 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffCold: A Diffusion-based Generative Model for Cold-Start Item Recommendation
Jun 10, 2026Cold-start item recommendation remains a persistent challenge in real-world systems due to the absence of interaction histories. While prior models attempt to bridge this gap using item content features, they universally suffer from the \textbf{seesaw dilemma}: enhancing performance for cold items inevitably degrades performance for warm items, and vice versa. We identify that this dilemma stems from a fundamental \textbf{distributional disparity}: warm item embeddings occupy a complex ``behavioral manifold" shaped by rich interaction signals, whereas cold item embeddings are constrained to a ``semantic manifold" derived solely from auxiliary content. Existing methods often force a rigid mapping between these inconsistent spaces, causing the model to sacrifice the precision of warm representations to accommodate cold ones. To address this, we propose \textbf{DiffCold}, a diffusion-based generative model that unifies warm and cold representations. Unlike GANs or VAEs, DiffCold leverages conditional diffusion to reconstruct warm item embeddings from content, preserving the underlying manifold structure without degradation. We further tailor this paradigm with two specific designs: a \textbf{Retrieval-enhanced Aggregator} that initializes generation using semantically similar warm items to bypass inefficient noise, and a \textbf{Simulation-based Representation Alignment} module that enforces distribution consistency between generated and real embeddings via contrastive learning. Experiments on three benchmarks confirm that DiffCold resolves the seesaw dilemma, consistently outperforming state-of-the-art methods across all metrics.
LASER: An Efficient Target-Aware Segmented Attention Framework for End-to-End Long Sequence Modeling
Feb 12, 2026Modeling ultra-long user behavior sequences is pivotal for capturing evolving and lifelong interests in modern recommendation systems. However, deploying such models in real-time industrial environments faces a strict "Latency Wall", constrained by two distinct bottlenecks: the high I/O latency of retrieving massive user histories and the quadratic computational complexity of standard attention mechanisms. To break these bottlenecks, we present LASER, a full-stack optimization framework developed and deployed at Xiaohongshu (RedNote). Our approach tackles the challenges through two complementary innovations: (1) System efficiency: We introduce SeqVault, a unified schema-aware serving infrastructure for long user histories. By implementing a hybrid DRAM-SSD indexing strategy, SeqVault reduces retrieval latency by 50% and CPU usage by 75%, ensuring millisecond-level access to full real-time and life-cycle user histories. (2) Algorithmic efficiency: We propose a Segmented Target Attention (STA) mechanism to address the computational overhead. Motivated by the inherent sparsity of user interests, STA employs a sigmoid-based gating strategy that acts as a silence mechanism to filter out noisy items. Subsequently, a lightweight Global Stacked Target Attention (GSTA) module refines these compressed segments to capture cross-segment dependencies without incurring high computational costs. This design performs effective sequence compression, reducing the complexity of long-sequence modeling while preserving critical signals. Extensive offline evaluations demonstrate that LASER consistently outperforms state-of-the-art baselines. In large-scale online A/B testing serving over 100 million daily active users, LASER achieved a 2.36% lift in ADVV and a 2.08% lift in revenue, demonstrating its scalability and significant commercial impact.
HoPE: Hybrid of Position Embedding for Length Generalization in Vision-Language Models
May 26, 2025Vision-Language Models (VLMs) have made significant progress in multimodal tasks. However, their performance often deteriorates in long-context scenarios, particularly long videos. While Rotary Position Embedding (RoPE) has been widely adopted for length generalization in Large Language Models (LLMs), extending vanilla RoPE to capture the intricate spatial-temporal dependencies in videos remains an unsolved challenge. Existing methods typically allocate different frequencies within RoPE to encode 3D positional information. However, these allocation strategies mainly rely on heuristics, lacking in-depth theoretical analysis. In this paper, we first study how different allocation strategies impact the long-context capabilities of VLMs. Our analysis reveals that current multimodal RoPEs fail to reliably capture semantic similarities over extended contexts. To address this issue, we propose HoPE, a Hybrid of Position Embedding designed to improve the long-context capabilities of VLMs. HoPE introduces a hybrid frequency allocation strategy for reliable semantic modeling over arbitrarily long context, and a dynamic temporal scaling mechanism to facilitate robust learning and flexible inference across diverse context lengths. Extensive experiments across four video benchmarks on long video understanding and retrieval tasks demonstrate that HoPE consistently outperforms existing methods, confirming its effectiveness. Code is available at https://github.com/hrlics/HoPE.
