 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDex: A Robot Foundation Suite for Universal Dexterous Hand Control from Egocentric Human Videos
Mar 23, 2026Dexterous manipulation remains challenging due to the cost of collecting real-robot teleoperation data, the heterogeneity of hand embodiments, and the high dimensionality of control. We present UniDex, a robot foundation suite that couples a large-scale robot-centric dataset with a unified vision-language-action (VLA) policy and a practical human-data capture setup for universal dexterous hand control. First, we construct UniDex-Dataset, a robot-centric dataset over 50K trajectories across eight dexterous hands (6--24 DoFs), derived from egocentric human video datasets. To transform human data into robot-executable trajectories, we employ a human-in-the-loop retargeting procedure to align fingertip trajectories while preserving plausible hand-object contacts, and we operate on explicit 3D pointclouds with human hands masked to narrow kinematic and visual gaps. Second, we introduce the Function-Actuator-Aligned Space (FAAS), a unified action space that maps functionally similar actuators to shared coordinates, enabling cross-hand transfer. Leveraging FAAS as the action parameterization, we train UniDex-VLA, a 3D VLA policy pretrained on UniDex-Dataset and finetuned with task demonstrations. In addition, we build UniDex-Cap, a simple portable capture setup that records synchronized RGB-D streams and human hand poses and converts them into robot-executable trajectories to enable human-robot data co-training that reduces reliance on costly robot demonstrations. On challenging tool-use tasks across two different hands, UniDex-VLA achieves 81% average task progress and outperforms prior VLA baselines by a large margin, while exhibiting strong spatial, object, and zero-shot cross-hand generalization. Together, UniDex-Dataset, UniDex-VLA, and UniDex-Cap provide a scalable foundation suite for universal dexterous manipulation.
ViTaS: Visual Tactile Soft Fusion Contrastive Learning for Visuomotor Learning
Feb 12, 2026Tactile information plays a crucial role in human manipulation tasks and has recently garnered increasing attention in robotic manipulation. However, existing approaches mostly focus on the alignment of visual and tactile features and the integration mechanism tends to be direct concatenation. Consequently, they struggle to effectively cope with occluded scenarios due to neglecting the inherent complementary nature of both modalities and the alignment may not be exploited enough, limiting the potential of their real-world deployment. In this paper, we present ViTaS, a simple yet effective framework that incorporates both visual and tactile information to guide the behavior of an agent. We introduce Soft Fusion Contrastive Learning, an advanced version of conventional contrastive learning method and a CVAE module to utilize the alignment and complementarity within visuo-tactile representations. We demonstrate the effectiveness of our method in 12 simulated and 3 real-world environments, and our experiments show that ViTaS significantly outperforms existing baselines. Project page: https://skyrainwind.github.io/ViTaS/index.html.
HERMES: Human-to-Robot Embodied Learning from Multi-Source Motion Data for Mobile Dexterous Manipulation
Aug 28, 2025Leveraging human motion data to impart robots with versatile manipulation skills has emerged as a promising paradigm in robotic manipulation. Nevertheless, translating multi-source human hand motions into feasible robot behaviors remains challenging, particularly for robots equipped with multi-fingered dexterous hands characterized by complex, high-dimensional action spaces. Moreover, existing approaches often struggle to produce policies capable of adapting to diverse environmental conditions. In this paper, we introduce HERMES, a human-to-robot learning framework for mobile bimanual dexterous manipulation. First, HERMES formulates a unified reinforcement learning approach capable of seamlessly transforming heterogeneous human hand motions from multiple sources into physically plausible robotic behaviors. Subsequently, to mitigate the sim2real gap, we devise an end-to-end, depth image-based sim2real transfer method for improved generalization to real-world scenarios. Furthermore, to enable autonomous operation in varied and unstructured environments, we augment the navigation foundation model with a closed-loop Perspective-n-Point (PnP) localization mechanism, ensuring precise alignment of visual goals and effectively bridging autonomous navigation and dexterous manipulation. Extensive experimental results demonstrate that HERMES consistently exhibits generalizable behaviors across diverse, in-the-wild scenarios, successfully performing numerous complex mobile bimanual dexterous manipulation tasks. Project Page:https://gemcollector.github.io/HERMES/.
