 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffCold: A Diffusion-based Generative Model for Cold-Start Item Recommendation
Jun 10, 2026Cold-start item recommendation remains a persistent challenge in real-world systems due to the absence of interaction histories. While prior models attempt to bridge this gap using item content features, they universally suffer from the \textbf{seesaw dilemma}: enhancing performance for cold items inevitably degrades performance for warm items, and vice versa. We identify that this dilemma stems from a fundamental \textbf{distributional disparity}: warm item embeddings occupy a complex ``behavioral manifold" shaped by rich interaction signals, whereas cold item embeddings are constrained to a ``semantic manifold" derived solely from auxiliary content. Existing methods often force a rigid mapping between these inconsistent spaces, causing the model to sacrifice the precision of warm representations to accommodate cold ones. To address this, we propose \textbf{DiffCold}, a diffusion-based generative model that unifies warm and cold representations. Unlike GANs or VAEs, DiffCold leverages conditional diffusion to reconstruct warm item embeddings from content, preserving the underlying manifold structure without degradation. We further tailor this paradigm with two specific designs: a \textbf{Retrieval-enhanced Aggregator} that initializes generation using semantically similar warm items to bypass inefficient noise, and a \textbf{Simulation-based Representation Alignment} module that enforces distribution consistency between generated and real embeddings via contrastive learning. Experiments on three benchmarks confirm that DiffCold resolves the seesaw dilemma, consistently outperforming state-of-the-art methods across all metrics.
MMSkills: Towards Multimodal Skills for General Visual Agents
May 14, 2026Reusable skills have become a core substrate for improving agent capabilities, yet most existing skill packages encode reusable behavior primarily as textual prompts, executable code, or learned routines. For visual agents, however, procedural knowledge is inherently multimodal: reuse depends not only on what operation to perform, but also on recognizing the relevant state, interpreting visual evidence of progress or failure, and deciding what to do next. We formalize this requirement as multimodal procedural knowledge and address three practical challenges: (I) what a multimodal skill package should contain; (II) where such packages can be derived from public interaction experience; and (III) how agents can consult multimodal evidence at inference time without excessive image context or over-anchoring to reference screenshots. We introduce MMSkills, a framework for representing, generating, and using reusable multimodal procedures for runtime visual decision making. Each MMSkill is a compact, state-conditioned package that couples a textual procedure with runtime state cards and multi-view keyframes. To construct these packages, we develop an agentic trajectory-to-skill Generator that transforms public non-evaluation trajectories into reusable multimodal skills through workflow grouping, procedure induction, visual grounding, and meta-skill-guided auditing. To use them, we introduce a branch-loaded multimodal skill agent: selected state cards and keyframes are inspected in a temporary branch, aligned with the live environment, and distilled into structured guidance for the main agent. Experiments across GUI and game-based visual-agent benchmarks show that MMSkills consistently improve both frontier and smaller multimodal agents, suggesting that external multimodal procedural knowledge complements model-internal priors.
MuSEAgent: A Multimodal Reasoning Agent with Stateful Experiences
Mar 29, 2026Research agents have recently achieved significant progress in information seeking and synthesis across heterogeneous textual and visual sources. In this paper, we introduce MuSEAgent, a multimodal reasoning agent that enhances decision-making by extending the capabilities of research agents to discover and leverage stateful experiences. Rather than relying on trajectory-level retrieval, we propose a stateful experience learning paradigm that abstracts interaction data into atomic decision experiences through hindsight reasoning. These experiences are organized into a quality-filtered experience bank that supports policy-driven experience retrieval at inference time. Specifically, MuSEAgent enables adaptive experience exploitation through complementary wide- and deep-search strategies, allowing the agent to dynamically retrieve multimodal guidance across diverse compositional semantic viewpoints. Extensive experiments demonstrate that MuSEAgent consistently outperforms strong trajectory-level experience retrieval baselines on both fine-grained visual perception and complex multimodal reasoning tasks. These results validate the effectiveness of stateful experience modeling in improving multimodal agent reasoning.
