 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTITCH-OPE: Trajectory Stitching with Guided Diffusion for Off-Policy Evaluation
May 27, 2025Off-policy evaluation (OPE) estimates the performance of a target policy using offline data collected from a behavior policy, and is crucial in domains such as robotics or healthcare where direct interaction with the environment is costly or unsafe. Existing OPE methods are ineffective for high-dimensional, long-horizon problems, due to exponential blow-ups in variance from importance weighting or compounding errors from learned dynamics models. To address these challenges, we propose STITCH-OPE, a model-based generative framework that leverages denoising diffusion for long-horizon OPE in high-dimensional state and action spaces. Starting with a diffusion model pre-trained on the behavior data, STITCH-OPE generates synthetic trajectories from the target policy by guiding the denoising process using the score function of the target policy. STITCH-OPE proposes two technical innovations that make it advantageous for OPE: (1) prevents over-regularization by subtracting the score of the behavior policy during guidance, and (2) generates long-horizon trajectories by stitching partial trajectories together end-to-end. We provide a theoretical guarantee that under mild assumptions, these modifications result in an exponential reduction in variance versus long-horizon trajectory diffusion. Experiments on the D4RL and OpenAI Gym benchmarks show substantial improvement in mean squared error, correlation, and regret metrics compared to state-of-the-art OPE methods.
Constraint-Generation Policy Optimization (CGPO): Nonlinear Programming for Policy Optimization in Mixed Discrete-Continuous MDPs
Jan 20, 2024



We propose Constraint-Generation Policy Optimization (CGPO) for optimizing policy parameters within compact and interpretable policy classes for mixed discrete-continuous Markov Decision Processes (DC-MDPs). CGPO is not only able to provide bounded policy error guarantees over an infinite range of initial states for many DC-MDPs with expressive nonlinear dynamics, but it can also provably derive optimal policies in cases where it terminates with zero error. Furthermore, CGPO can generate worst-case state trajectories to diagnose policy deficiencies and provide counterfactual explanations of optimal actions. To achieve such results, CGPO proposes a bi-level mixed-integer nonlinear optimization framework for optimizing policies within defined expressivity classes (i.e. piecewise (non)-linear) and reduces it to an optimal constraint generation methodology that adversarially generates worst-case state trajectories. Furthermore, leveraging modern nonlinear optimizers, CGPO can obtain solutions with bounded optimality gap guarantees. We handle stochastic transitions through explicit marginalization (where applicable) or chance-constraints, providing high-probability policy performance guarantees. We also present a road-map for understanding the computational complexities associated with different expressivity classes of policy, reward, and transition dynamics. We experimentally demonstrate the applicability of CGPO in diverse domains, including inventory control, management of a system of water reservoirs, and physics control. In summary, we provide a solution for deriving structured, compact, and explainable policies with bounded performance guarantees, enabling worst-case scenario generation and counterfactual policy diagnostics.
Thompson Sampling for Parameterized Markov Decision Processes with Uninformative Actions
May 13, 2023

We study parameterized MDPs (PMDPs) in which the key parameters of interest are unknown and must be learned using Bayesian inference. One key defining feature of such models is the presence of "uninformative" actions that provide no information about the unknown parameters. We contribute a set of assumptions for PMDPs under which Thompson sampling guarantees an asymptotically optimal expected regret bound of $O(T^{-1})$, which are easily verified for many classes of problems such as queuing, inventory control, and dynamic pricing.