A Forget-and-Grow Strategy for Deep Reinforcement Learning Scaling in Continuous Control
Jul 03, 2025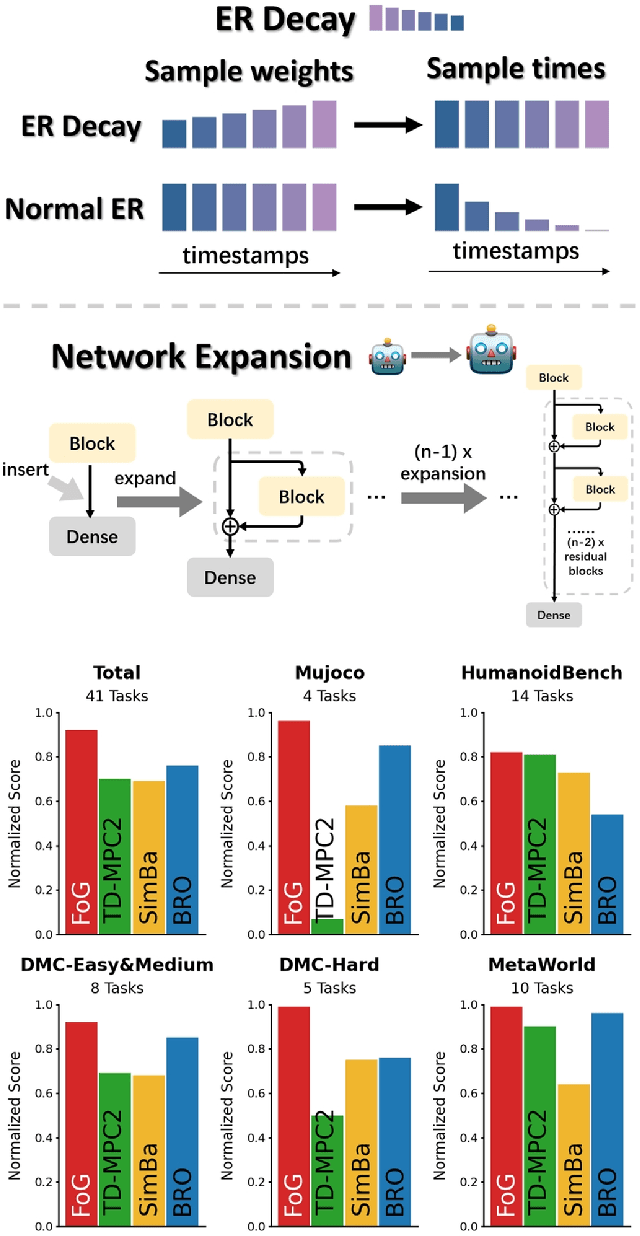
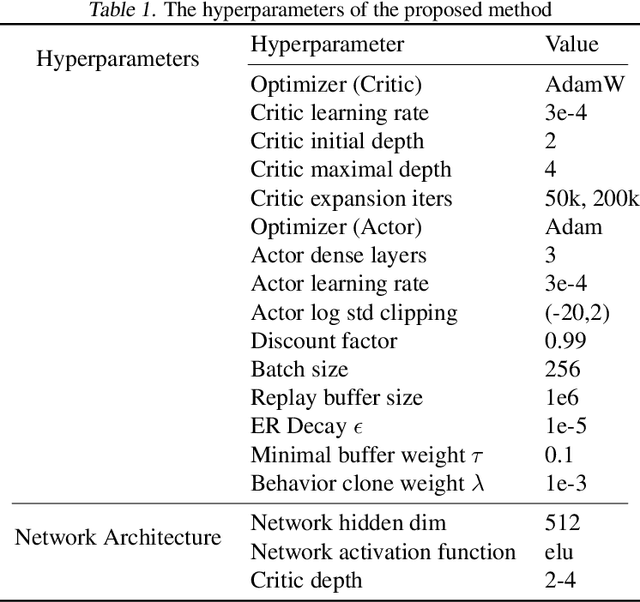
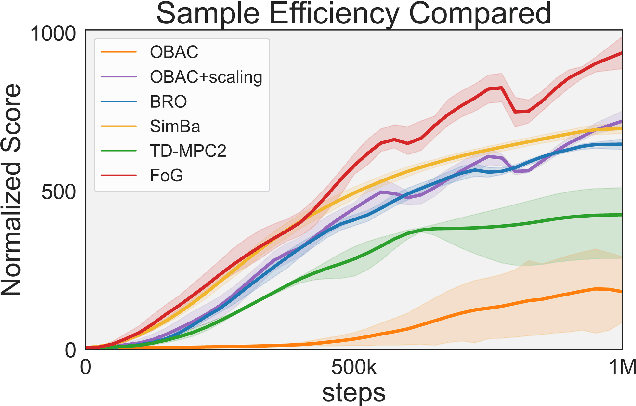
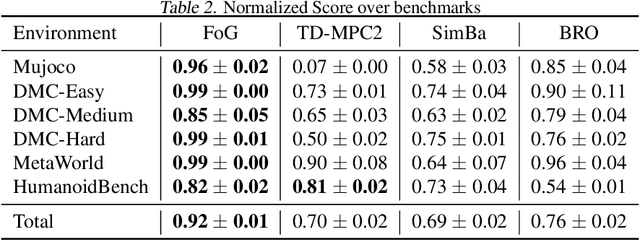
Deep reinforcement learning for continuous control has recently achieved impressive progress. However, existing methods often suffer from primacy bias, a tendency to overfit early experiences stored in the replay buffer, which limits an RL agent's sample efficiency and generalizability. In contrast, humans are less susceptible to such bias, partly due to infantile amnesia, where the formation of new neurons disrupts early memory traces, leading to the forgetting of initial experiences. Inspired by this dual processes of forgetting and growing in neuroscience, in this paper, we propose Forget and Grow (FoG), a new deep RL algorithm with two mechanisms introduced. First, Experience Replay Decay (ER Decay) "forgetting early experience", which balances memory by gradually reducing the influence of early experiences. Second, Network Expansion, "growing neural capacity", which enhances agents' capability to exploit the patterns of existing data by dynamically adding new parameters during training. Empirical results on four major continuous control benchmarks with more than 40 tasks demonstrate the superior performance of FoG against SoTA existing deep RL algorithms, including BRO, SimBa, and TD-MPC2.
H$^{\mathbf{3}}$DP: Triply-Hierarchical Diffusion Policy for Visuomotor Learning
May 12, 2025Visuomotor policy learning has witnessed substantial progress in robotic manipulation, with recent approaches predominantly relying on generative models to model the action distribution. However, these methods often overlook the critical coupling between visual perception and action prediction. In this work, we introduce $\textbf{Triply-Hierarchical Diffusion Policy}~(\textbf{H$^{\mathbf{3}}$DP})$, a novel visuomotor learning framework that explicitly incorporates hierarchical structures to strengthen the integration between visual features and action generation. H$^{3}$DP contains $\mathbf{3}$ levels of hierarchy: (1) depth-aware input layering that organizes RGB-D observations based on depth information; (2) multi-scale visual representations that encode semantic features at varying levels of granularity; and (3) a hierarchically conditioned diffusion process that aligns the generation of coarse-to-fine actions with corresponding visual features. Extensive experiments demonstrate that H$^{3}$DP yields a $\mathbf{+27.5\%}$ average relative improvement over baselines across $\mathbf{44}$ simulation tasks and achieves superior performance in $\mathbf{4}$ challenging bimanual real-world manipulation tasks. Project Page: https://lyy-iiis.github.io/h3dp/.
