 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAG2U -- Autonomous Grading Under Uncertainties
Aug 04, 2022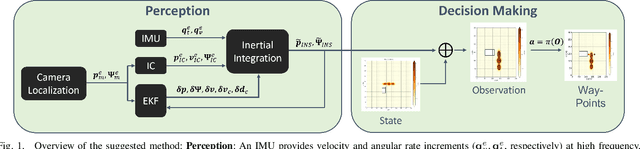

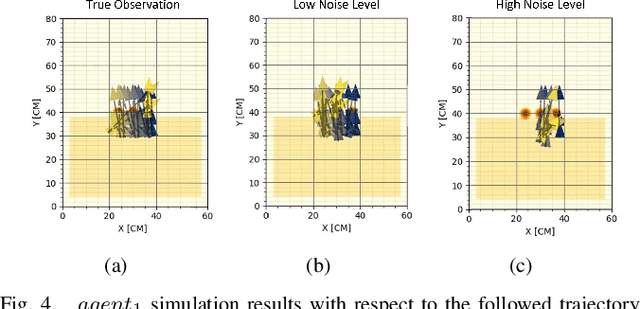
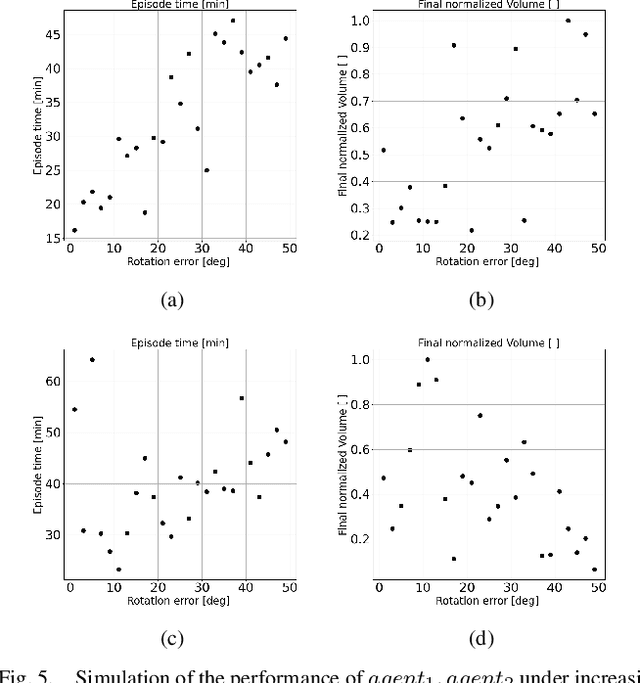
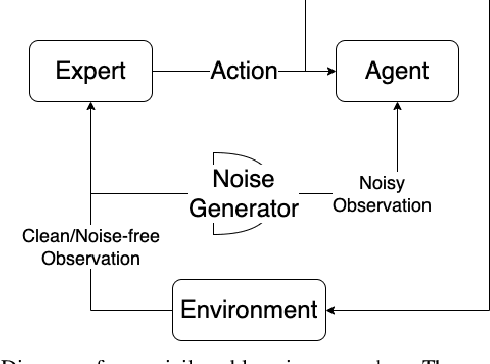
Surface grading, the process of leveling an uneven area containing pre-dumped sand piles, is an important task in the construction site pipeline. This labour-intensive process is often carried out by a dozer, a key machinery tool at any construction site. Current attempts to automate surface grading assume perfect localization. However, in real-world scenarios, this assumption fails, as agents are presented with imperfect perception, which leads to degraded performance. In this work, we address the problem of autonomous grading under uncertainties. First, we implement a simulation and a scaled real-world prototype environment to enable rapid policy exploration and evaluation in this setting. Second, we formalize the problem as a partially observable markov decision process and train an agent capable of handling such uncertainties. We show, through rigorous experiments, that an agent trained under perfect localization will suffer degraded performance when presented with localization uncertainties. However, an agent trained using our method will develop a more robust policy for addressing such errors and, consequently, exhibit a better grading performance.
