 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Partial Observability in Adaptive Traffic Signal Control with Transformers
Sep 16, 2024


Efficient traffic signal control is essential for managing urban transportation, minimizing congestion, and improving safety and sustainability. Reinforcement Learning (RL) has emerged as a promising approach to enhancing adaptive traffic signal control (ATSC) systems, allowing controllers to learn optimal policies through interaction with the environment. However, challenges arise due to partial observability (PO) in traffic networks, where agents have limited visibility, hindering effectiveness. This paper presents the integration of Transformer-based controllers into ATSC systems to address PO effectively. We propose strategies to enhance training efficiency and effectiveness, demonstrating improved coordination capabilities in real-world scenarios. The results showcase the Transformer-based model's ability to capture significant information from historical observations, leading to better control policies and improved traffic flow. This study highlights the potential of leveraging the advanced Transformer architecture to enhance urban transportation management.
A Sequential Decision-Making Model for Perimeter Identification
Sep 04, 2024Perimeter identification involves ascertaining the boundaries of a designated area or zone, requiring traffic flow monitoring, control, or optimization. Various methodologies and technologies exist for accurately defining these perimeters; however, they often necessitate specialized equipment, precise mapping, or comprehensive data for effective problem delineation. In this study, we propose a sequential decision-making framework for perimeter search, designed to operate efficiently in real-time and require only publicly accessible information. We conceptualize the perimeter search as a game between a playing agent and an artificial environment, where the agent's objective is to identify the optimal perimeter by sequentially improving the current perimeter. We detail the model for the game and discuss its adaptability in determining the definition of an optimal perimeter. Ultimately, we showcase the model's efficacy through a real-world scenario, highlighting the identification of corresponding optimal perimeters.
Constraint-Generation Policy Optimization (CGPO): Nonlinear Programming for Policy Optimization in Mixed Discrete-Continuous MDPs
Jan 20, 2024



We propose Constraint-Generation Policy Optimization (CGPO) for optimizing policy parameters within compact and interpretable policy classes for mixed discrete-continuous Markov Decision Processes (DC-MDPs). CGPO is not only able to provide bounded policy error guarantees over an infinite range of initial states for many DC-MDPs with expressive nonlinear dynamics, but it can also provably derive optimal policies in cases where it terminates with zero error. Furthermore, CGPO can generate worst-case state trajectories to diagnose policy deficiencies and provide counterfactual explanations of optimal actions. To achieve such results, CGPO proposes a bi-level mixed-integer nonlinear optimization framework for optimizing policies within defined expressivity classes (i.e. piecewise (non)-linear) and reduces it to an optimal constraint generation methodology that adversarially generates worst-case state trajectories. Furthermore, leveraging modern nonlinear optimizers, CGPO can obtain solutions with bounded optimality gap guarantees. We handle stochastic transitions through explicit marginalization (where applicable) or chance-constraints, providing high-probability policy performance guarantees. We also present a road-map for understanding the computational complexities associated with different expressivity classes of policy, reward, and transition dynamics. We experimentally demonstrate the applicability of CGPO in diverse domains, including inventory control, management of a system of water reservoirs, and physics control. In summary, we provide a solution for deriving structured, compact, and explainable policies with bounded performance guarantees, enabling worst-case scenario generation and counterfactual policy diagnostics.
Perimeter Control Using Deep Reinforcement Learning: A Model-free Approach towards Homogeneous Flow Rate Optimization
May 29, 2023



