 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning ID-free Item Representation with Token Crossing for Multimodal Recommendation
Paper and Code
Oct 25, 2024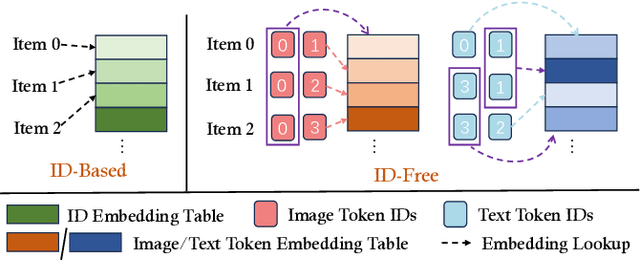
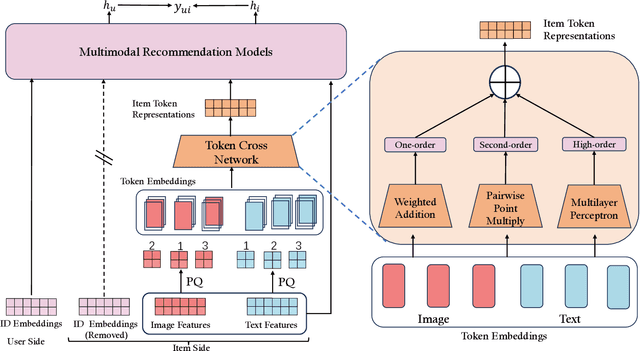
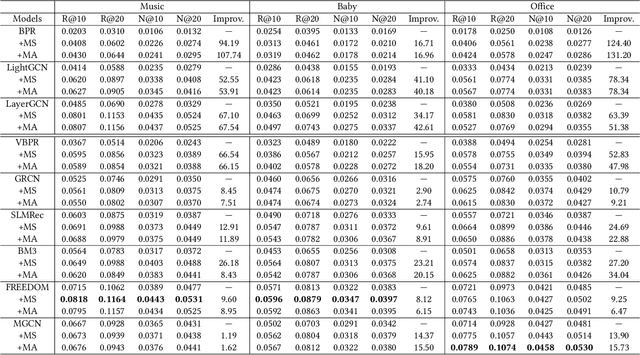
Current multimodal recommendation models have extensively explored the effective utilization of multimodal information; however, their reliance on ID embeddings remains a performance bottleneck. Even with the assistance of multimodal information, optimizing ID embeddings remains challenging for ID-based Multimodal Recommender when interaction data is sparse. Furthermore, the unique nature of item-specific ID embeddings hinders the information exchange among related items and the spatial requirement of ID embeddings increases with the scale of item. Based on these limitations, we propose an ID-free MultimOdal TOken Representation scheme named MOTOR that represents each item using learnable multimodal tokens and connects them through shared tokens. Specifically, we first employ product quantization to discretize each item's multimodal features (e.g., images, text) into discrete token IDs. We then interpret the token embeddings corresponding to these token IDs as implicit item features, introducing a new Token Cross Network to capture the implicit interaction patterns among these tokens. The resulting representations can replace the original ID embeddings and transform the original ID-based multimodal recommender into ID-free system, without introducing any additional loss design. MOTOR reduces the overall space requirements of these models, facilitating information interaction among related items, while also significantly enhancing the model's recommendation capability. Extensive experiments on nine mainstream models demonstrate the significant performance improvement achieved by MOTOR, highlighting its effectiveness in enhancing multimodal recommendation systems.