 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGround Plane Projection for Improved Traffic Analytics at Intersections
Nov 15, 2025Accurate turning movement counts at intersections are important for signal control, traffic management and urban planning. Computer vision systems for automatic turning movement counts typically rely on visual analysis in the image plane of an infrastructure camera. Here we explore potential advantages of back-projecting vehicles detected in one or more infrastructure cameras to the ground plane for analysis in real-world 3D coordinates. For single-camera systems we find that back-projection yields more accurate trajectory classification and turning movement counts. We further show that even higher accuracy can be achieved through weak fusion of back-projected detections from multiple cameras. These results suggeest that traffic should be analyzed on the ground plane, not the image plane
Multi-hop Upstream Preemptive Traffic Signal Control with Deep Reinforcement Learning
Nov 10, 2024

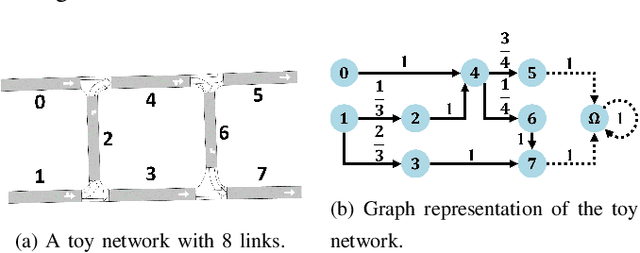
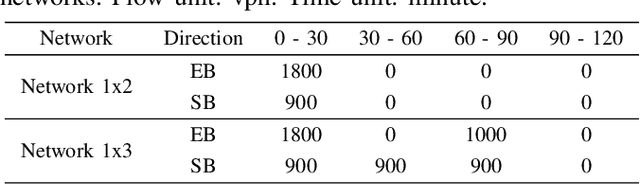
Traffic signal control is crucial for managing congestion in urban networks. Existing myopic pressure-based control methods focus only on immediate upstream links, leading to suboptimal green time allocation and increased network delays. Effective signal control, however, inherently requires a broader spatial scope, as traffic conditions further upstream can significantly impact traffic at the current location. This paper introduces a novel concept based on the Markov chain theory, namely multi-hop upstream pressure, that generalizes the conventional pressure to account for traffic conditions beyond the immediate upstream links. This farsighted and compact metric informs the deep reinforcement learning agent to preemptively clear the present queues, guiding the agent to optimize signal timings with a broader spatial awareness. Simulations on synthetic and realistic (Toronto) scenarios demonstrate controllers utilizing multi-hop upstream pressure significantly reduce overall network delay by prioritizing traffic movements based on a broader understanding of upstream congestion.
Mitigating Partial Observability in Adaptive Traffic Signal Control with Transformers
Sep 16, 2024


Efficient traffic signal control is essential for managing urban transportation, minimizing congestion, and improving safety and sustainability. Reinforcement Learning (RL) has emerged as a promising approach to enhancing adaptive traffic signal control (ATSC) systems, allowing controllers to learn optimal policies through interaction with the environment. However, challenges arise due to partial observability (PO) in traffic networks, where agents have limited visibility, hindering effectiveness. This paper presents the integration of Transformer-based controllers into ATSC systems to address PO effectively. We propose strategies to enhance training efficiency and effectiveness, demonstrating improved coordination capabilities in real-world scenarios. The results showcase the Transformer-based model's ability to capture significant information from historical observations, leading to better control policies and improved traffic flow. This study highlights the potential of leveraging the advanced Transformer architecture to enhance urban transportation management.
Generalized Multi-hop Traffic Pressure for Heterogeneous Traffic Perimeter Control
Sep 01, 2024



Perimeter control prevents loss of traffic network capacity due to congestion in urban areas. Homogeneous perimeter control allows all access points to a protected region to have the same maximal permitted inflow. However, homogeneous perimeter control performs poorly when the congestion in the protected region is heterogeneous (e.g., imbalanced demand) since the homogeneous perimeter control does not consider location-specific traffic conditions around the perimeter. When the protected region has spatially heterogeneous congestion, it can often make sense to modulate the perimeter inflow rate to be higher near low-density regions and vice versa for high-density regions. To assist with this modulation, we can leverage the concept of 1-hop traffic pressure to measure intersection-level traffic congestion. However, as we show, 1-hop pressure turns out to be too spatially myopic for perimeter control and hence we formulate multi-hop generalizations of pressure that look ``deeper'' inside the perimeter beyond the entry intersection. In addition, we formulate a simple heterogeneous perimeter control methodology that can leverage this novel multi-hop pressure to redistribute the total permitted inflow provided by the homogeneous perimeter controller. Experimental results show that our heterogeneous perimeter control policies leveraging multi-hop pressure significantly outperform homogeneous perimeter control in scenarios where the origin-destination flows are highly imbalanced with high spatial heterogeneity.