Learning ID-free Item Representation with Token Crossing for Multimodal Recommendation
Oct 25, 2024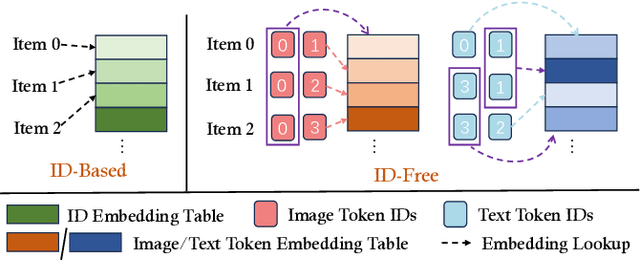
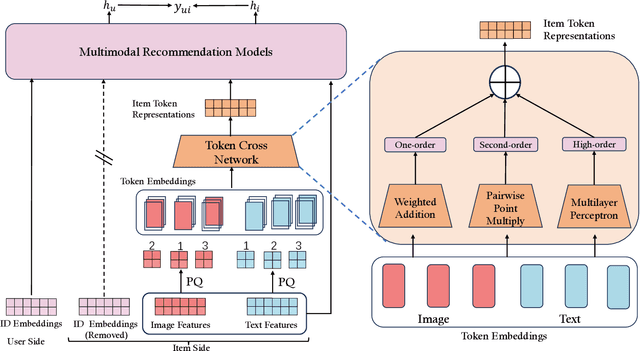
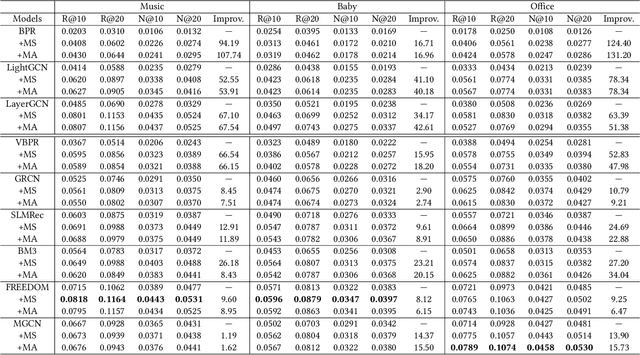
Current multimodal recommendation models have extensively explored the effective utilization of multimodal information; however, their reliance on ID embeddings remains a performance bottleneck. Even with the assistance of multimodal information, optimizing ID embeddings remains challenging for ID-based Multimodal Recommender when interaction data is sparse. Furthermore, the unique nature of item-specific ID embeddings hinders the information exchange among related items and the spatial requirement of ID embeddings increases with the scale of item. Based on these limitations, we propose an ID-free MultimOdal TOken Representation scheme named MOTOR that represents each item using learnable multimodal tokens and connects them through shared tokens. Specifically, we first employ product quantization to discretize each item's multimodal features (e.g., images, text) into discrete token IDs. We then interpret the token embeddings corresponding to these token IDs as implicit item features, introducing a new Token Cross Network to capture the implicit interaction patterns among these tokens. The resulting representations can replace the original ID embeddings and transform the original ID-based multimodal recommender into ID-free system, without introducing any additional loss design. MOTOR reduces the overall space requirements of these models, facilitating information interaction among related items, while also significantly enhancing the model's recommendation capability. Extensive experiments on nine mainstream models demonstrate the significant performance improvement achieved by MOTOR, highlighting its effectiveness in enhancing multimodal recommendation systems.