pyRDDLGym: From RDDL to Gym Environments
Nov 14, 2022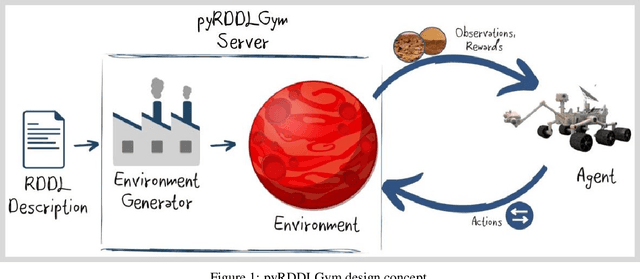



We present pyRDDLGym, a Python framework for auto-generation of OpenAI Gym environments from RDDL declerative description. The discrete time step evolution of variables in RDDL is described by conditional probability functions, which fits naturally into the Gym step scheme. Furthermore, since RDDL is a lifted description, the modification and scaling up of environments to support multiple entities and different configurations becomes trivial rather than a tedious process prone to errors. We hope that pyRDDLGym will serve as a new wind in the reinforcement learning community by enabling easy and rapid development of benchmarks due to the unique expressive power of RDDL. By providing explicit access to the model in the RDDL description, pyRDDLGym can also facilitate research on hybrid approaches for learning from interaction while leveraging model knowledge. We present the design and built-in examples of pyRDDLGym, and the additions made to the RDDL language that were incorporated into the framework.
Conservative Bayesian Model-Based Value Expansion for Offline Policy Optimization
Oct 07, 2022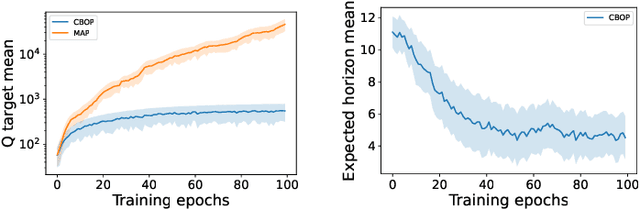
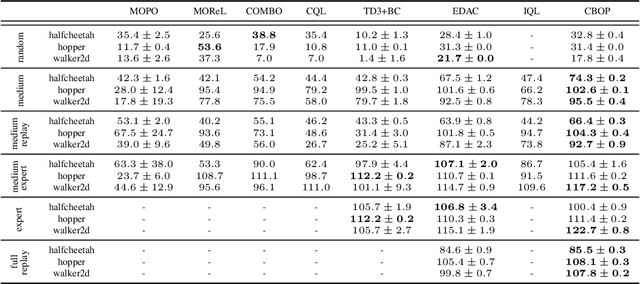
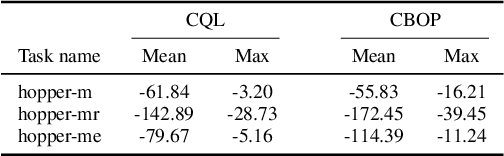
Offline reinforcement learning (RL) addresses the problem of learning a performant policy from a fixed batch of data collected by following some behavior policy. Model-based approaches are particularly appealing in the offline setting since they can extract more learning signals from the logged dataset by learning a model of the environment. However, the performance of existing model-based approaches falls short of model-free counterparts, due to the compounding of estimation errors in the learned model. Driven by this observation, we argue that it is critical for a model-based method to understand when to trust the model and when to rely on model-free estimates, and how to act conservatively w.r.t. both. To this end, we derive an elegant and simple methodology called conservative Bayesian model-based value expansion for offline policy optimization (CBOP), that trades off model-free and model-based estimates during the policy evaluation step according to their epistemic uncertainties, and facilitates conservatism by taking a lower bound on the Bayesian posterior value estimate. On the standard D4RL continuous control tasks, we find that our method significantly outperforms previous model-based approaches: e.g., MOPO by $116.4$%, MOReL by $23.2$% and COMBO by $23.7$%. Further, CBOP achieves state-of-the-art performance on $11$ out of $18$ benchmark datasets while doing on par on the remaining datasets.
