 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing from References using a Multi-Task Reference and Goal-Driven RL Framework
Feb 23, 2026Learning agile humanoid behaviors from human motion offers a powerful route to natural, coordinated control, but existing approaches face a persistent trade-off: reference-tracking policies are often brittle outside the demonstration dataset, while purely task-driven Reinforcement Learning (RL) can achieve adaptability at the cost of motion quality. We introduce a unified multi-task RL framework that bridges this gap by treating reference motion as a prior for behavioral shaping rather than a deployment-time constraint. A single goal-conditioned policy is trained jointly on two tasks that share the same observation and action spaces, but differ in their initialization schemes, command spaces, and reward structures: (i) a reference-guided imitation task in which reference trajectories define dense imitation rewards but are not provided as policy inputs, and (ii) a goal-conditioned generalization task in which goals are sampled independently of any reference and where rewards reflect only task success. By co-optimizing these objectives within a shared formulation, the policy acquires structured, human-like motor skills from dense reference supervision while learning to adapt these skills to novel goals and initial conditions. This is achieved without adversarial objectives, explicit trajectory tracking, phase variables, or reference-dependent inference. We evaluate the method on a challenging box-based parkour playground that demands diverse athletic behaviors (e.g., jumping and climbing), and show that the learned controller transfers beyond the reference distribution while preserving motion naturalness. Finally, we demonstrate long-horizon behavior generation by composing multiple learned skills, illustrating the flexibility of the learned polices in complex scenarios.
ZEST: Zero-shot Embodied Skill Transfer for Athletic Robot Control
Jan 30, 2026Achieving robust, human-like whole-body control on humanoid robots for agile, contact-rich behaviors remains a central challenge, demanding heavy per-skill engineering and a brittle process of tuning controllers. We introduce ZEST (Zero-shot Embodied Skill Transfer), a streamlined motion-imitation framework that trains policies via reinforcement learning from diverse sources -- high-fidelity motion capture, noisy monocular video, and non-physics-constrained animation -- and deploys them to hardware zero-shot. ZEST generalizes across behaviors and platforms while avoiding contact labels, reference or observation windows, state estimators, and extensive reward shaping. Its training pipeline combines adaptive sampling, which focuses training on difficult motion segments, and an automatic curriculum using a model-based assistive wrench, together enabling dynamic, long-horizon maneuvers. We further provide a procedure for selecting joint-level gains from approximate analytical armature values for closed-chain actuators, along with a refined model of actuators. Trained entirely in simulation with moderate domain randomization, ZEST demonstrates remarkable generality. On Boston Dynamics' Atlas humanoid, ZEST learns dynamic, multi-contact skills (e.g., army crawl, breakdancing) from motion capture. It transfers expressive dance and scene-interaction skills, such as box-climbing, directly from videos to Atlas and the Unitree G1. Furthermore, it extends across morphologies to the Spot quadruped, enabling acrobatics, such as a continuous backflip, through animation. Together, these results demonstrate robust zero-shot deployment across heterogeneous data sources and embodiments, establishing ZEST as a scalable interface between biological movements and their robotic counterparts.
CRISP: Contact-Guided Real2Sim from Monocular Video with Planar Scene Primitives
Dec 21, 2025We introduce CRISP, a method that recovers simulatable human motion and scene geometry from monocular video. Prior work on joint human-scene reconstruction relies on data-driven priors and joint optimization with no physics in the loop, or recovers noisy geometry with artifacts that cause motion tracking policies with scene interactions to fail. In contrast, our key insight is to recover convex, clean, and simulation-ready geometry by fitting planar primitives to a point cloud reconstruction of the scene, via a simple clustering pipeline over depth, normals, and flow. To reconstruct scene geometry that might be occluded during interactions, we make use of human-scene contact modeling (e.g., we use human posture to reconstruct the occluded seat of a chair). Finally, we ensure that human and scene reconstructions are physically-plausible by using them to drive a humanoid controller via reinforcement learning. Our approach reduces motion tracking failure rates from 55.2\% to 6.9\% on human-centric video benchmarks (EMDB, PROX), while delivering a 43\% faster RL simulation throughput. We further validate it on in-the-wild videos including casually-captured videos, Internet videos, and even Sora-generated videos. This demonstrates CRISP's ability to generate physically-valid human motion and interaction environments at scale, greatly advancing real-to-sim applications for robotics and AR/VR.
