 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Forget-and-Grow Strategy for Deep Reinforcement Learning Scaling in Continuous Control
Jul 03, 2025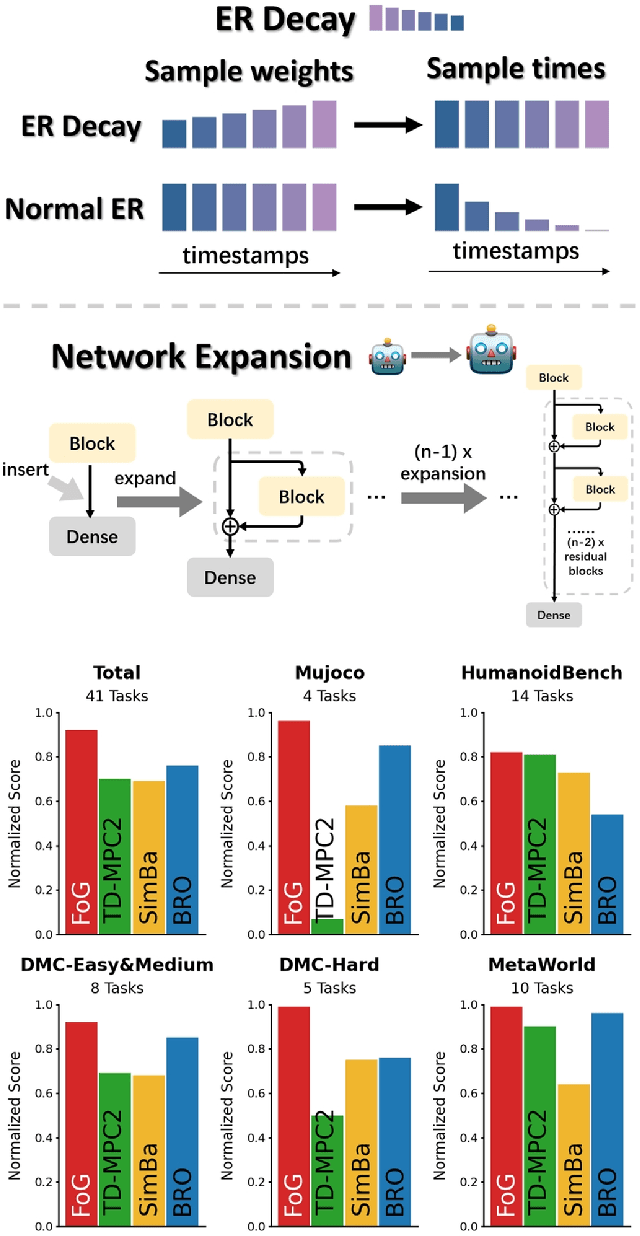
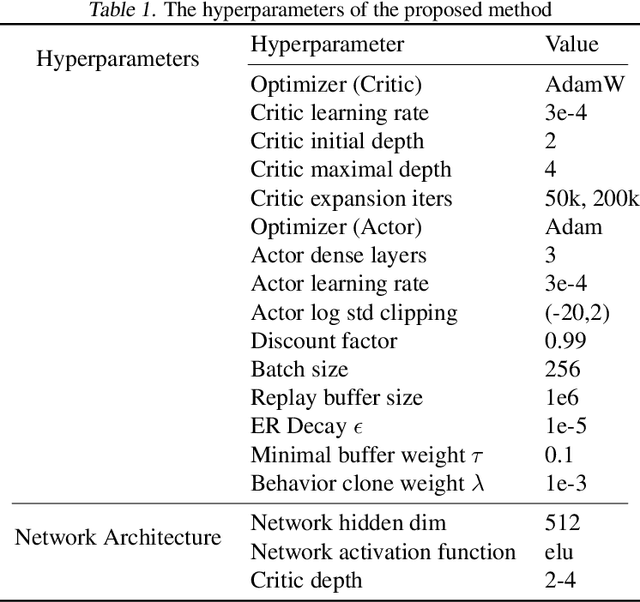
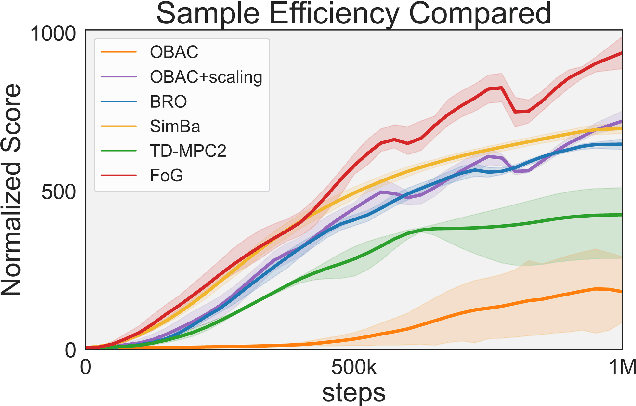
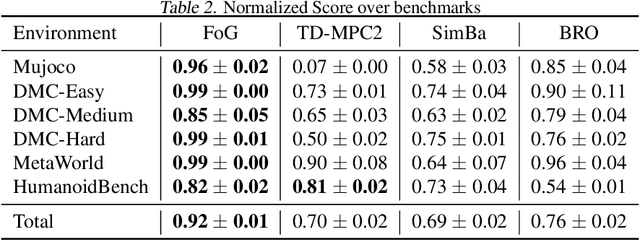
Deep reinforcement learning for continuous control has recently achieved impressive progress. However, existing methods often suffer from primacy bias, a tendency to overfit early experiences stored in the replay buffer, which limits an RL agent's sample efficiency and generalizability. In contrast, humans are less susceptible to such bias, partly due to infantile amnesia, where the formation of new neurons disrupts early memory traces, leading to the forgetting of initial experiences. Inspired by this dual processes of forgetting and growing in neuroscience, in this paper, we propose Forget and Grow (FoG), a new deep RL algorithm with two mechanisms introduced. First, Experience Replay Decay (ER Decay) "forgetting early experience", which balances memory by gradually reducing the influence of early experiences. Second, Network Expansion, "growing neural capacity", which enhances agents' capability to exploit the patterns of existing data by dynamically adding new parameters during training. Empirical results on four major continuous control benchmarks with more than 40 tasks demonstrate the superior performance of FoG against SoTA existing deep RL algorithms, including BRO, SimBa, and TD-MPC2.