SECRM-2D: RL-Based Efficient and Comfortable Route-Following Autonomous Driving with Analytic Safety Guarantees
Jul 23, 2024



Over the last decade, there has been increasing interest in autonomous driving systems. Reinforcement Learning (RL) shows great promise for training autonomous driving controllers, being able to directly optimize a combination of criteria such as efficiency comfort, and stability. However, RL- based controllers typically offer no safety guarantees, making their readiness for real deployment questionable. In this paper, we propose SECRM-2D (the Safe, Efficient and Comfortable RL- based driving Model with Lane-Changing), an RL autonomous driving controller (both longitudinal and lateral) that balances optimization of efficiency and comfort and follows a fixed route, while being subject to hard analytic safety constraints. The aforementioned safety constraints are derived from the criterion that the follower vehicle must have sufficient headway to be able to avoid a crash if the leader vehicle brakes suddenly. We evaluate SECRM-2D against several learning and non-learning baselines in simulated test scenarios, including freeway driving, exiting, merging, and emergency braking. Our results confirm that representative previously-published RL AV controllers may crash in both training and testing, even if they are optimizing a safety objective. By contrast, our controller SECRM-2D is successful in avoiding crashes during both training and testing, improves over the baselines in measures of efficiency and comfort, and is more faithful in following the prescribed route. In addition, we achieve a good theoretical understanding of the longitudinal steady-state of a collection of SECRM-2D vehicles.
Revisiting Random Forests in a Comparative Evaluation of Graph Convolutional Neural Network Variants for Traffic Prediction
May 30, 2023Traffic prediction is a spatiotemporal predictive task that plays an essential role in intelligent transportation systems. Today, graph convolutional neural networks (GCNNs) have become the prevailing models in the traffic prediction literature since they excel at extracting spatial correlations. In this work, we classify the components of successful GCNN prediction models and analyze the effects of matrix factorization, attention mechanism, and weight sharing on their performance. Furthermore, we compare these variations against random forests, a traditional regression method that predates GCNNs by over 15 years. We evaluated these methods using simulated data of two regions in Toronto as well as real-world sensor data from selected California highways. We found that incorporating matrix factorization, attention, and location-specific model weights either individually or collectively into GCNNs can result in a better overall performance. Moreover, although random forest regression is a less compact model, it matches or exceeds the performance of all variations of GCNNs in our experiments. This suggests that the current graph convolutional methods may not be the best approach to traffic prediction and there is still room for improvement. Finally, our findings also suggest that for future research on GCNN for traffic prediction to be credible, researchers must include performance comparison to random forests.
Perimeter Control Using Deep Reinforcement Learning: A Model-free Approach towards Homogeneous Flow Rate Optimization
May 29, 2023



Perimeter control maintains high traffic efficiency within protected regions by controlling transfer flows among regions to ensure that their traffic densities are below critical values. Existing approaches can be categorized as either model-based or model-free, depending on whether they rely on network transmission models (NTMs) and macroscopic fundamental diagrams (MFDs). Although model-based approaches are more data efficient and have performance guarantees, they are inherently prone to model bias and inaccuracy. For example, NTMs often become imprecise for a large number of protected regions, and MFDs can exhibit scatter and hysteresis that are not captured in existing model-based works. Moreover, no existing studies have employed reinforcement learning for homogeneous flow rate optimization in microscopic simulation, where spatial characteristics, vehicle-level information, and metering realizations -- often overlooked in macroscopic simulations -- are taken into account. To circumvent issues of model-based approaches and macroscopic simulation, we propose a model-free deep reinforcement learning approach that optimizes the flow rate homogeneously at the perimeter at the microscopic level. Results demonstrate that our model-free reinforcement learning approach without any knowledge of NTMs or MFDs can compete and match the performance of a model-based approach, and exhibits enhanced generalizability and scalability.
