 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimodo: Scaling Controllable Human Motion Generation
Mar 16, 2026High-quality human motion data is becoming increasingly important for applications in robotics, simulation, and entertainment. Recent generative models offer a potential data source, enabling human motion synthesis through intuitive inputs like text prompts or kinematic constraints on poses. However, the small scale of public mocap datasets has limited the motion quality, control accuracy, and generalization of these models. In this work, we introduce Kimodo, an expressive and controllable kinematic motion diffusion model trained on 700 hours of optical motion capture data. Our model generates high-quality motions while being easily controlled through text and a comprehensive suite of kinematic constraints including full-body keyframes, sparse joint positions/rotations, 2D waypoints, and dense 2D paths. This is enabled through a carefully designed motion representation and two-stage denoiser architecture that decomposes root and body prediction to minimize motion artifacts while allowing for flexible constraint conditioning. Experiments on the large-scale mocap dataset justify key design decisions and analyze how the scaling of dataset size and model size affect performance.
MaskedManipulator: Versatile Whole-Body Control for Loco-Manipulation
May 25, 2025Humans interact with their world while leveraging precise full-body control to achieve versatile goals. This versatility allows them to solve long-horizon, underspecified problems, such as placing a cup in a sink, by seamlessly sequencing actions like approaching the cup, grasping, transporting it, and finally placing it in the sink. Such goal-driven control can enable new procedural tools for animation systems, enabling users to define partial objectives while the system naturally ``fills in'' the intermediate motions. However, while current methods for whole-body dexterous manipulation in physics-based animation achieve success in specific interaction tasks, they typically employ control paradigms (e.g., detailed kinematic motion tracking, continuous object trajectory following, or direct VR teleoperation) that offer limited versatility for high-level goal specification across the entire coupled human-object system. To bridge this gap, we present MaskedManipulator, a unified and generative policy developed through a two-stage learning approach. First, our system trains a tracking controller to physically reconstruct complex human-object interactions from large-scale human mocap datasets. This tracking controller is then distilled into MaskedManipulator, which provides users with intuitive control over both the character's body and the manipulated object. As a result, MaskedManipulator enables users to specify complex loco-manipulation tasks through intuitive high-level objectives (e.g., target object poses, key character stances), and MaskedManipulator then synthesizes the necessary full-body actions for a physically simulated humanoid to achieve these goals, paving the way for more interactive and life-like virtual characters.
Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning
May 18, 2025Human behavior is fundamentally shaped by visual perception -- our ability to interact with the world depends on actively gathering relevant information and adapting our movements accordingly. Behaviors like searching for objects, reaching, and hand-eye coordination naturally emerge from the structure of our sensory system. Inspired by these principles, we introduce Perceptive Dexterous Control (PDC), a framework for vision-driven dexterous whole-body control with simulated humanoids. PDC operates solely on egocentric vision for task specification, enabling object search, target placement, and skill selection through visual cues, without relying on privileged state information (e.g., 3D object positions and geometries). This perception-as-interface paradigm enables learning a single policy to perform multiple household tasks, including reaching, grasping, placing, and articulated object manipulation. We also show that training from scratch with reinforcement learning can produce emergent behaviors such as active search. These results demonstrate how vision-driven control and complex tasks induce human-like behaviors and can serve as the key ingredients in closing the perception-action loop for animation, robotics, and embodied AI.
Task Tokens: A Flexible Approach to Adapting Behavior Foundation Models
Mar 28, 2025Recent advancements in imitation learning have led to transformer-based behavior foundation models (BFMs) that enable multi-modal, human-like control for humanoid agents. While excelling at zero-shot generation of robust behaviors, BFMs often require meticulous prompt engineering for specific tasks, potentially yielding suboptimal results. We introduce "Task Tokens", a method to effectively tailor BFMs to specific tasks while preserving their flexibility. Our approach leverages the transformer architecture of BFMs to learn a new task-specific encoder through reinforcement learning, keeping the original BFM frozen. This allows incorporation of user-defined priors, balancing reward design and prompt engineering. By training a task encoder to map observations to tokens, used as additional BFM inputs, we guide performance improvement while maintaining the model's diverse control characteristics. We demonstrate Task Tokens' efficacy across various tasks, including out-of-distribution scenarios, and show their compatibility with other prompting modalities. Our results suggest that Task Tokens offer a promising approach for adapting BFMs to specific control tasks while retaining their generalization capabilities.