LoopTool: Closing the Data-Training Loop for Robust LLM Tool Calls
Nov 18, 2025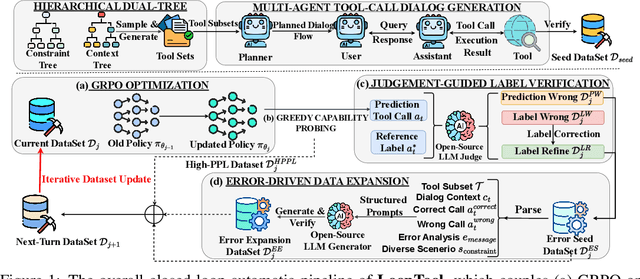
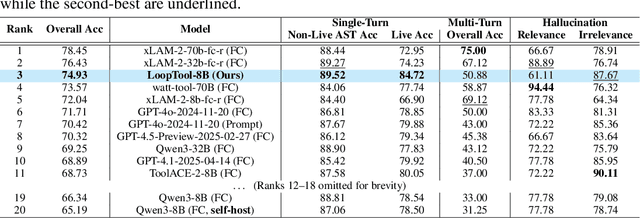
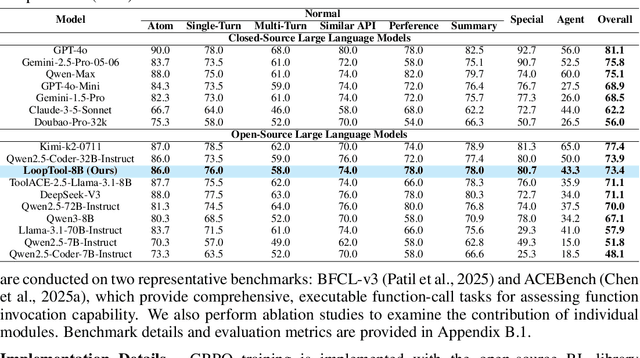
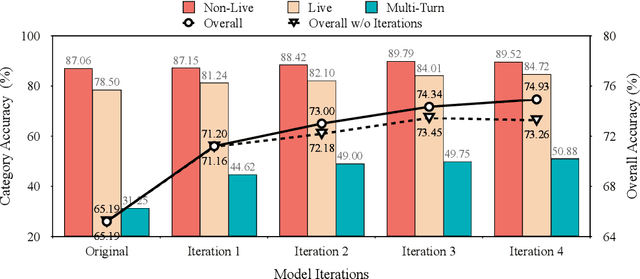
Augmenting Large Language Models (LLMs) with external tools enables them to execute complex, multi-step tasks. However, tool learning is hampered by the static synthetic data pipelines where data generation and model training are executed as two separate, non-interactive processes. This approach fails to adaptively focus on a model's specific weaknesses and allows noisy labels to persist, degrading training efficiency. We introduce LoopTool, a fully automated, model-aware data evolution framework that closes this loop by tightly integrating data synthesis and model training. LoopTool iteratively refines both the data and the model through three synergistic modules: (1) Greedy Capability Probing (GCP) diagnoses the model's mastered and failed capabilities; (2) Judgement-Guided Label Verification (JGLV) uses an open-source judge model to find and correct annotation errors, progressively purifying the dataset; and (3) Error-Driven Data Expansion (EDDE) generates new, challenging samples based on identified failures. This closed-loop process operates within a cost-effective, open-source ecosystem, eliminating dependence on expensive closed-source APIs. Experiments show that our 8B model trained with LoopTool significantly surpasses its 32B data generator and achieves new state-of-the-art results on the BFCL-v3 and ACEBench benchmarks for its scale. Our work demonstrates that closed-loop, self-refining data pipelines can dramatically enhance the tool-use capabilities of LLMs.
Fints: Efficient Inference-Time Personalization for LLMs with Fine-Grained Instance-Tailored Steering
Oct 31, 2025The rapid evolution of large language models (LLMs) has intensified the demand for effective personalization techniques that can adapt model behavior to individual user preferences. Despite the non-parametric methods utilizing the in-context learning ability of LLMs, recent parametric adaptation methods, including personalized parameter-efficient fine-tuning and reward modeling emerge. However, these methods face limitations in handling dynamic user patterns and high data sparsity scenarios, due to low adaptability and data efficiency. To address these challenges, we propose a fine-grained and instance-tailored steering framework that dynamically generates sample-level interference vectors from user data and injects them into the model's forward pass for personalized adaptation. Our approach introduces two key technical innovations: a fine-grained steering component that captures nuanced signals by hooking activations from attention and MLP layers, and an input-aware aggregation module that synthesizes these signals into contextually relevant enhancements. The method demonstrates high flexibility and data efficiency, excelling in fast-changing distribution and high data sparsity scenarios. In addition, the proposed method is orthogonal to existing methods and operates as a plug-in component compatible with different personalization techniques. Extensive experiments across diverse scenarios--including short-to-long text generation, and web function calling--validate the effectiveness and compatibility of our approach. Results show that our method significantly enhances personalization performance in fast-shifting environments while maintaining robustness across varying interaction modes and context lengths. Implementation is available at https://github.com/KounianhuaDu/Fints.