RAPTOR: End-to-end Risk-Aware MDP Planning and Policy Learning by Backpropagation
Jun 14, 2021

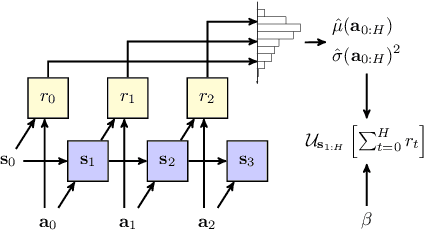

Planning provides a framework for optimizing sequential decisions in complex environments. Recent advances in efficient planning in deterministic or stochastic high-dimensional domains with continuous action spaces leverage backpropagation through a model of the environment to directly optimize actions. However, existing methods typically not take risk into account when optimizing in stochastic domains, which can be incorporated efficiently in MDPs by optimizing the entropic utility of returns. We bridge this gap by introducing Risk-Aware Planning using PyTorch (RAPTOR), a novel framework for risk-sensitive planning through end-to-end optimization of the entropic utility objective. A key technical difficulty of our approach lies in that direct optimization of the entropic utility by backpropagation is impossible due to the presence of environment stochasticity. The novelty of RAPTOR lies in the reparameterization of the state distribution, which makes it possible to apply stochastic backpropagatation through sufficient statistics of the entropic utility computed from forward-sampled trajectories. The direct optimization of this empirical objective in an end-to-end manner is called the risk-averse straight-line plan, which commits to a sequence of actions in advance and can be sub-optimal in highly stochastic domains. We address this shortcoming by optimizing for risk-aware Deep Reactive Policies (RaDRP) in our framework. We evaluate and compare these two forms of RAPTOR on three highly stochastic do-mains, including nonlinear navigation, HVAC control, and linear reservoir control, demonstrating the ability to manage risk in complex MDPs.
Risk-Aware Transfer in Reinforcement Learning using Successor Features
May 28, 2021
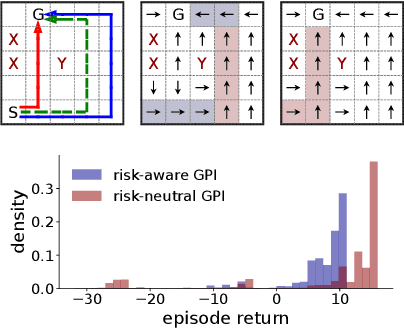
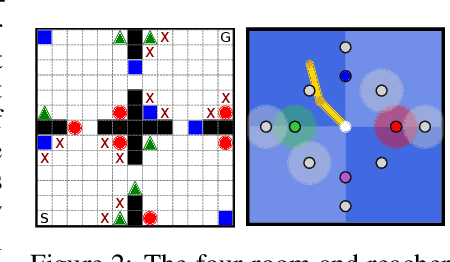

Sample efficiency and risk-awareness are central to the development of practical reinforcement learning (RL) for complex decision-making. The former can be addressed by transfer learning and the latter by optimizing some utility function of the return. However, the problem of transferring skills in a risk-aware manner is not well-understood. In this paper, we address the problem of risk-aware policy transfer between tasks in a common domain that differ only in their reward functions, in which risk is measured by the variance of reward streams. Our approach begins by extending the idea of generalized policy improvement to maximize entropic utilities, thus extending policy improvement via dynamic programming to sets of policies and levels of risk-aversion. Next, we extend the idea of successor features (SF), a value function representation that decouples the environment dynamics from the rewards, to capture the variance of returns. Our resulting risk-aware successor features (RaSF) integrate seamlessly within the RL framework, inherit the superior task generalization ability of SFs, and incorporate risk-awareness into the decision-making. Experiments on a discrete navigation domain and control of a simulated robotic arm demonstrate the ability of RaSFs to outperform alternative methods including SFs, when taking the risk of the learned policies into account.