Improving Inverse Folding for Peptide Design with Diversity-regularized Direct Preference Optimization
Oct 25, 2024Inverse folding models play an important role in structure-based design by predicting amino acid sequences that fold into desired reference structures. Models like ProteinMPNN, a message-passing encoder-decoder model, are trained to reliably produce new sequences from a reference structure. However, when applied to peptides, these models are prone to generating repetitive sequences that do not fold into the reference structure. To address this, we fine-tune ProteinMPNN to produce diverse and structurally consistent peptide sequences via Direct Preference Optimization (DPO). We derive two enhancements to DPO: online diversity regularization and domain-specific priors. Additionally, we develop a new understanding on improving diversity in decoder models. When conditioned on OpenFold generated structures, our fine-tuned models achieve state-of-the-art structural similarity scores, improving base ProteinMPNN by at least 8%. Compared to standard DPO, our regularized method achieves up to 20% higher sequence diversity with no loss in structural similarity score.
MaskedMimic: Unified Physics-Based Character Control Through Masked Motion Inpainting
Sep 22, 2024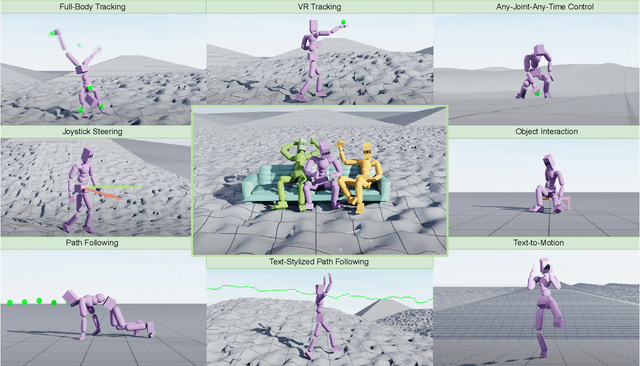
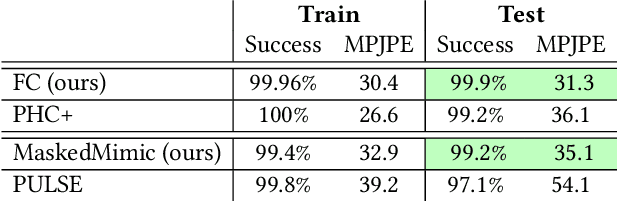

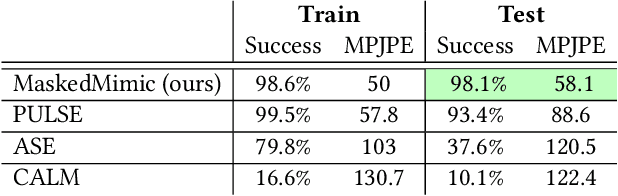
Crafting a single, versatile physics-based controller that can breathe life into interactive characters across a wide spectrum of scenarios represents an exciting frontier in character animation. An ideal controller should support diverse control modalities, such as sparse target keyframes, text instructions, and scene information. While previous works have proposed physically simulated, scene-aware control models, these systems have predominantly focused on developing controllers that each specializes in a narrow set of tasks and control modalities. This work presents MaskedMimic, a novel approach that formulates physics-based character control as a general motion inpainting problem. Our key insight is to train a single unified model to synthesize motions from partial (masked) motion descriptions, such as masked keyframes, objects, text descriptions, or any combination thereof. This is achieved by leveraging motion tracking data and designing a scalable training method that can effectively utilize diverse motion descriptions to produce coherent animations. Through this process, our approach learns a physics-based controller that provides an intuitive control interface without requiring tedious reward engineering for all behaviors of interest. The resulting controller supports a wide range of control modalities and enables seamless transitions between disparate tasks. By unifying character control through motion inpainting, MaskedMimic creates versatile virtual characters. These characters can dynamically adapt to complex scenes and compose diverse motions on demand, enabling more interactive and immersive experiences.