A Survey of Process Reward Models: From Outcome Signals to Process Supervisions for Large Language Models
Oct 09, 2025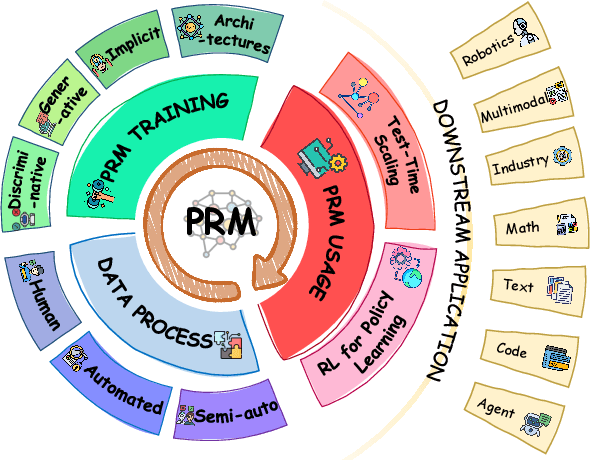

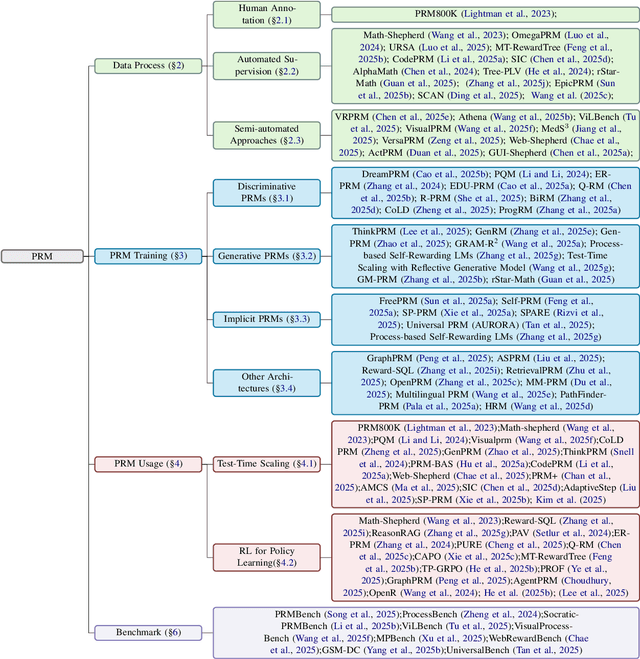
Although Large Language Models (LLMs) exhibit advanced reasoning ability, conventional alignment remains largely dominated by outcome reward models (ORMs) that judge only final answers. Process Reward Models(PRMs) address this gap by evaluating and guiding reasoning at the step or trajectory level. This survey provides a systematic overview of PRMs through the full loop: how to generate process data, build PRMs, and use PRMs for test-time scaling and reinforcement learning. We summarize applications across math, code, text, multimodal reasoning, robotics, and agents, and review emerging benchmarks. Our goal is to clarify design spaces, reveal open challenges, and guide future research toward fine-grained, robust reasoning alignment.