Web2Grasp: Learning Functional Grasps from Web Images of Hand-Object Interactions
May 07, 2025Functional grasp is essential for enabling dexterous multi-finger robot hands to manipulate objects effectively. However, most prior work either focuses on power grasping, which simply involves holding an object still, or relies on costly teleoperated robot demonstrations to teach robots how to grasp each object functionally. Instead, we propose extracting human grasp information from web images since they depict natural and functional object interactions, thereby bypassing the need for curated demonstrations. We reconstruct human hand-object interaction (HOI) 3D meshes from RGB images, retarget the human hand to multi-finger robot hands, and align the noisy object mesh with its accurate 3D shape. We show that these relatively low-quality HOI data from inexpensive web sources can effectively train a functional grasping model. To further expand the grasp dataset for seen and unseen objects, we use the initially-trained grasping policy with web data in the IsaacGym simulator to generate physically feasible grasps while preserving functionality. We train the grasping model on 10 object categories and evaluate it on 9 unseen objects, including challenging items such as syringes, pens, spray bottles, and tongs, which are underrepresented in existing datasets. The model trained on the web HOI dataset, achieving a 75.8% success rate on seen objects and 61.8% across all objects in simulation, with a 6.7% improvement in success rate and a 1.8x increase in functionality ratings over baselines. Simulator-augmented data further boosts performance from 61.8% to 83.4%. The sim-to-real transfer to the LEAP Hand achieves a 85% success rate. Project website is at: https://webgrasp.github.io/.
ASAP: Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body Skills
Feb 03, 2025Humanoid robots hold the potential for unparalleled versatility in performing human-like, whole-body skills. However, achieving agile and coordinated whole-body motions remains a significant challenge due to the dynamics mismatch between simulation and the real world. Existing approaches, such as system identification (SysID) and domain randomization (DR) methods, often rely on labor-intensive parameter tuning or result in overly conservative policies that sacrifice agility. In this paper, we present ASAP (Aligning Simulation and Real-World Physics), a two-stage framework designed to tackle the dynamics mismatch and enable agile humanoid whole-body skills. In the first stage, we pre-train motion tracking policies in simulation using retargeted human motion data. In the second stage, we deploy the policies in the real world and collect real-world data to train a delta (residual) action model that compensates for the dynamics mismatch. Then, ASAP fine-tunes pre-trained policies with the delta action model integrated into the simulator to align effectively with real-world dynamics. We evaluate ASAP across three transfer scenarios: IsaacGym to IsaacSim, IsaacGym to Genesis, and IsaacGym to the real-world Unitree G1 humanoid robot. Our approach significantly improves agility and whole-body coordination across various dynamic motions, reducing tracking error compared to SysID, DR, and delta dynamics learning baselines. ASAP enables highly agile motions that were previously difficult to achieve, demonstrating the potential of delta action learning in bridging simulation and real-world dynamics. These results suggest a promising sim-to-real direction for developing more expressive and agile humanoids.
Strategy and Skill Learning for Physics-based Table Tennis Animation
Jul 23, 2024



Recent advancements in physics-based character animation leverage deep learning to generate agile and natural motion, enabling characters to execute movements such as backflips, boxing, and tennis. However, reproducing the selection and use of diverse motor skills in dynamic environments to solve complex tasks, as humans do, still remains a challenge. We present a strategy and skill learning approach for physics-based table tennis animation. Our method addresses the issue of mode collapse, where the characters do not fully utilize the motor skills they need to perform to execute complex tasks. More specifically, we demonstrate a hierarchical control system for diversified skill learning and a strategy learning framework for effective decision-making. We showcase the efficacy of our method through comparative analysis with state-of-the-art methods, demonstrating its capabilities in executing various skills for table tennis. Our strategy learning framework is validated through both agent-agent interaction and human-agent interaction in Virtual Reality, handling both competitive and cooperative tasks.
SMPLOlympics: Sports Environments for Physically Simulated Humanoids
Jun 28, 2024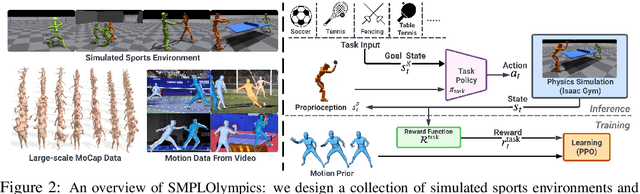
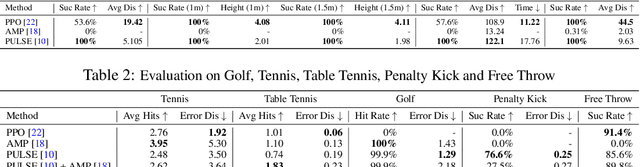

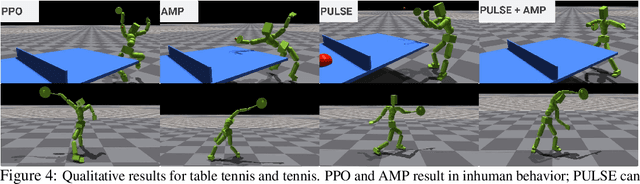
We present SMPLOlympics, a collection of physically simulated environments that allow humanoids to compete in a variety of Olympic sports. Sports simulation offers a rich and standardized testing ground for evaluating and improving the capabilities of learning algorithms due to the diversity and physically demanding nature of athletic activities. As humans have been competing in these sports for many years, there is also a plethora of existing knowledge on the preferred strategy to achieve better performance. To leverage these existing human demonstrations from videos and motion capture, we design our humanoid to be compatible with the widely-used SMPL and SMPL-X human models from the vision and graphics community. We provide a suite of individual sports environments, including golf, javelin throw, high jump, long jump, and hurdling, as well as competitive sports, including both 1v1 and 2v2 games such as table tennis, tennis, fencing, boxing, soccer, and basketball. Our analysis shows that combining strong motion priors with simple rewards can result in human-like behavior in various sports. By providing a unified sports benchmark and baseline implementation of state and reward designs, we hope that SMPLOlympics can help the control and animation communities achieve human-like and performant behaviors.