Learning to Move Like Professional Counter-Strike Players
Aug 25, 2024
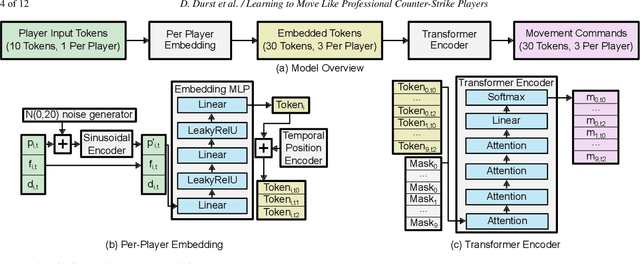
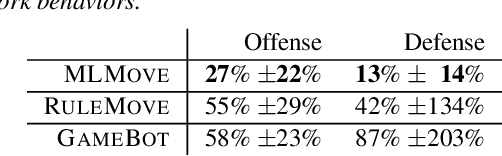
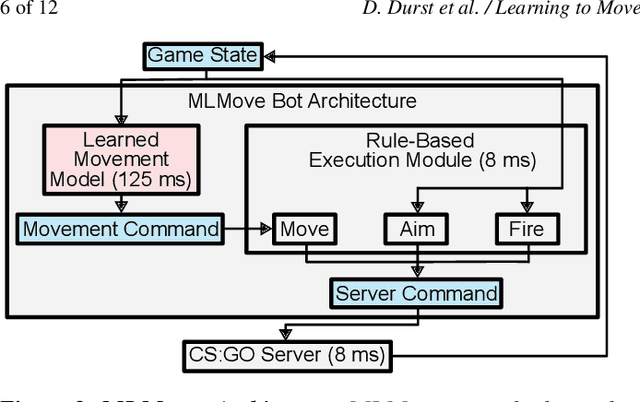
In multiplayer, first-person shooter games like Counter-Strike: Global Offensive (CS:GO), coordinated movement is a critical component of high-level strategic play. However, the complexity of team coordination and the variety of conditions present in popular game maps make it impractical to author hand-crafted movement policies for every scenario. We show that it is possible to take a data-driven approach to creating human-like movement controllers for CS:GO. We curate a team movement dataset comprising 123 hours of professional game play traces, and use this dataset to train a transformer-based movement model that generates human-like team movement for all players in a "Retakes" round of the game. Importantly, the movement prediction model is efficient. Performing inference for all players takes less than 0.5 ms per game step (amortized cost) on a single CPU core, making it plausible for use in commercial games today. Human evaluators assess that our model behaves more like humans than both commercially-available bots and procedural movement controllers scripted by experts (16% to 59% higher by TrueSkill rating of "human-like"). Using experiments involving in-game bot vs. bot self-play, we demonstrate that our model performs simple forms of teamwork, makes fewer common movement mistakes, and yields movement distributions, player lifetimes, and kill locations similar to those observed in professional CS:GO match play.
* The project website is at https://davidbdurst.com/mlmove/
Gradient Boosting Reinforcement Learning
Jul 11, 2024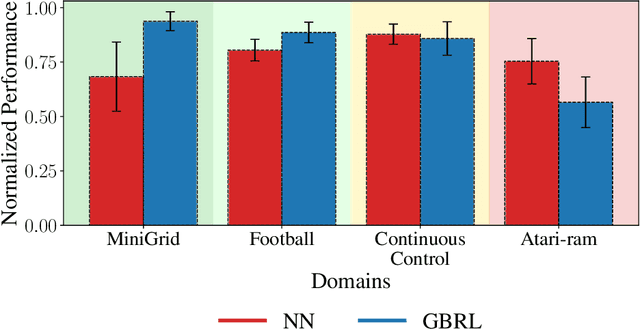
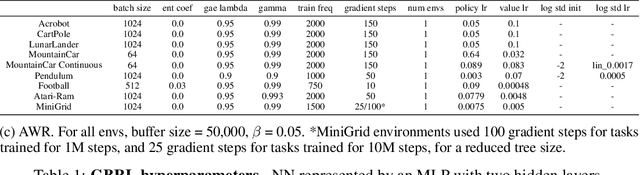
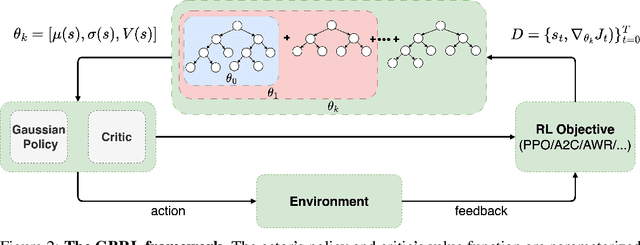

Neural networks (NN) achieve remarkable results in various tasks, but lack key characteristics: interpretability, support for categorical features, and lightweight implementations suitable for edge devices. While ongoing efforts aim to address these challenges, Gradient Boosting Trees (GBT) inherently meet these requirements. As a result, GBTs have become the go-to method for supervised learning tasks in many real-world applications and competitions. However, their application in online learning scenarios, notably in reinforcement learning (RL), has been limited. In this work, we bridge this gap by introducing Gradient-Boosting RL (GBRL), a framework that extends the advantages of GBT to the RL domain. Using the GBRL framework, we implement various actor-critic algorithms and compare their performance with their NN counterparts. Inspired by shared backbones in NN we introduce a tree-sharing approach for policy and value functions with distinct learning rates, enhancing learning efficiency over millions of interactions. GBRL achieves competitive performance across a diverse array of tasks, excelling in domains with structured or categorical features. Additionally, we present a high-performance, GPU-accelerated implementation that integrates seamlessly with widely-used RL libraries (available at https://github.com/NVlabs/gbrl). GBRL expands the toolkit for RL practitioners, demonstrating the viability and promise of GBT within the RL paradigm, particularly in domains characterized by structured or categorical features.
