 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRepMRec: A Dual Representation Learning Framework for Multimodal Recommendation
Paper and Code
Apr 17, 2024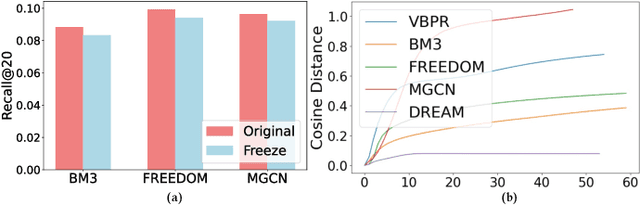
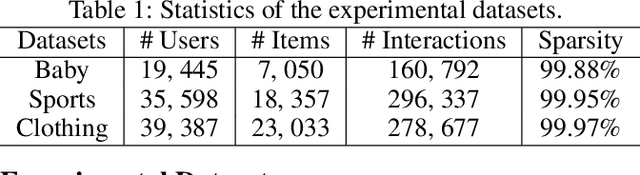
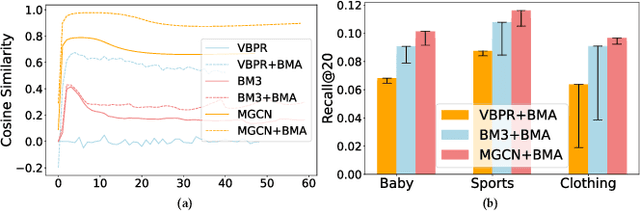
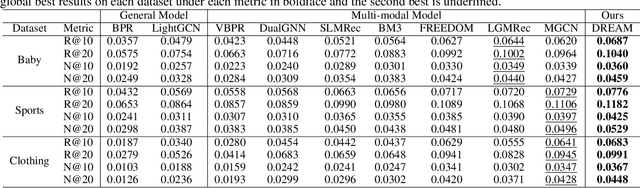
Multimodal Recommendation focuses mainly on how to effectively integrate behavior and multimodal information in the recommendation task. Previous works suffer from two major issues. Firstly, the training process tightly couples the behavior module and multimodal module by jointly optimizing them using the sharing model parameters, which leads to suboptimal performance since behavior signals and modality signals often provide opposite guidance for the parameters updates. Secondly, previous approaches fail to take into account the significant distribution differences between behavior and modality when they attempt to fuse behavior and modality information. This resulted in a misalignment between the representations of behavior and modality. To address these challenges, in this paper, we propose a novel Dual Representation learning framework for Multimodal Recommendation called DRepMRec, which introduce separate dual lines for coupling problem and Behavior-Modal Alignment (BMA) for misalignment problem. Specifically, DRepMRec leverages two independent lines of representation learning to calculate behavior and modal representations. After obtaining separate behavior and modal representations, we design a Behavior-Modal Alignment Module (BMA) to align and fuse the dual representations to solve the misalignment problem. Furthermore, we integrate the BMA into other recommendation models, resulting in consistent performance improvements. To ensure dual representations maintain their semantic independence during alignment, we introduce Similarity-Supervised Signal (SSS) for representation learning. We conduct extensive experiments on three public datasets and our method achieves state-of-the-art (SOTA) results. The source code will be available upon acceptance.