DemoGen: Synthetic Demonstration Generation for Data-Efficient Visuomotor Policy Learning
Feb 24, 2025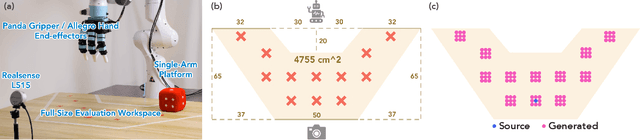
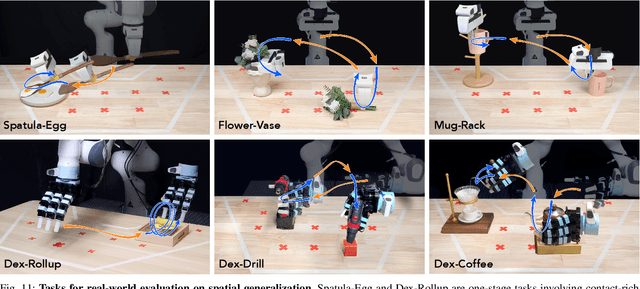
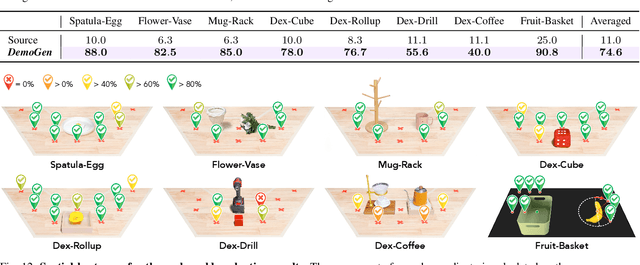

Visuomotor policies have shown great promise in robotic manipulation but often require substantial amounts of human-collected data for effective performance. A key reason underlying the data demands is their limited spatial generalization capability, which necessitates extensive data collection across different object configurations. In this work, we present DemoGen, a low-cost, fully synthetic approach for automatic demonstration generation. Using only one human-collected demonstration per task, DemoGen generates spatially augmented demonstrations by adapting the demonstrated action trajectory to novel object configurations. Visual observations are synthesized by leveraging 3D point clouds as the modality and rearranging the subjects in the scene via 3D editing. Empirically, DemoGen significantly enhances policy performance across a diverse range of real-world manipulation tasks, showing its applicability even in challenging scenarios involving deformable objects, dexterous hand end-effectors, and bimanual platforms. Furthermore, DemoGen can be extended to enable additional out-of-distribution capabilities, including disturbance resistance and obstacle avoidance.