ε-BMC: A Bayesian Ensemble Approach to Epsilon-Greedy Exploration in Model-Free Reinforcement Learning
Jul 02, 2020
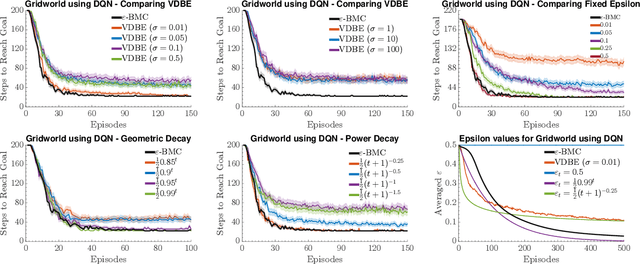

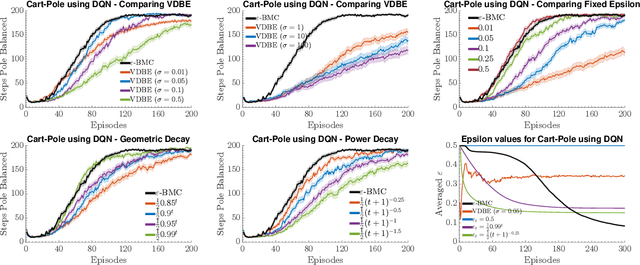
Resolving the exploration-exploitation trade-off remains a fundamental problem in the design and implementation of reinforcement learning (RL) algorithms. In this paper, we focus on model-free RL using the epsilon-greedy exploration policy, which despite its simplicity, remains one of the most frequently used forms of exploration. However, a key limitation of this policy is the specification of $\varepsilon$. In this paper, we provide a novel Bayesian perspective of $\varepsilon$ as a measure of the uniformity of the Q-value function. We introduce a closed-form Bayesian model update based on Bayesian model combination (BMC), based on this new perspective, which allows us to adapt $\varepsilon$ using experiences from the environment in constant time with monotone convergence guarantees. We demonstrate that our proposed algorithm, $\varepsilon$-\texttt{BMC}, efficiently balances exploration and exploitation on different problems, performing comparably or outperforming the best tuned fixed annealing schedules and an alternative data-dependent $\varepsilon$ adaptation scheme proposed in the literature.
Bayesian Experience Reuse for Learning from Multiple Demonstrators
Jun 10, 2020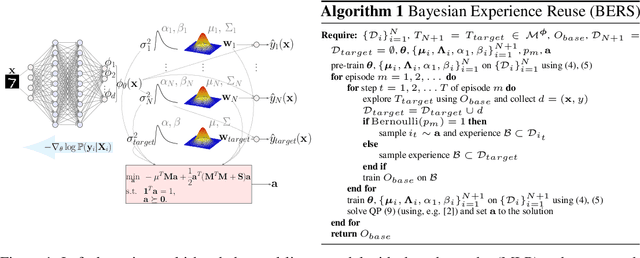
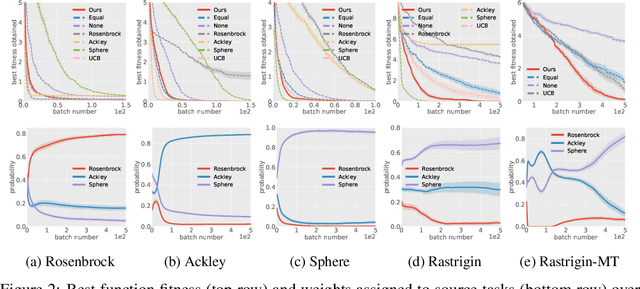
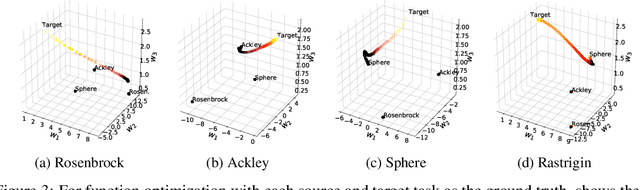
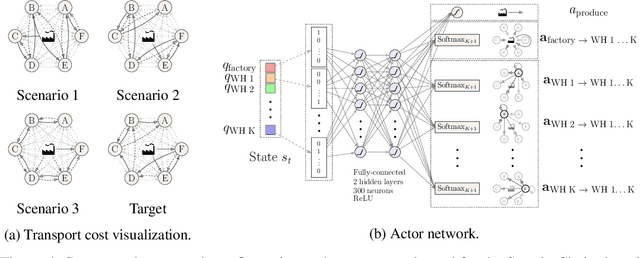
Learning from demonstrations (LfD) improves the exploration efficiency of a learning agent by incorporating demonstrations from experts. However, demonstration data can often come from multiple experts with conflicting goals, making it difficult to incorporate safely and effectively in online settings. We address this problem in the static and dynamic optimization settings by modelling the uncertainty in source and target task functions using normal-inverse-gamma priors, whose corresponding posteriors are, respectively, learned from demonstrations and target data using Bayesian neural networks with shared features. We use this learned belief to derive a quadratic programming problem whose solution yields a probability distribution over the expert models. Finally, we propose Bayesian Experience Reuse (BERS) to sample demonstrations in accordance with this distribution and reuse them directly in new tasks. We demonstrate the effectiveness of this approach for static optimization of smooth functions, and transfer learning in a high-dimensional supply chain problem with cost uncertainty.