3D Diffusion Policy
Mar 06, 2024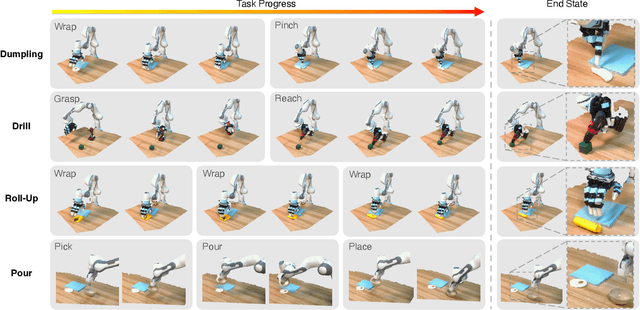

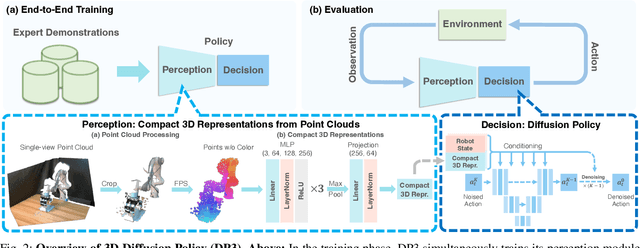
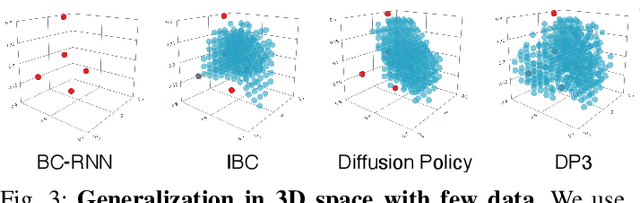
Imitation learning provides an efficient way to teach robots dexterous skills; however, learning complex skills robustly and generalizablely usually consumes large amounts of human demonstrations. To tackle this challenging problem, we present 3D Diffusion Policy (DP3), a novel visual imitation learning approach that incorporates the power of 3D visual representations into diffusion policies, a class of conditional action generative models. The core design of DP3 is the utilization of a compact 3D visual representation, extracted from sparse point clouds with an efficient point encoder. In our experiments involving 72 simulation tasks, DP3 successfully handles most tasks with just 10 demonstrations and surpasses baselines with a 55.3% relative improvement. In 4 real robot tasks, DP3 demonstrates precise control with a high success rate of 85%, given only 40 demonstrations of each task, and shows excellent generalization abilities in diverse aspects, including space, viewpoint, appearance, and instance. Interestingly, in real robot experiments, DP3 rarely violates safety requirements, in contrast to baseline methods which frequently do, necessitating human intervention. Our extensive evaluation highlights the critical importance of 3D representations in real-world robot learning. Videos, code, and data are available on https://3d-diffusion-policy.github.io .