Perimeter control maintains high traffic efficiency within protected regions by controlling transfer flows among regions to ensure that their traffic densities are below critical values. Existing approaches can be categorized as either model-based or model-free, depending on whether they rely on network transmission models (NTMs) and macroscopic fundamental diagrams (MFDs). Although model-based approaches are more data efficient and have performance guarantees, they are inherently prone to model bias and inaccuracy. For example, NTMs often become imprecise for a large number of protected regions, and MFDs can exhibit scatter and hysteresis that are not captured in existing model-based works. Moreover, no existing studies have employed reinforcement learning for homogeneous flow rate optimization in microscopic simulation, where spatial characteristics, vehicle-level information, and metering realizations -- often overlooked in macroscopic simulations -- are taken into account. To circumvent issues of model-based approaches and macroscopic simulation, we propose a model-free deep reinforcement learning approach that optimizes the flow rate homogeneously at the perimeter at the microscopic level. Results demonstrate that our model-free reinforcement learning approach without any knowledge of NTMs or MFDs can compete and match the performance of a model-based approach, and exhibits enhanced generalizability and scalability.
A2D: Anywhere Anytime Drumming
Apr 04, 2023
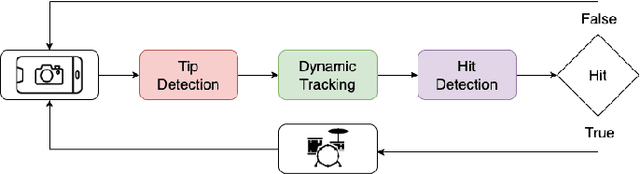
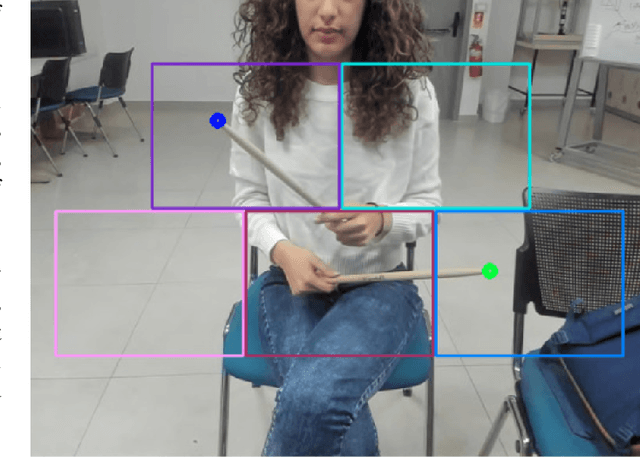

The drum kit, which has only been around for around 100 years, is a popular instrument in many music genres such as pop, rock, and jazz. However, the road to owning a kit is expensive, both financially and space-wise. Also, drums are more difficult to move around compared to other instruments, as they do not fit into a single bag. We propose a no-drums approach that uses only two sticks and a smartphone or a webcam to provide an air-drumming experience. The detection algorithm combines deep learning tools with tracking methods for an enhanced user experience. Based on both quantitative and qualitative testing with humans-in-the-loop, we show that our system has zero misses for beginner level play and negligible misses for advanced level play. Additionally, our limited human trials suggest potential directions for future research.
pyRDDLGym: From RDDL to Gym Environments
Nov 14, 2022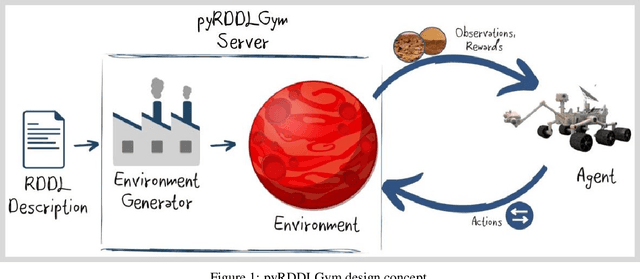