A Critical Review of Traffic Signal Control and A Novel Unified View of Reinforcement Learning and Model Predictive Control Approaches for Adaptive Traffic Signal Control
Nov 26, 2022Recent years have witnessed substantial growth in adaptive traffic signal control (ATSC) methodologies that improve transportation network efficiency, especially in branches leveraging artificial intelligence based optimization and control algorithms such as reinforcement learning as well as conventional model predictive control. However, lack of cross-domain analysis and comparison of the effectiveness of applied methods in ATSC research limits our understanding of existing challenges and research directions. This chapter proposes a novel unified view of modern ATSCs to identify common ground as well as differences and shortcomings of existing methodologies with the ultimate goal to facilitate cross-fertilization and advance the state-of-the-art. The unified view applies the mathematical language of the Markov decision process, describes the process of controller design from both the world (problem) and solution modeling perspectives. The unified view also analyses systematic issues commonly ignored in existing studies and suggests future potential directions to resolve these issues.
Conservative Bayesian Model-Based Value Expansion for Offline Policy Optimization
Oct 07, 2022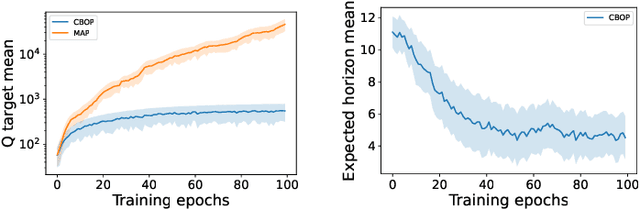
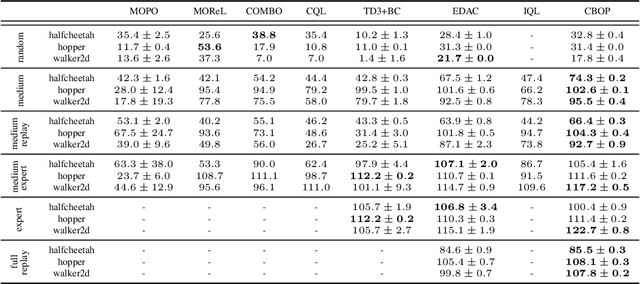
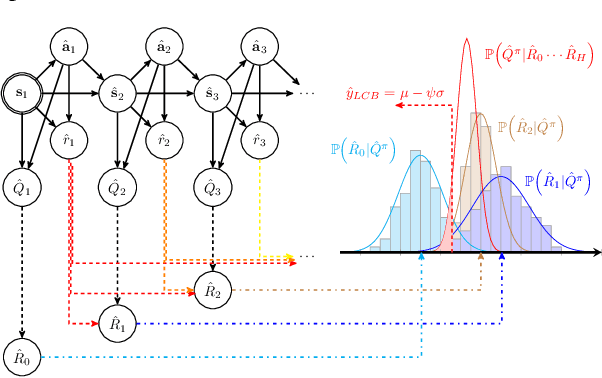
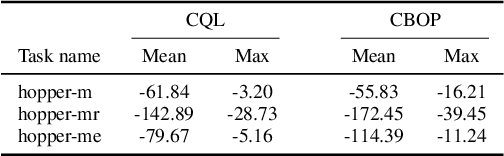
Offline reinforcement learning (RL) addresses the problem of learning a performant policy from a fixed batch of data collected by following some behavior policy. Model-based approaches are particularly appealing in the offline setting since they can extract more learning signals from the logged dataset by learning a model of the environment. However, the performance of existing model-based approaches falls short of model-free counterparts, due to the compounding of estimation errors in the learned model. Driven by this observation, we argue that it is critical for a model-based method to understand when to trust the model and when to rely on model-free estimates, and how to act conservatively w.r.t. both. To this end, we derive an elegant and simple methodology called conservative Bayesian model-based value expansion for offline policy optimization (CBOP), that trades off model-free and model-based estimates during the policy evaluation step according to their epistemic uncertainties, and facilitates conservatism by taking a lower bound on the Bayesian posterior value estimate. On the standard D4RL continuous control tasks, we find that our method significantly outperforms previous model-based approaches: e.g., MOPO by $116.4$%, MOReL by $23.2$% and COMBO by $23.7$%. Further, CBOP achieves state-of-the-art performance on $11$ out of $18$ benchmark datasets while doing on par on the remaining datasets.