Towards Autonomous Grading In The Real World
Jun 13, 2022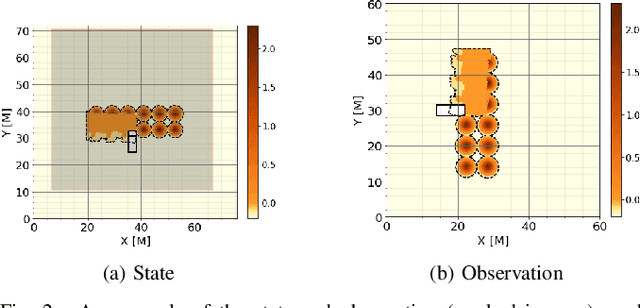
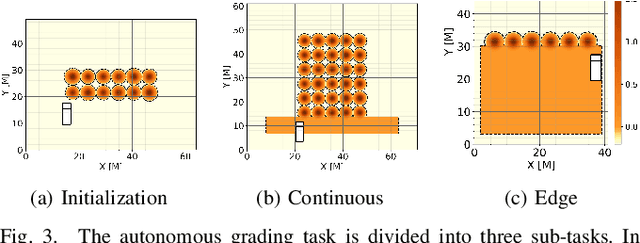
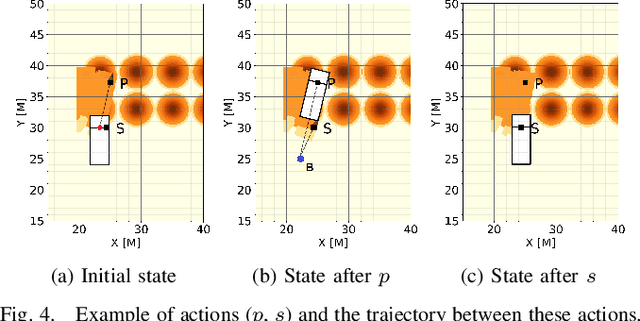
In this work, we aim to tackle the problem of autonomous grading, where a dozer is required to flatten an uneven area. In addition, we explore methods for bridging the gap between a simulated environment and real scenarios. We design both a realistic physical simulation and a scaled real prototype environment mimicking the real dozer dynamics and sensory information. We establish heuristics and learning strategies in order to solve the problem. Through extensive experimentation, we show that although heuristics are capable of tackling the problem in a clean and noise-free simulated environment, they fail catastrophically when facing real world scenarios. As the heuristics are capable of successfully solving the task in the simulated environment, we show they can be leveraged to guide a learning agent which can generalize and solve the task both in simulation and in a scaled prototype environment.
AGPNet -- Autonomous Grading Policy Network
Dec 20, 2021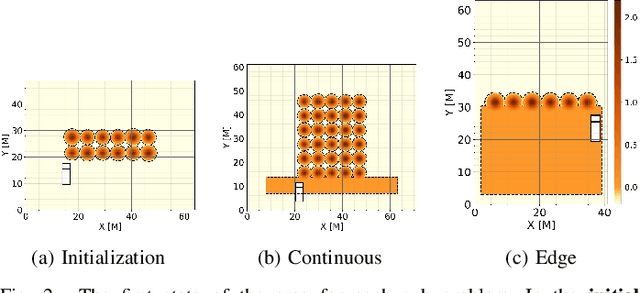
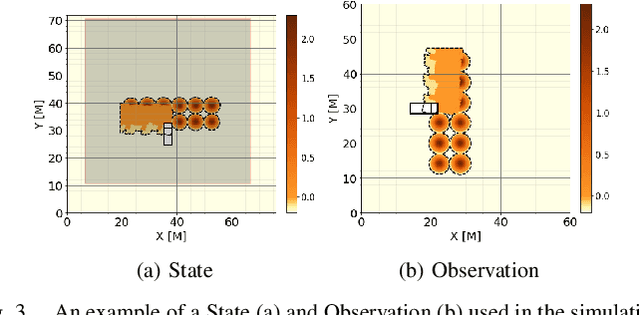
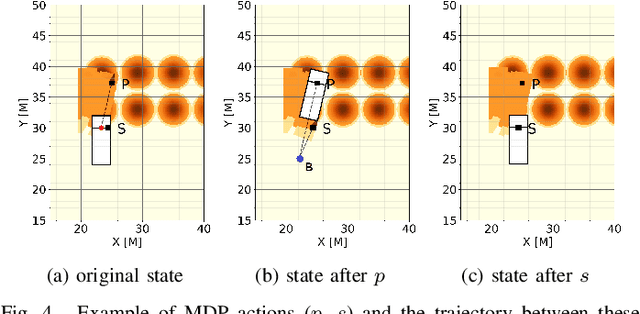

In this work, we establish heuristics and learning strategies for the autonomous control of a dozer grading an uneven area studded with sand piles. We formalize the problem as a Markov Decision Process, design a simulation which demonstrates agent-environment interactions and finally compare our simulator to a real dozer prototype. We use methods from reinforcement learning, behavior cloning and contrastive learning to train a hybrid policy. Our trained agent, AGPNet, reaches human-level performance and outperforms current state-of-the-art machine learning methods for the autonomous grading task. In addition, our agent is capable of generalizing from random scenarios to unseen real world problems.