DOGlove: Dexterous Manipulation with a Low-Cost Open-Source Haptic Force Feedback Glove
Feb 11, 2025

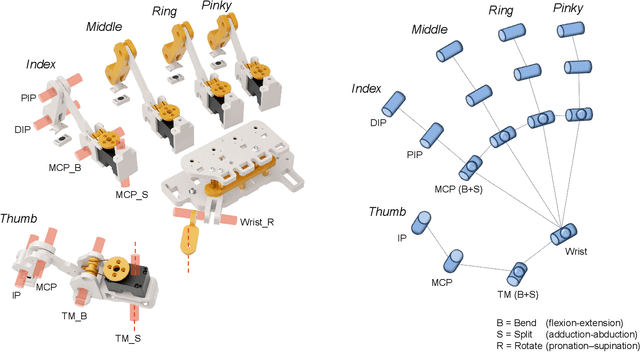
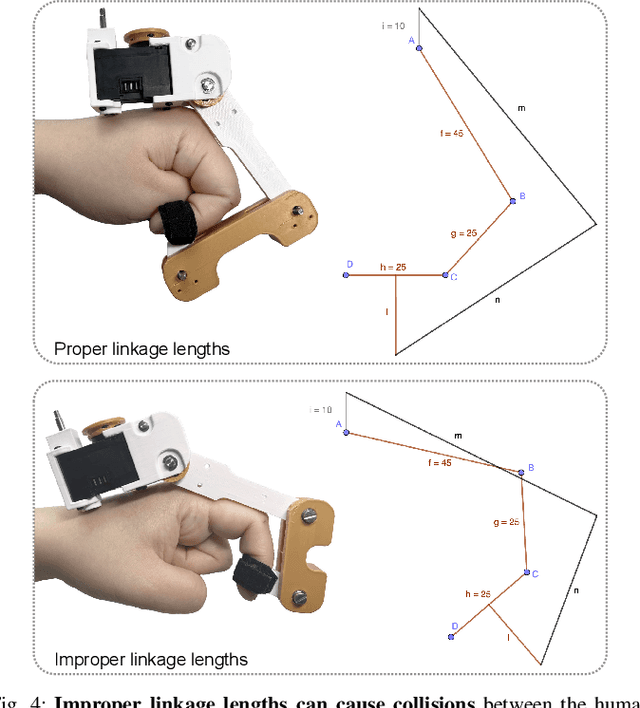
Dexterous hand teleoperation plays a pivotal role in enabling robots to achieve human-level manipulation dexterity. However, current teleoperation systems often rely on expensive equipment and lack multi-modal sensory feedback, restricting human operators' ability to perceive object properties and perform complex manipulation tasks. To address these limitations, we present DOGlove, a low-cost, precise, and haptic force feedback glove system for teleoperation and manipulation. DoGlove can be assembled in hours at a cost under 600 USD. It features a customized joint structure for 21-DoF motion capture, a compact cable-driven torque transmission mechanism for 5-DoF multidirectional force feedback, and a linear resonate actuator for 5-DoF fingertip haptic feedback. Leveraging action and haptic force retargeting, DOGlove enables precise and immersive teleoperation of dexterous robotic hands, achieving high success rates in complex, contact-rich tasks. We further evaluate DOGlove in scenarios without visual feedback, demonstrating the critical role of haptic force feedback in task performance. In addition, we utilize the collected demonstrations to train imitation learning policies, highlighting the potential and effectiveness of DOGlove. DOGlove's hardware and software system will be fully open-sourced at https://do-glove.github.io/.
DenseMatcher: Learning 3D Semantic Correspondence for Category-Level Manipulation from a Single Demo
Dec 06, 2024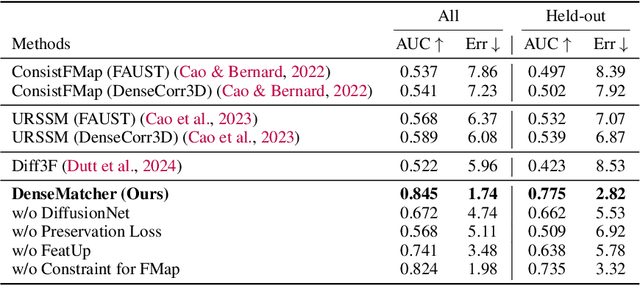


Dense 3D correspondence can enhance robotic manipulation by enabling the generalization of spatial, functional, and dynamic information from one object to an unseen counterpart. Compared to shape correspondence, semantic correspondence is more effective in generalizing across different object categories. To this end, we present DenseMatcher, a method capable of computing 3D correspondences between in-the-wild objects that share similar structures. DenseMatcher first computes vertex features by projecting multiview 2D features onto meshes and refining them with a 3D network, and subsequently finds dense correspondences with the obtained features using functional map. In addition, we craft the first 3D matching dataset that contains colored object meshes across diverse categories. In our experiments, we show that DenseMatcher significantly outperforms prior 3D matching baselines by 43.5%. We demonstrate the downstream effectiveness of DenseMatcher in (i) robotic manipulation, where it achieves cross-instance and cross-category generalization on long-horizon complex manipulation tasks from observing only one demo; (ii) zero-shot color mapping between digital assets, where appearance can be transferred between different objects with relatable geometry.