Bilateral Deep Reinforcement Learning Approach for Better-than-human Car Following Model
Mar 03, 2022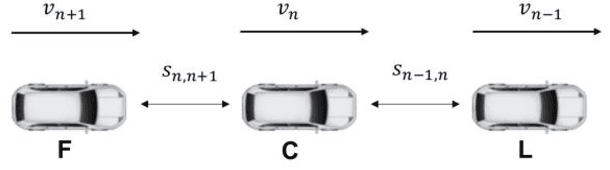
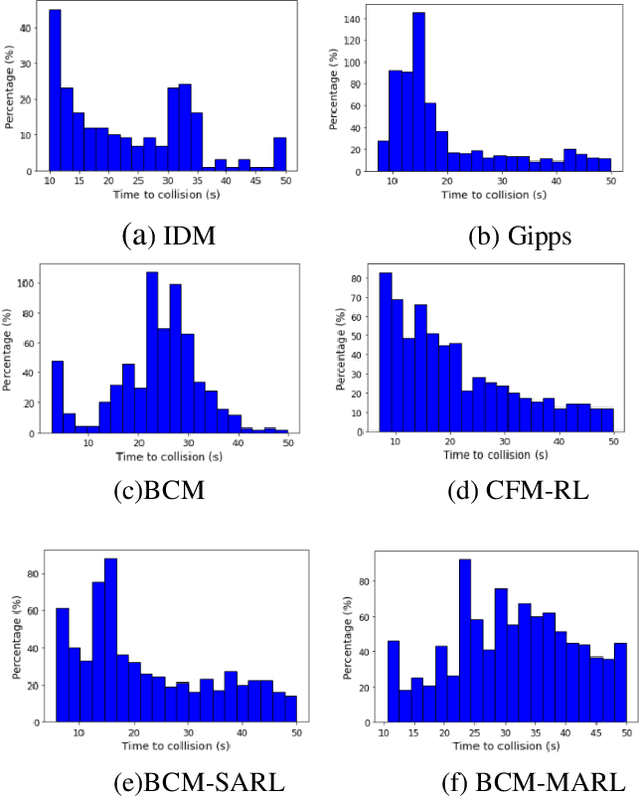
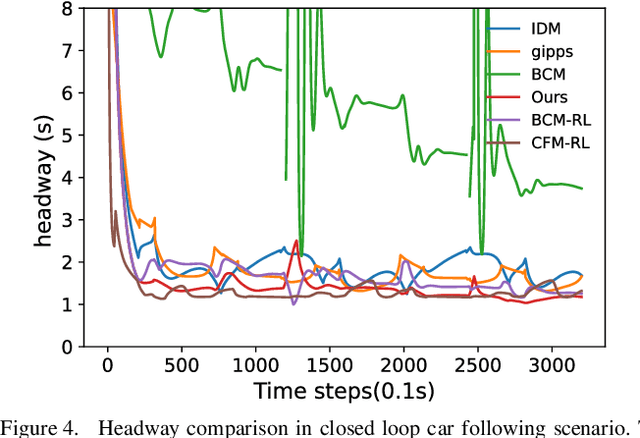
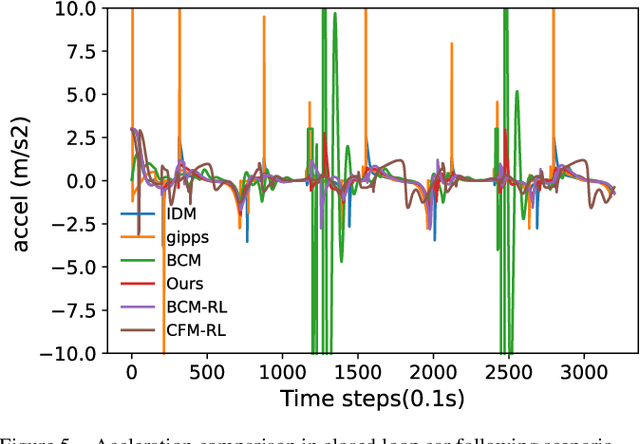
In the coming years and decades, autonomous vehicles (AVs) will become increasingly prevalent, offering new opportunities for safer and more convenient travel and potentially smarter traffic control methods exploiting automation and connectivity. Car following is a prime function in autonomous driving. Car following based on reinforcement learning has received attention in recent years with the goal of learning and achieving performance levels comparable to humans. However, most existing RL methods model car following as a unilateral problem, sensing only the vehicle ahead. Recent literature, however, Wang and Horn [16] has shown that bilateral car following that considers the vehicle ahead and the vehicle behind exhibits better system stability. In this paper we hypothesize that this bilateral car following can be learned using RL, while learning other goals such as efficiency maximisation, jerk minimization, and safety rewards leading to a learned model that outperforms human driving. We propose and introduce a Deep Reinforcement Learning (DRL) framework for car following control by integrating bilateral information into both state and reward function based on the bilateral control model (BCM) for car following control. Furthermore, we use a decentralized multi-agent reinforcement learning framework to generate the corresponding control action for each agent. Our simulation results demonstrate that our learned policy is better than the human driving policy in terms of (a) inter-vehicle headways, (b) average speed, (c) jerk, (d) Time to Collision (TTC) and (e) string stability.