 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of AI Agent Protocols
Apr 23, 2025The rapid development of large language models (LLMs) has led to the widespread deployment of LLM agents across diverse industries, including customer service, content generation, data analysis, and even healthcare. However, as more LLM agents are deployed, a major issue has emerged: there is no standard way for these agents to communicate with external tools or data sources. This lack of standardized protocols makes it difficult for agents to work together or scale effectively, and it limits their ability to tackle complex, real-world tasks. A unified communication protocol for LLM agents could change this. It would allow agents and tools to interact more smoothly, encourage collaboration, and triggering the formation of collective intelligence. In this paper, we provide a systematic overview of existing communication protocols for LLM agents. We classify them into four main categories and make an analysis to help users and developers select the most suitable protocols for specific applications. Additionally, we conduct a comparative performance analysis of these protocols across key dimensions such as security, scalability, and latency. Finally, we explore future challenges, such as how protocols can adapt and survive in fast-evolving environments, and what qualities future protocols might need to support the next generation of LLM agent ecosystems. We expect this work to serve as a practical reference for both researchers and engineers seeking to design, evaluate, or integrate robust communication infrastructures for intelligent agents.
AgentNet: Decentralized Evolutionary Coordination for LLM-based Multi-Agent Systems
Apr 01, 2025The rapid advancement of Large Language Models (LLMs) has catalyzed the development of multi-agent systems, where multiple LLM-based agents collaborate to solve complex tasks. However, existing systems predominantly rely on centralized coordination, which introduces scalability bottlenecks, limits adaptability, and creates single points of failure. Additionally, concerns over privacy and proprietary knowledge sharing hinder cross-organizational collaboration, leading to siloed expertise. To address these challenges, we propose AgentNet, a decentralized, Retrieval-Augmented Generation (RAG)-based framework that enables LLM-based agents to autonomously evolve their capabilities and collaborate efficiently in a Directed Acyclic Graph (DAG)-structured network. Unlike traditional multi-agent systems that depend on static role assignments or centralized control, AgentNet allows agents to specialize dynamically, adjust their connectivity, and route tasks without relying on predefined workflows. AgentNet's core design is built upon several key innovations: (1) Fully Decentralized Paradigm: Removing the central orchestrator, allowing agents to coordinate and specialize autonomously, fostering fault tolerance and emergent collective intelligence. (2) Dynamically Evolving Graph Topology: Real-time adaptation of agent connections based on task demands, ensuring scalability and resilience.(3) Adaptive Learning for Expertise Refinement: A retrieval-based memory system that enables agents to continuously update and refine their specialized skills. By eliminating centralized control, AgentNet enhances fault tolerance, promotes scalable specialization, and enables privacy-preserving collaboration across organizations. Through decentralized coordination and minimal data exchange, agents can leverage diverse knowledge sources while safeguarding sensitive information.
