 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFauna Sprout: A lightweight, approachable, developer-ready humanoid robot
Jan 26, 2026Recent advances in learned control, large-scale simulation, and generative models have accelerated progress toward general-purpose robotic controllers, yet the field still lacks platforms suitable for safe, expressive, long-term deployment in human environments. Most existing humanoids are either closed industrial systems or academic prototypes that are difficult to deploy and operate around people, limiting progress in robotics. We introduce Sprout, a developer platform designed to address these limitations through an emphasis on safety, expressivity, and developer accessibility. Sprout adopts a lightweight form factor with compliant control, limited joint torques, and soft exteriors to support safe operation in shared human spaces. The platform integrates whole-body control, manipulation with integrated grippers, and virtual-reality-based teleoperation within a unified hardware-software stack. An expressive head further enables social interaction -- a domain that remains underexplored on most utilitarian humanoids. By lowering physical and technical barriers to deployment, Sprout expands access to capable humanoid platforms and provides a practical basis for developing embodied intelligence in real human environments.
Mechanisms of Generative Image-to-Image Translation Networks
Nov 15, 2024Generative Adversarial Networks (GANs) are a class of neural networks that have been widely used in the field of image-to-image translation. In this paper, we propose a streamlined image-to-image translation network with a simpler architecture compared to existing models. We investigate the relationship between GANs and autoencoders and provide an explanation for the efficacy of employing only the GAN component for tasks involving image translation. We show that adversarial for GAN models yields results comparable to those of existing methods without additional complex loss penalties. Subsequently, we elucidate the rationale behind this phenomenon. We also incorporate experimental results to demonstrate the validity of our findings.
Shape-Preserving Generation of Food Images for Automatic Dietary Assessment
Aug 23, 2024



Traditional dietary assessment methods heavily rely on self-reporting, which is time-consuming and prone to bias. Recent advancements in Artificial Intelligence (AI) have revealed new possibilities for dietary assessment, particularly through analysis of food images. Recognizing foods and estimating food volumes from images are known as the key procedures for automatic dietary assessment. However, both procedures required large amounts of training images labeled with food names and volumes, which are currently unavailable. Alternatively, recent studies have indicated that training images can be artificially generated using Generative Adversarial Networks (GANs). Nonetheless, convenient generation of large amounts of food images with known volumes remain a challenge with the existing techniques. In this work, we present a simple GAN-based neural network architecture for conditional food image generation. The shapes of the food and container in the generated images closely resemble those in the reference input image. Our experiments demonstrate the realism of the generated images and shape-preserving capabilities of the proposed framework.
One-shot Video Imitation via Parameterized Symbolic Abstraction Graphs
Aug 22, 2024



Learning to manipulate dynamic and deformable objects from a single demonstration video holds great promise in terms of scalability. Previous approaches have predominantly focused on either replaying object relationships or actor trajectories. The former often struggles to generalize across diverse tasks, while the latter suffers from data inefficiency. Moreover, both methodologies encounter challenges in capturing invisible physical attributes, such as forces. In this paper, we propose to interpret video demonstrations through Parameterized Symbolic Abstraction Graphs (PSAG), where nodes represent objects and edges denote relationships between objects. We further ground geometric constraints through simulation to estimate non-geometric, visually imperceptible attributes. The augmented PSAG is then applied in real robot experiments. Our approach has been validated across a range of tasks, such as Cutting Avocado, Cutting Vegetable, Pouring Liquid, Rolling Dough, and Slicing Pizza. We demonstrate successful generalization to novel objects with distinct visual and physical properties.
SMPLOlympics: Sports Environments for Physically Simulated Humanoids
Jun 28, 2024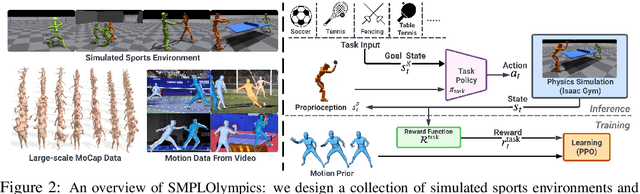
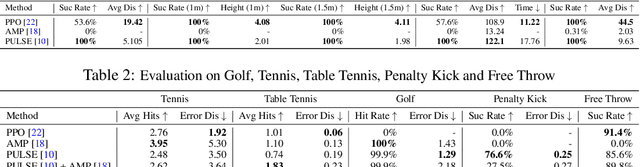

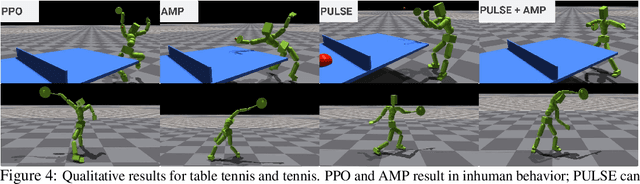
We present SMPLOlympics, a collection of physically simulated environments that allow humanoids to compete in a variety of Olympic sports. Sports simulation offers a rich and standardized testing ground for evaluating and improving the capabilities of learning algorithms due to the diversity and physically demanding nature of athletic activities. As humans have been competing in these sports for many years, there is also a plethora of existing knowledge on the preferred strategy to achieve better performance. To leverage these existing human demonstrations from videos and motion capture, we design our humanoid to be compatible with the widely-used SMPL and SMPL-X human models from the vision and graphics community. We provide a suite of individual sports environments, including golf, javelin throw, high jump, long jump, and hurdling, as well as competitive sports, including both 1v1 and 2v2 games such as table tennis, tennis, fencing, boxing, soccer, and basketball. Our analysis shows that combining strong motion priors with simple rewards can result in human-like behavior in various sports. By providing a unified sports benchmark and baseline implementation of state and reward designs, we hope that SMPLOlympics can help the control and animation communities achieve human-like and performant behaviors.
Learning Orbitally Stable Systems for Diagrammatically Teaching
Sep 19, 2023



Diagrammatic Teaching is a paradigm for robots to acquire novel skills, whereby the user provides 2D sketches over images of the scene to shape the robot's motion. In this work, we tackle the problem of teaching a robot to approach a surface and then follow cyclic motion on it, where the cycle of the motion can be arbitrarily specified by a single user-provided sketch over an image from the robot's camera. Accordingly, we introduce the \emph{Stable Diffeomorphic Diagrammatic Teaching} (SDDT) framework. SDDT models the robot's motion as an \emph{Orbitally Asymptotically Stable} (O.A.S.) dynamical system that learns to follow the user-specified sketch. This is achieved by applying a \emph{diffeomorphism}, i.e. a differentiable and invertible function, to morph a known O.A.S. system. The parameterised diffeomorphism is then optimised with respect to the Hausdorff distance between the limit cycle of our modelled system and the sketch, to produce the desired robot motion. We provide theoretical insight into the behaviour of the optimised system and also empirically evaluate SDDT, both in simulation and on a quadruped with a mounted 6-DOF manipulator. Results show that we can diagrammatically teach complex cyclic motion patterns with a high degree of accuracy.