An Automatic Graph Construction Framework based on Large Language Models for Recommendation
Dec 24, 2024Graph neural networks (GNNs) have emerged as state-of-the-art methods to learn from graph-structured data for recommendation. However, most existing GNN-based recommendation methods focus on the optimization of model structures and learning strategies based on pre-defined graphs, neglecting the importance of the graph construction stage. Earlier works for graph construction usually rely on speciffic rules or crowdsourcing, which are either too simplistic or too labor-intensive. Recent works start to utilize large language models (LLMs) to automate the graph construction, in view of their abundant open-world knowledge and remarkable reasoning capabilities. Nevertheless, they generally suffer from two limitations: (1) invisibility of global view (e.g., overlooking contextual information) and (2) construction inefficiency. To this end, we introduce AutoGraph, an automatic graph construction framework based on LLMs for recommendation. Specifically, we first use LLMs to infer the user preference and item knowledge, which is encoded as semantic vectors. Next, we employ vector quantization to extract the latent factors from the semantic vectors. The latent factors are then incorporated as extra nodes to link the user/item nodes, resulting in a graph with in-depth global-view semantics. We further design metapath-based message aggregation to effectively aggregate the semantic and collaborative information. The framework is model-agnostic and compatible with different backbone models. Extensive experiments on three real-world datasets demonstrate the efficacy and efffciency of AutoGraph compared to existing baseline methods. We have deployed AutoGraph in Huawei advertising platform, and gain a 2.69% improvement on RPM and a 7.31% improvement on eCPM in the online A/B test. Currently AutoGraph has been used as the main trafffc model, serving hundreds of millions of people.
Learning ID-free Item Representation with Token Crossing for Multimodal Recommendation
Oct 25, 2024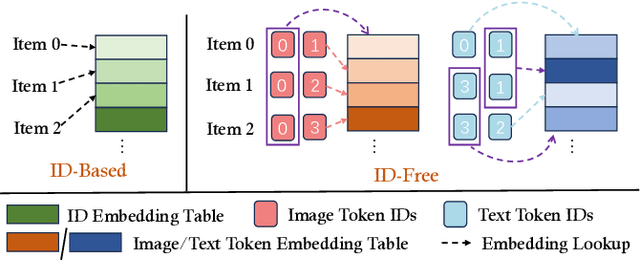
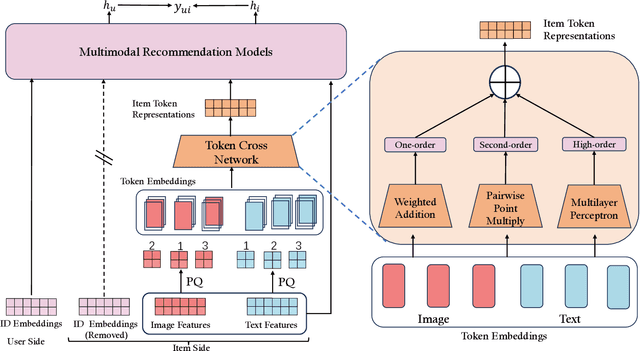
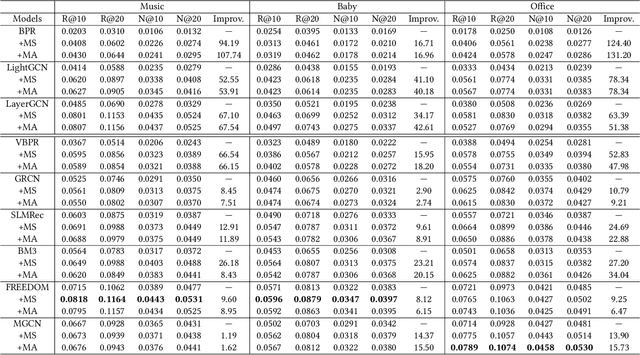
Current multimodal recommendation models have extensively explored the effective utilization of multimodal information; however, their reliance on ID embeddings remains a performance bottleneck. Even with the assistance of multimodal information, optimizing ID embeddings remains challenging for ID-based Multimodal Recommender when interaction data is sparse. Furthermore, the unique nature of item-specific ID embeddings hinders the information exchange among related items and the spatial requirement of ID embeddings increases with the scale of item. Based on these limitations, we propose an ID-free MultimOdal TOken Representation scheme named MOTOR that represents each item using learnable multimodal tokens and connects them through shared tokens. Specifically, we first employ product quantization to discretize each item's multimodal features (e.g., images, text) into discrete token IDs. We then interpret the token embeddings corresponding to these token IDs as implicit item features, introducing a new Token Cross Network to capture the implicit interaction patterns among these tokens. The resulting representations can replace the original ID embeddings and transform the original ID-based multimodal recommender into ID-free system, without introducing any additional loss design. MOTOR reduces the overall space requirements of these models, facilitating information interaction among related items, while also significantly enhancing the model's recommendation capability. Extensive experiments on nine mainstream models demonstrate the significant performance improvement achieved by MOTOR, highlighting its effectiveness in enhancing multimodal recommendation systems.