CodeGRAG: Extracting Composed Syntax Graphs for Retrieval Augmented Cross-Lingual Code Generation
May 03, 2024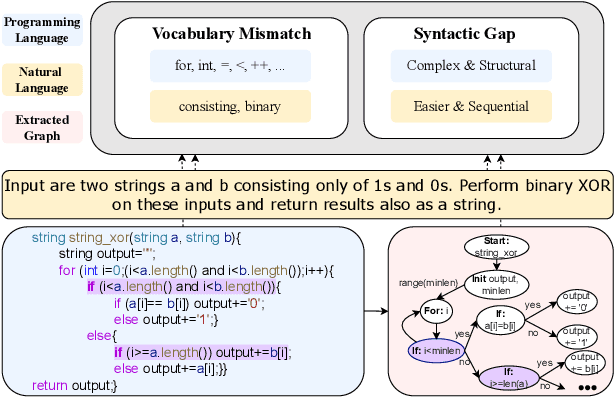
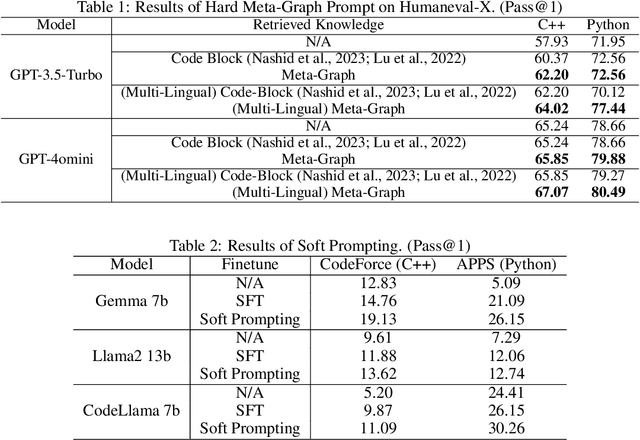
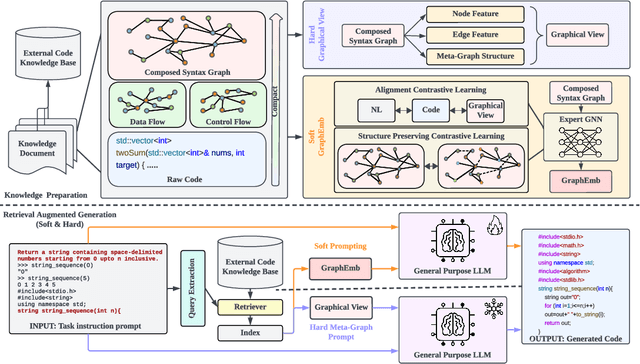
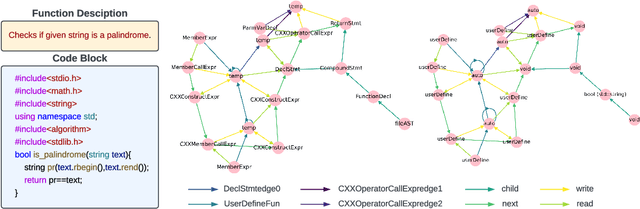
Utilizing large language models to generate codes has shown promising meaning in software development revolution. Despite the intelligence shown by the general large language models, their specificity in code generation can still be improved due to the syntactic gap and mismatched vocabulary existing among natural language and different programming languages. In addition, programming languages are inherently logical and complex, making them hard to be correctly generated. Existing methods rely on multiple prompts to the large language model to explore better solutions, which is expensive. In this paper, we propose Syntax Graph Retrieval Augmented Code Generation (CodeGRAG) to enhance the performance of LLMs in single-round code generation tasks. CodeGRAG extracts and summarizes the control flow and data flow of code blocks to fill the gap between programming languages and natural language. The extracted external structural knowledge models the inherent flows of code blocks, which can facilitate LLMs for better understanding of code syntax and serve as a bridge among different programming languages. CodeGRAG significantly improves the code generation ability of LLMs and can even offer performance gain for cross-lingual code generation, e.g., C++ for Python.
CodeApex: A Bilingual Programming Evaluation Benchmark for Large Language Models
Sep 10, 2023



With the emergence of Large Language Models (LLMs), there has been a significant improvement in the programming capabilities of models, attracting growing attention from researchers. We propose CodeApex, a bilingual benchmark dataset focusing on the programming comprehension and code generation abilities of LLMs. CodeApex comprises three types of multiple-choice questions: conceptual understanding, commonsense reasoning, and multi-hop reasoning, designed to evaluate LLMs on programming comprehension tasks. Additionally, CodeApex utilizes algorithmic questions and corresponding test cases to assess the code quality generated by LLMs. We evaluate 14 state-of-the-art LLMs, including both general-purpose and specialized models. GPT exhibits the best programming capabilities, achieving approximate accuracies of 50% and 56% on the two tasks, respectively. There is still significant room for improvement in programming tasks. We hope that CodeApex can serve as a reference for evaluating the coding capabilities of LLMs, further promoting their development and growth. Datasets are released at https://github.com/APEXLAB/CodeApex.git. CodeApex submission website is https://apex.sjtu.edu.cn/codeapex/.