Contextual Policy Reuse using Deep Mixture Models
Feb 29, 2020
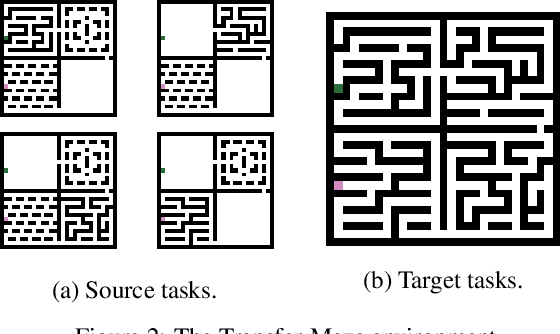
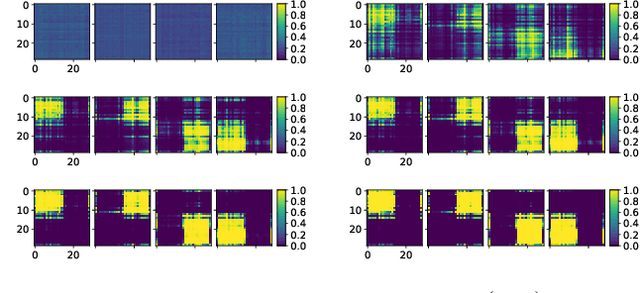
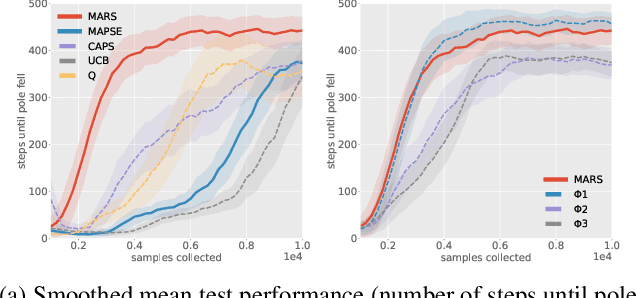
Reinforcement learning methods that consider the context, or current state, when selecting source policies for transfer have been shown to outperform context-free approaches. However, existing work typically tailors the approach to a specific learning algorithm such as Q-learning, and it is often difficult to interpret and validate the knowledge transferred between tasks. In this paper, we assume knowledge of estimated source task dynamics and policies, and common goals between tasks. We introduce a novel deep mixture model formulation for learning a state-dependent prior over source task dynamics that matches the target dynamics using only state trajectories obtained while learning the target policy. The mixture model is easy to train and interpret, is compatible with most reinforcement learning algorithms, and complements existing work by leveraging knowledge of source dynamics rather than Q-values. We then show how the trained mixture model can be incorporated into standard policy reuse frameworks, and demonstrate its effectiveness on benchmarks from OpenAI-Gym.