SMPLOlympics: Sports Environments for Physically Simulated Humanoids
Jun 28, 2024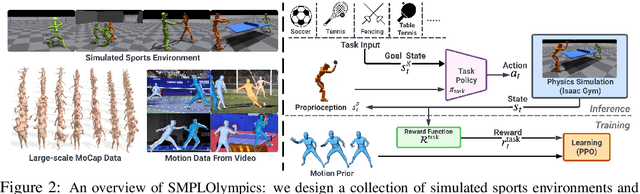
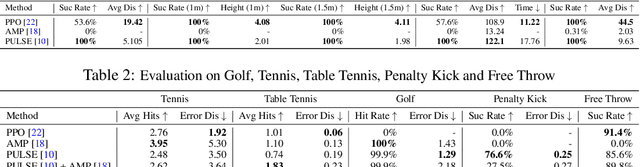

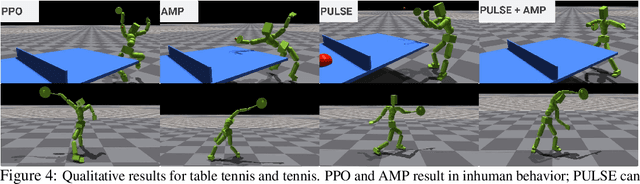
We present SMPLOlympics, a collection of physically simulated environments that allow humanoids to compete in a variety of Olympic sports. Sports simulation offers a rich and standardized testing ground for evaluating and improving the capabilities of learning algorithms due to the diversity and physically demanding nature of athletic activities. As humans have been competing in these sports for many years, there is also a plethora of existing knowledge on the preferred strategy to achieve better performance. To leverage these existing human demonstrations from videos and motion capture, we design our humanoid to be compatible with the widely-used SMPL and SMPL-X human models from the vision and graphics community. We provide a suite of individual sports environments, including golf, javelin throw, high jump, long jump, and hurdling, as well as competitive sports, including both 1v1 and 2v2 games such as table tennis, tennis, fencing, boxing, soccer, and basketball. Our analysis shows that combining strong motion priors with simple rewards can result in human-like behavior in various sports. By providing a unified sports benchmark and baseline implementation of state and reward designs, we hope that SMPLOlympics can help the control and animation communities achieve human-like and performant behaviors.
PlaMo: Plan and Move in Rich 3D Physical Environments
Jun 26, 2024Controlling humanoids in complex physically simulated worlds is a long-standing challenge with numerous applications in gaming, simulation, and visual content creation. In our setup, given a rich and complex 3D scene, the user provides a list of instructions composed of target locations and locomotion types. To solve this task we present PlaMo, a scene-aware path planner and a robust physics-based controller. The path planner produces a sequence of motion paths, considering the various limitations the scene imposes on the motion, such as location, height, and speed. Complementing the planner, our control policy generates rich and realistic physical motion adhering to the plan. We demonstrate how the combination of both modules enables traversing complex landscapes in diverse forms while responding to real-time changes in the environment. Video: https://youtu.be/wWlqSQlRZ9M .