SOLO: Search Online, Learn Offline for Combinatorial Optimization Problems
Apr 08, 2021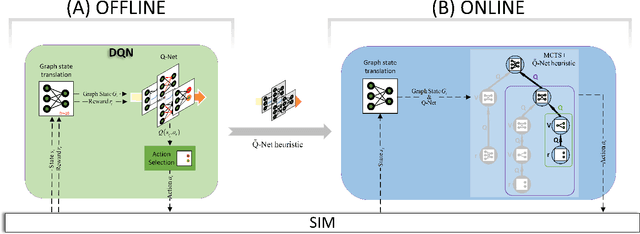
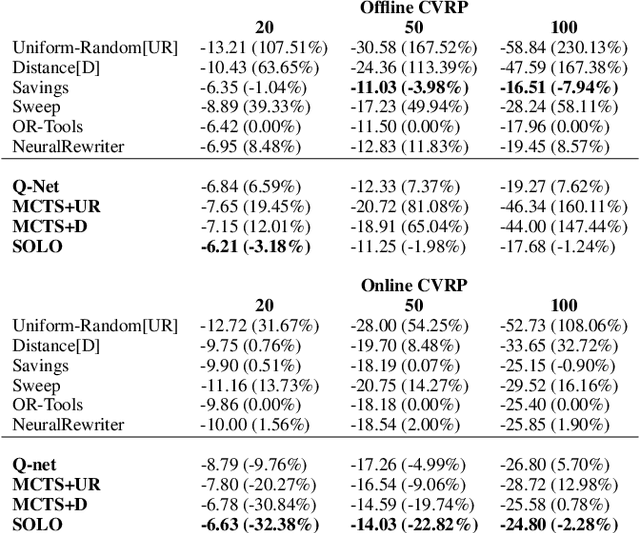
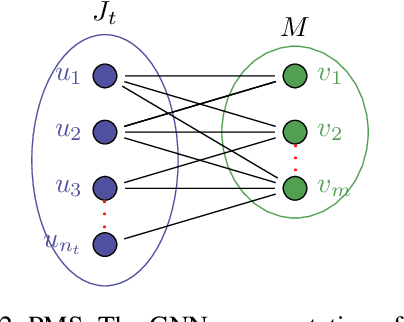

We study combinatorial problems with real world applications such as machine scheduling, routing, and assignment. We propose a method that combines Reinforcement Learning (RL) and planning. This method can equally be applied to both the offline, as well as online, variants of the combinatorial problem, in which the problem components (e.g., jobs in scheduling problems) are not known in advance, but rather arrive during the decision-making process. Our solution is quite generic, scalable, and leverages distributional knowledge of the problem parameters. We frame the solution process as an MDP, and take a Deep Q-Learning approach wherein states are represented as graphs, thereby allowing our trained policies to deal with arbitrary changes in a principled manner. Though learned policies work well in expectation, small deviations can have substantial negative effects in combinatorial settings. We mitigate these drawbacks by employing our graph-convolutional policies as non-optimal heuristics in a compatible search algorithm, Monte Carlo Tree Search, to significantly improve overall performance. We demonstrate our method on two problems: Machine Scheduling and Capacitated Vehicle Routing. We show that our method outperforms custom-tailored mathematical solvers, state of the art learning-based algorithms, and common heuristics, both in computation time and performance.