Learning to Manipulate Anywhere: A Visual Generalizable Framework For Reinforcement Learning
Jul 22, 2024



Can we endow visuomotor robots with generalization capabilities to operate in diverse open-world scenarios? In this paper, we propose \textbf{Maniwhere}, a generalizable framework tailored for visual reinforcement learning, enabling the trained robot policies to generalize across a combination of multiple visual disturbance types. Specifically, we introduce a multi-view representation learning approach fused with Spatial Transformer Network (STN) module to capture shared semantic information and correspondences among different viewpoints. In addition, we employ a curriculum-based randomization and augmentation approach to stabilize the RL training process and strengthen the visual generalization ability. To exhibit the effectiveness of Maniwhere, we meticulously design 8 tasks encompassing articulate objects, bi-manual, and dexterous hand manipulation tasks, demonstrating Maniwhere's strong visual generalization and sim2real transfer abilities across 3 hardware platforms. Our experiments show that Maniwhere significantly outperforms existing state-of-the-art methods. Videos are provided at https://gemcollector.github.io/maniwhere/.
RoboDuet: A Framework Affording Mobile-Manipulation and Cross-Embodiment
Mar 27, 2024
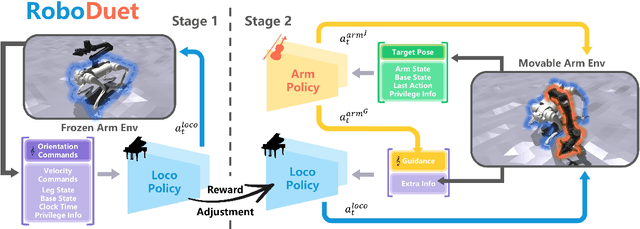
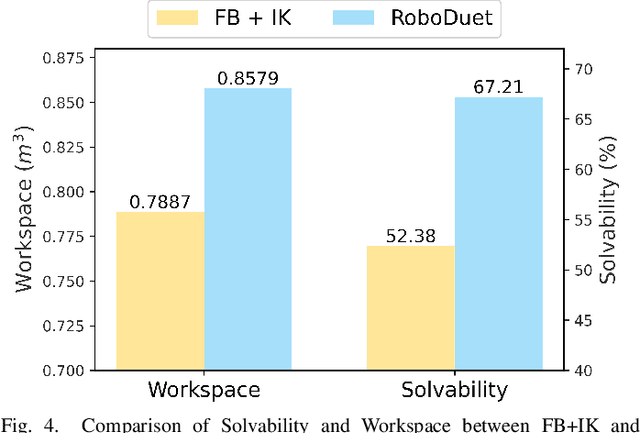
Combining the mobility of legged robots with the manipulation skills of arms has the potential to significantly expand the operational range and enhance the capabilities of robotic systems in performing various mobile manipulation tasks. Existing approaches are confined to imprecise six degrees of freedom (DoF) manipulation and possess a limited arm workspace. In this paper, we propose a novel framework, RoboDuet, which employs two collaborative policies to realize locomotion and manipulation simultaneously, achieving whole-body control through interactions between each other. Surprisingly, going beyond the large-range pose tracking, we find that the two-policy framework may enable cross-embodiment deployment such as using different quadrupedal robots or other arms. Our experiments demonstrate that the policies trained through RoboDuet can accomplish stable gaits, agile 6D end-effector pose tracking, and zero-shot exchange of legged robots, and can be deployed in the real world to perform various mobile manipulation tasks. Our project page with demo videos is at https://locomanip-duet.github.io .