H-InDex: Visual Reinforcement Learning with Hand-Informed Representations for Dexterous Manipulation
Oct 13, 2023Human hands possess remarkable dexterity and have long served as a source of inspiration for robotic manipulation. In this work, we propose a human $\textbf{H}$and$\textbf{-In}$formed visual representation learning framework to solve difficult $\textbf{Dex}$terous manipulation tasks ($\textbf{H-InDex}$) with reinforcement learning. Our framework consists of three stages: (i) pre-training representations with 3D human hand pose estimation, (ii) offline adapting representations with self-supervised keypoint detection, and (iii) reinforcement learning with exponential moving average BatchNorm. The last two stages only modify $0.36\%$ parameters of the pre-trained representation in total, ensuring the knowledge from pre-training is maintained to the full extent. We empirically study 12 challenging dexterous manipulation tasks and find that H-InDex largely surpasses strong baseline methods and the recent visual foundation models for motor control. Code is available at https://yanjieze.com/H-InDex .
VoxDet: Voxel Learning for Novel Instance Detection
Jun 04, 2023Detecting unseen instances based on multi-view templates is a challenging problem due to its open-world nature. Traditional methodologies, which primarily rely on 2D representations and matching techniques, are often inadequate in handling pose variations and occlusions. To solve this, we introduce VoxDet, a pioneer 3D geometry-aware framework that fully utilizes the strong 3D voxel representation and reliable voxel matching mechanism. VoxDet first ingeniously proposes template voxel aggregation (TVA) module, effectively transforming multi-view 2D images into 3D voxel features. By leveraging associated camera poses, these features are aggregated into a compact 3D template voxel. In novel instance detection, this voxel representation demonstrates heightened resilience to occlusion and pose variations. We also discover that a 3D reconstruction objective helps to pre-train the 2D-3D mapping in TVA. Second, to quickly align with the template voxel, VoxDet incorporates a Query Voxel Matching (QVM) module. The 2D queries are first converted into their voxel representation with the learned 2D-3D mapping. We find that since the 3D voxel representations encode the geometry, we can first estimate the relative rotation and then compare the aligned voxels, leading to improved accuracy and efficiency. Exhaustive experiments are conducted on the demanding LineMod-Occlusion, YCB-video, and the newly built RoboTools benchmarks, where VoxDet outperforms various 2D baselines remarkably with 20% higher recall and faster speed. To the best of our knowledge, VoxDet is the first to incorporate implicit 3D knowledge for 2D detection tasks.
Zero-shot Pose Transfer for Unrigged Stylized 3D Characters
May 31, 2023



Transferring the pose of a reference avatar to stylized 3D characters of various shapes is a fundamental task in computer graphics. Existing methods either require the stylized characters to be rigged, or they use the stylized character in the desired pose as ground truth at training. We present a zero-shot approach that requires only the widely available deformed non-stylized avatars in training, and deforms stylized characters of significantly different shapes at inference. Classical methods achieve strong generalization by deforming the mesh at the triangle level, but this requires labelled correspondences. We leverage the power of local deformation, but without requiring explicit correspondence labels. We introduce a semi-supervised shape-understanding module to bypass the need for explicit correspondences at test time, and an implicit pose deformation module that deforms individual surface points to match the target pose. Furthermore, to encourage realistic and accurate deformation of stylized characters, we introduce an efficient volume-based test-time training procedure. Because it does not need rigging, nor the deformed stylized character at training time, our model generalizes to categories with scarce annotation, such as stylized quadrupeds. Extensive experiments demonstrate the effectiveness of the proposed method compared to the state-of-the-art approaches trained with comparable or more supervision. Our project page is available at https://jiashunwang.github.io/ZPT