction while leveraging model knowledge. We present the design and built-in examples of pyRDDLGym, and the additions made to the RDDL language that were incorporated into the framework.