DRepMRec: A Dual Representation Learning Framework for Multimodal Recommendation
Apr 17, 2024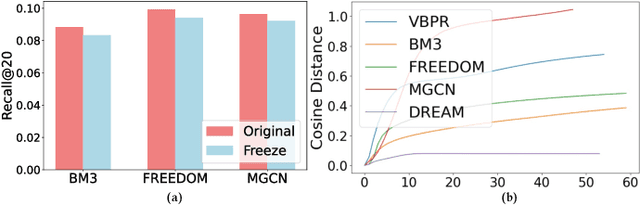
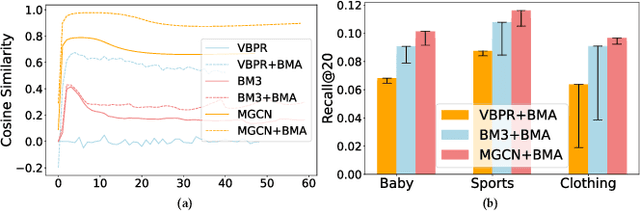
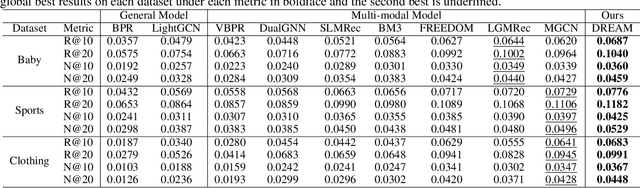
Multimodal Recommendation focuses mainly on how to effectively integrate behavior and multimodal information in the recommendation task. Previous works suffer from two major issues. Firstly, the training process tightly couples the behavior module and multimodal module by jointly optimizing them using the sharing model parameters, which leads to suboptimal performance since behavior signals and modality signals often provide opposite guidance for the parameters updates. Secondly, previous approaches fail to take into account the significant distribution differences between behavior and modality when they attempt to fuse behavior and modality information. This resulted in a misalignment between the representations of behavior and modality. To address these challenges, in this paper, we propose a novel Dual Representation learning framework for Multimodal Recommendation called DRepMRec, which introduce separate dual lines for coupling problem and Behavior-Modal Alignment (BMA) for misalignment problem. Specifically, DRepMRec leverages two independent lines of representation learning to calculate behavior and modal representations. After obtaining separate behavior and modal representations, we design a Behavior-Modal Alignment Module (BMA) to align and fuse the dual representations to solve the misalignment problem. Furthermore, we integrate the BMA into other recommendation models, resulting in consistent performance improvements. To ensure dual representations maintain their semantic independence during alignment, we introduce Similarity-Supervised Signal (SSS) for representation learning. We conduct extensive experiments on three public datasets and our method achieves state-of-the-art (SOTA) results. The source code will be available upon acceptance.
An Aligning and Training Framework for Multimodal Recommendations
Mar 20, 2024



With the development of multimedia applications, multimodal recommendations are playing an essential role, as they can leverage rich contexts beyond user interactions. Existing methods mainly regard multimodal information as an auxiliary, using them to help learn ID features; however, there exist semantic gaps among multimodal content features and ID features, for which directly using multimodal information as an auxiliary would lead to misalignment in representations of users and items. In this paper, we first systematically investigate the misalignment issue in multimodal recommendations, and propose a solution named AlignRec. In AlignRec, the recommendation objective is decomposed into three alignments, namely alignment within contents, alignment between content and categorical ID, and alignment between users and items. Each alignment is characterized by a specific objective function and is integrated into our multimodal recommendation framework. To effectively train our AlignRec, we propose starting from pre-training the first alignment to obtain unified multimodal features and subsequently training the following two alignments together with these features as input. As it is essential to analyze whether each multimodal feature helps in training, we design three new classes of metrics to evaluate intermediate performance. Our extensive experiments on three real-world datasets consistently verify the superiority of AlignRec compared to nine baselines. We also find that the multimodal features generated by AlignRec are better than currently used ones, which are to be open-sourced.