 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan-MCTS: Plan Exploration for Action Exploitation in Web Navigation
Feb 15, 2026Large Language Models (LLMs) have empowered autonomous agents to handle complex web navigation tasks. While recent studies integrate tree search to enhance long-horizon reasoning, applying these algorithms in web navigation faces two critical challenges: sparse valid paths that lead to inefficient exploration, and a noisy context that dilutes accurate state perception. To address this, we introduce Plan-MCTS, a framework that reformulates web navigation by shifting exploration to a semantic Plan Space. By decoupling strategic planning from execution grounding, it transforms sparse action space into a Dense Plan Tree for efficient exploration, and distills noisy contexts into an Abstracted Semantic History for precise state awareness. To ensure efficiency and robustness, Plan-MCTS incorporates a Dual-Gating Reward to strictly validate both physical executability and strategic alignment and Structural Refinement for on-policy repair of failed subplans. Extensive experiments on WebArena demonstrate that Plan-MCTS achieves state-of-the-art performance, surpassing current approaches with higher task effectiveness and search efficiency.
LogitsCoder: Towards Efficient Chain-of-Thought Path Search via Logits Preference Decoding for Code Generation
Feb 15, 2026Code generation remains a challenging task that requires precise and structured reasoning. Existing Test Time Scaling (TTS) methods, including structured tree search, have made progress in exploring reasoning paths but still face two major challenges: (1) underthinking, where reasoning chains tend to be shallow and fail to capture the full complexity of problems; and (2) overthinking, where overly verbose reasoning leads to inefficiency and increased computational costs. To address these issues, we propose LogitsCoder, a novel framework that enhances chain-of-thought reasoning through lightweight, logit-level control mechanisms for code generation. LogitsCoder iteratively generates and refines reasoning steps by first steering token selection toward statistically preferred patterns via Logits Preference Decoding, then selecting and aggregating diverse reasoning paths using Logits Rank Based Path Selection and Thoughts Aggregation. This results in coherent and effective reasoning chains that balance depth and efficiency. Extensive experiments demonstrate that LogitsCoder produces more efficient and higher-quality reasoning chains, leading to superior code generation performance compared to baseline methods.
Adaptive Milestone Reward for GUI Agents
Feb 12, 2026Reinforcement Learning (RL) has emerged as a mainstream paradigm for training Mobile GUI Agents, yet it struggles with the temporal credit assignment problem inherent in long-horizon tasks. A primary challenge lies in the trade-off between reward fidelity and density: outcome reward offers high fidelity but suffers from signal sparsity, while process reward provides dense supervision but remains prone to bias and reward hacking. To resolve this conflict, we propose the Adaptive Milestone Reward (ADMIRE) mechanism. ADMIRE constructs a verifiable, adaptive reward system by anchoring trajectory to milestones, which are dynamically distilled from successful explorations. Crucially, ADMIRE integrates an asymmetric credit assignment strategy that denoises successful trajectories and scaffolds failed trajectories. Extensive experiments demonstrate that ADMIRE consistently yields over 10% absolute improvement in success rate across different base models on AndroidWorld. Moreover, the method exhibits robust generalizability, achieving strong performance across diverse RL algorithms and heterogeneous environments such as web navigation and embodied tasks.
ReMiT: RL-Guided Mid-Training for Iterative LLM Evolution
Feb 03, 2026Standard training pipelines for large language models (LLMs) are typically unidirectional, progressing from pre-training to post-training. However, the potential for a bidirectional process--where insights from post-training retroactively improve the pre-trained foundation--remains unexplored. We aim to establish a self-reinforcing flywheel: a cycle in which reinforcement learning (RL)-tuned model strengthens the base model, which in turn enhances subsequent post-training performance, requiring no specially trained teacher or reference model. To realize this, we analyze training dynamics and identify the mid-training (annealing) phase as a critical turning point for model capabilities. This phase typically occurs at the end of pre-training, utilizing high-quality corpora under a rapidly decaying learning rate. Building upon this insight, we introduce ReMiT (Reinforcement Learning-Guided Mid-Training). Specifically, ReMiT leverages the reasoning priors of RL-tuned models to dynamically reweight tokens during the mid-training phase, prioritizing those pivotal for reasoning. Empirically, ReMiT achieves an average improvement of 3\% on 10 pre-training benchmarks, spanning math, code, and general reasoning, and sustains these gains by over 2\% throughout the post-training pipeline. These results validate an iterative feedback loop, enabling continuous and self-reinforcing evolution of LLMs.