DRepMRec: A Dual Representation Learning Framework for Multimodal Recommendation
Apr 17, 2024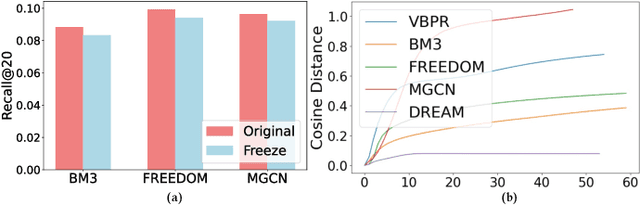
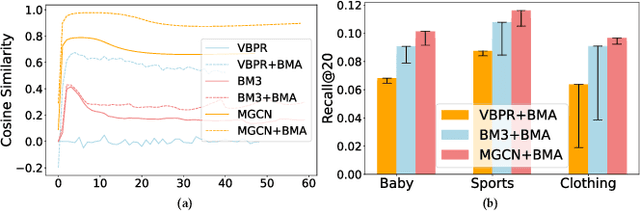
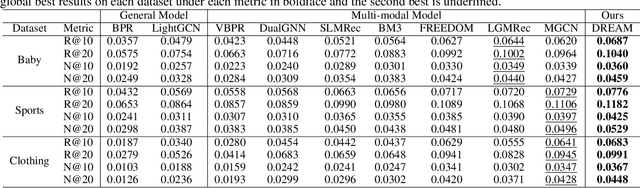
Multimodal Recommendation focuses mainly on how to effectively integrate behavior and multimodal information in the recommendation task. Previous works suffer from two major issues. Firstly, the training process tightly couples the behavior module and multimodal module by jointly optimizing them using the sharing model parameters, which leads to suboptimal performance since behavior signals and modality signals often provide opposite guidance for the parameters updates. Secondly, previous approaches fail to take into account the significant distribution differences between behavior and modality when they attempt to fuse behavior and modality information. This resulted in a misalignment between the representations of behavior and modality. To address these challenges, in this paper, we propose a novel Dual Representation learning framework for Multimodal Recommendation called DRepMRec, which introduce separate dual lines for coupling problem and Behavior-Modal Alignment (BMA) for misalignment problem. Specifically, DRepMRec leverages two independent lines of representation learning to calculate behavior and modal representations. After obtaining separate behavior and modal representations, we design a Behavior-Modal Alignment Module (BMA) to align and fuse the dual representations to solve the misalignment problem. Furthermore, we integrate the BMA into other recommendation models, resulting in consistent performance improvements. To ensure dual representations maintain their semantic independence during alignment, we introduce Similarity-Supervised Signal (SSS) for representation learning. We conduct extensive experiments on three public datasets and our method achieves state-of-the-art (SOTA) results. The source code will be available upon acceptance.
An Aligning and Training Framework for Multimodal Recommendations
Mar 20, 2024



With the development of multimedia applications, multimodal recommendations are playing an essential role, as they can leverage rich contexts beyond user interactions. Existing methods mainly regard multimodal information as an auxiliary, using them to help learn ID features; however, there exist semantic gaps among multimodal content features and ID features, for which directly using multimodal information as an auxiliary would lead to misalignment in representations of users and items. In this paper, we first systematically investigate the misalignment issue in multimodal recommendations, and propose a solution named AlignRec. In AlignRec, the recommendation objective is decomposed into three alignments, namely alignment within contents, alignment between content and categorical ID, and alignment between users and items. Each alignment is characterized by a specific objective function and is integrated into our multimodal recommendation framework. To effectively train our AlignRec, we propose starting from pre-training the first alignment to obtain unified multimodal features and subsequently training the following two alignments together with these features as input. As it is essential to analyze whether each multimodal feature helps in training, we design three new classes of metrics to evaluate intermediate performance. Our extensive experiments on three real-world datasets consistently verify the superiority of AlignRec compared to nine baselines. We also find that the multimodal features generated by AlignRec are better than currently used ones, which are to be open-sourced.