We present pyRDDLGym, a Python framework for auto-generation of OpenAI Gym environments from RDDL declerative description. The discrete time step evolution of variables in RDDL is described by conditional probability functions, which fits naturally into the Gym step scheme. Furthermore, since RDDL is a lifted description, the modification and scaling up of environments to support multiple entities and different configurations becomes trivial rather than a tedious process prone to errors. We hope that pyRDDLGym will serve as a new wind in the reinforcement learning community by enabling easy and rapid development of benchmarks due to the unique expressive power of RDDL. By providing explicit access to the model in the RDDL description, pyRDDLGym can also facilitate research on hybrid approaches for learning from interaction while leveraging model knowledge. We present the design and built-in examples of pyRDDLGym, and the additions made to the RDDL language that were incorporated into the framework.
SOLO: Search Online, Learn Offline for Combinatorial Optimization Problems
Apr 08, 2021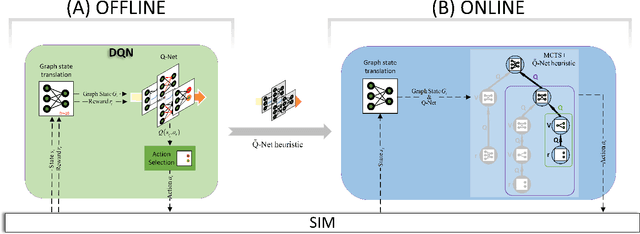
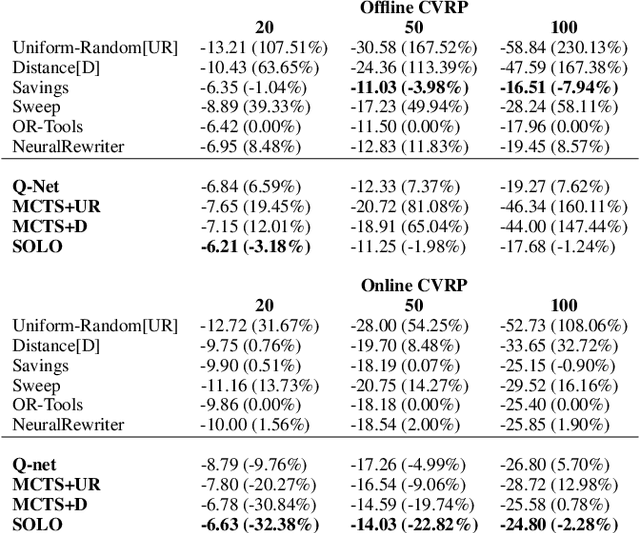

We study combinatorial problems with real world applications such as machine scheduling, routing, and assignment. We propose a method that combines Reinforcement Learning (RL) and planning. This method can equally be applied to both the offline, as well as online, variants of the combinatorial problem, in which the problem components (e.g., jobs in scheduling problems) are not known in advance, but rather arrive during the decision-making process. Our solution is quite generic, scalable, and leverages distributional knowledge of the problem parameters. We frame the solution process as an MDP, and take a Deep Q-Learning approach wherein states are represented as graphs, thereby allowing our trained policies to deal with arbitrary changes in a principled manner. Though learned policies work well in expectation, small deviations can have substantial negative effects in combinatorial settings. We mitigate these drawbacks by employing our graph-convolutional policies as non-optimal heuristics in a compatible search algorithm, Monte Carlo Tree Search, to significantly improve overall performance. We demonstrate our method on two problems: Machine Scheduling and Capacitated Vehicle Routing. We show that our method outperforms custom-tailored mathematical solvers, state of the art learning-based algorithms, and common heuristics, both in computation time and performance.
Learning Control for Air Hockey Striking using Deep Reinforcement Learning
Apr 25, 2017
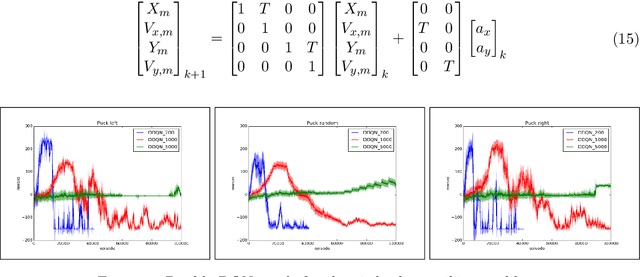
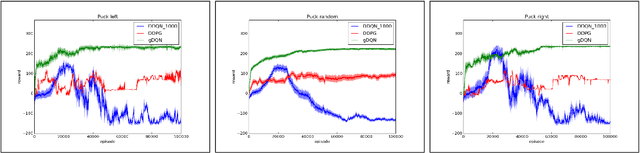
We consider the task of learning control policies for a robotic mechanism striking a puck in an air hockey game. The control signal is a direct command to the robot's motors. We employ a model free deep reinforcement learning framework to learn the motoric skills of striking the puck accurately in order to score. We propose certain improvements to the standard learning scheme which make the deep Q-learning algorithm feasible when it might otherwise fail. Our improvements include integrating prior knowledge into the learning scheme, and accounting for the changing distribution of samples in the experience replay buffer. Finally we present our simulation results for aimed striking which demonstrate the successful learning of this task, and the improvement in algorithm stability due to the proposed modifications.