UniCon: A Unified System for Efficient Robot Learning Transfers
Jan 21, 2026Deploying learning-based controllers across heterogeneous robots is challenging due to platform differences, inconsistent interfaces, and inefficient middleware. To address these issues, we present UniCon, a lightweight framework that standardizes states, control flow, and instrumentation across platforms. It decomposes workflows into execution graphs with reusable components, separating system states from control logic to enable plug-and-play deployment across various robot morphologies. Unlike traditional middleware, it prioritizes efficiency through batched, vectorized data flow, minimizing communication overhead and improving inference latency. This modular, data-oriented approach enables seamless sim-to-real transfer with minimal re-engineering. We demonstrate that UniCon reduces code redundancy when transferring workflows and achieves higher inference efficiency compared to ROS-based systems. Deployed on over 12 robot models from 7 manufacturers, it has been successfully integrated into ongoing research projects, proving its effectiveness in real-world scenarios.
LoopTool: Closing the Data-Training Loop for Robust LLM Tool Calls
Nov 18, 2025
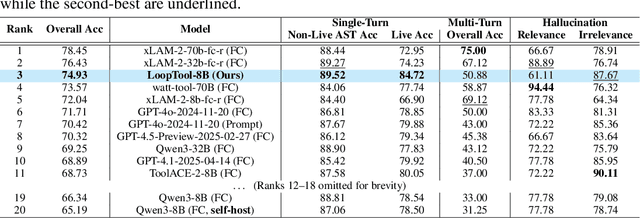
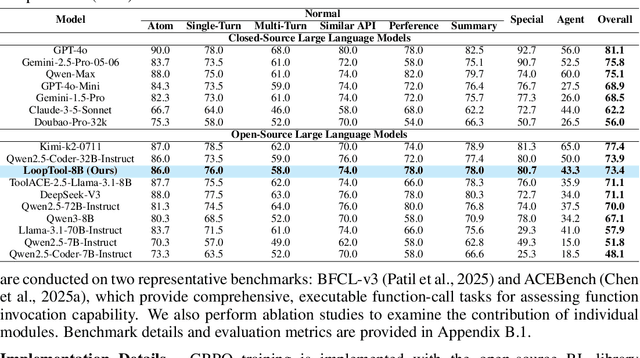
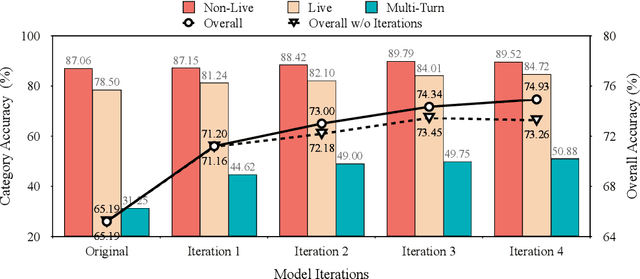
Augmenting Large Language Models (LLMs) with external tools enables them to execute complex, multi-step tasks. However, tool learning is hampered by the static synthetic data pipelines where data generation and model training are executed as two separate, non-interactive processes. This approach fails to adaptively focus on a model's specific weaknesses and allows noisy labels to persist, degrading training efficiency. We introduce LoopTool, a fully automated, model-aware data evolution framework that closes this loop by tightly integrating data synthesis and model training. LoopTool iteratively refines both the data and the model through three synergistic modules: (1) Greedy Capability Probing (GCP) diagnoses the model's mastered and failed capabilities; (2) Judgement-Guided Label Verification (JGLV) uses an open-source judge model to find and correct annotation errors, progressively purifying the dataset; and (3) Error-Driven Data Expansion (EDDE) generates new, challenging samples based on identified failures. This closed-loop process operates within a cost-effective, open-source ecosystem, eliminating dependence on expensive closed-source APIs. Experiments show that our 8B model trained with LoopTool significantly surpasses its 32B data generator and achieves new state-of-the-art results on the BFCL-v3 and ACEBench benchmarks for its scale. Our work demonstrates that closed-loop, self-refining data pipelines can dramatically enhance the tool-use capabilities of LLMs.
Fints: Efficient Inference-Time Personalization for LLMs with Fine-Grained Instance-Tailored Steering
Oct 31, 2025The rapid evolution of large language models (LLMs) has intensified the demand for effective personalization techniques that can adapt model behavior to individual user preferences. Despite the non-parametric methods utilizing the in-context learning ability of LLMs, recent parametric adaptation methods, including personalized parameter-efficient fine-tuning and reward modeling emerge. However, these methods face limitations in handling dynamic user patterns and high data sparsity scenarios, due to low adaptability and data efficiency. To address these challenges, we propose a fine-grained and instance-tailored steering framework that dynamically generates sample-level interference vectors from user data and injects them into the model's forward pass for personalized adaptation. Our approach introduces two key technical innovations: a fine-grained steering component that captures nuanced signals by hooking activations from attention and MLP layers, and an input-aware aggregation module that synthesizes these signals into contextually relevant enhancements. The method demonstrates high flexibility and data efficiency, excelling in fast-changing distribution and high data sparsity scenarios. In addition, the proposed method is orthogonal to existing methods and operates as a plug-in component compatible with different personalization techniques. Extensive experiments across diverse scenarios--including short-to-long text generation, and web function calling--validate the effectiveness and compatibility of our approach. Results show that our method significantly enhances personalization performance in fast-shifting environments while maintaining robustness across varying interaction modes and context lengths. Implementation is available at https://github.com/KounianhuaDu/Fints.
CATArena: Evaluation of LLM Agents through Iterative Tournament Competitions
Oct 30, 2025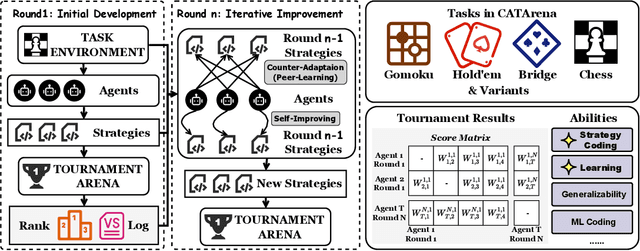

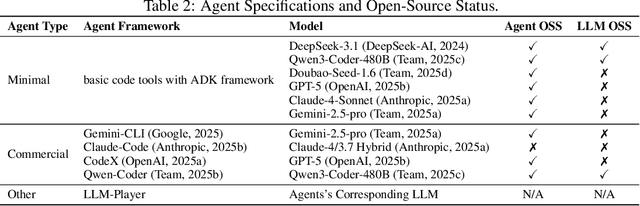
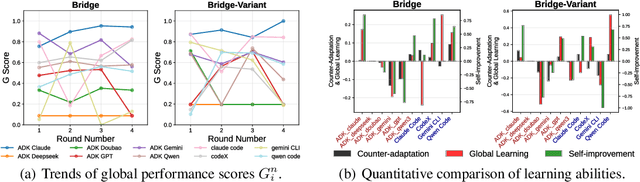
Large Language Model (LLM) agents have evolved from basic text generation to autonomously completing complex tasks through interaction with external tools. However, current benchmarks mainly assess end-to-end performance in fixed scenarios, restricting evaluation to specific skills and suffering from score saturation and growing dependence on expert annotation as agent capabilities improve. In this work, we emphasize the importance of learning ability, including both self-improvement and peer-learning, as a core driver for agent evolution toward human-level intelligence. We propose an iterative, competitive peer-learning framework, which allows agents to refine and optimize their strategies through repeated interactions and feedback, thereby systematically evaluating their learning capabilities. To address the score saturation issue in current benchmarks, we introduce CATArena, a tournament-style evaluation platform featuring four diverse board and card games with open-ended scoring. By providing tasks without explicit upper score limits, CATArena enables continuous and dynamic evaluation of rapidly advancing agent capabilities. Experimental results and analyses involving both minimal and commercial code agents demonstrate that CATArena provides reliable, stable, and scalable benchmarking for core agent abilities, particularly learning ability and strategy coding.
A Survey of Process Reward Models: From Outcome Signals to Process Supervisions for Large Language Models
Oct 09, 2025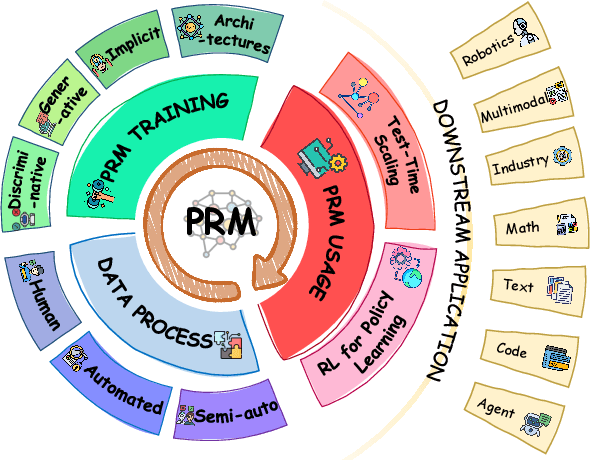

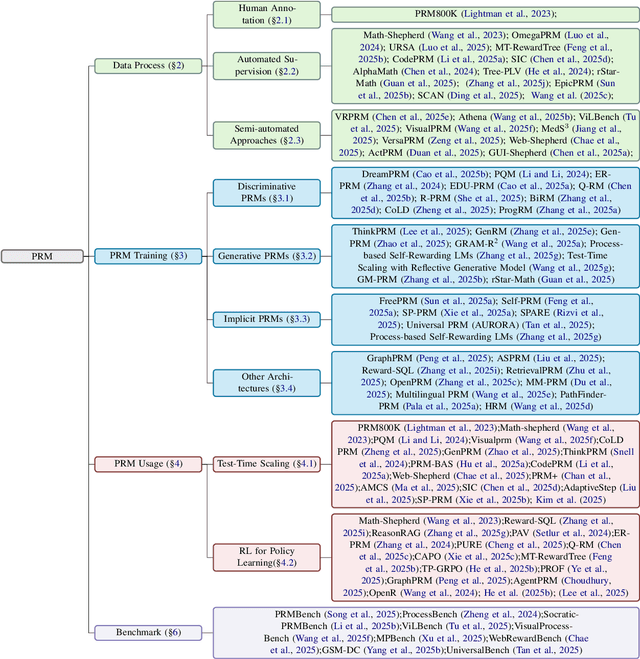
Although Large Language Models (LLMs) exhibit advanced reasoning ability, conventional alignment remains largely dominated by outcome reward models (ORMs) that judge only final answers. Process Reward Models(PRMs) address this gap by evaluating and guiding reasoning at the step or trajectory level. This survey provides a systematic overview of PRMs through the full loop: how to generate process data, build PRMs, and use PRMs for test-time scaling and reinforcement learning. We summarize applications across math, code, text, multimodal reasoning, robotics, and agents, and review emerging benchmarks. Our goal is to clarify design spaces, reveal open challenges, and guide future research toward fine-grained, robust reasoning alignment.
Fast, Slow, and Tool-augmented Thinking for LLMs: A Review
Aug 17, 2025Large Language Models (LLMs) have demonstrated remarkable progress in reasoning across diverse domains. However, effective reasoning in real-world tasks requires adapting the reasoning strategy to the demands of the problem, ranging from fast, intuitive responses to deliberate, step-by-step reasoning and tool-augmented thinking. Drawing inspiration from cognitive psychology, we propose a novel taxonomy of LLM reasoning strategies along two knowledge boundaries: a fast/slow boundary separating intuitive from deliberative processes, and an internal/external boundary distinguishing reasoning grounded in the model's parameters from reasoning augmented by external tools. We systematically survey recent work on adaptive reasoning in LLMs and categorize methods based on key decision factors. We conclude by highlighting open challenges and future directions toward more adaptive, efficient, and reliable LLMs.