 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
DynaTree: Dynamic Agentic Retrieval Tree for Time-Sensitive News Retrieval
May 29, 2026Agentic Retrieval-Augmented Generation improves retrieval by integrating planning, tool use, and iterative reasoning, but existing agentic RAG methods often couple semantic expansion with retrieval decisions in short-horizon inference loops, leading to high inference cost and limited suitability for time-sensitive news retrieval. We propose DynaTree, a two-stage framework for efficient and adaptive news retrieval. In the offline stage, DynaTree uses coordinated agents to construct a reusable retrieval tree that materializes the semantic space of a query topic. In the online stage, DynaTree performs lightweight daily subtree selection over a time-localized evaluation proxy, without further agentic reasoning, tree modification, or retraining. Experiments on a multi-day Syft news benchmark and multiple BEIR datasets show that DynaTree achieves strong recall and ranking performance, consistently outperforming standard RAG and prior agentic baselines. We further deploy DynaTree in the Syft production system and evaluate it through online A/B testing from Jan. 28 to Feb. 6, 2026. The dynamically adapted variant improves survival rate from 0.32-0.53 to 0.59-0.73 over a fixed offline-selected subtree and outperforms existing production recallers on every evaluation day. These results show that persistent, structure-aware semantic expansion can translate offline agentic reasoning into practical improvements in coverage, freshness, and relevance for real-world news retrieval.
Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity
Feb 03, 2026LLM-based multi-agent systems (MAS) have emerged as a promising approach to tackle complex tasks that are difficult for individual LLMs. A natural strategy is to scale performance by increasing the number of agents; however, we find that such scaling exhibits strong diminishing returns in homogeneous settings, while introducing heterogeneity (e.g., different models, prompts, or tools) continues to yield substantial gains. This raises a fundamental question: what limits scaling, and why does diversity help? We present an information-theoretic framework showing that MAS performance is bounded by the intrinsic task uncertainty, not by agent count. We derive architecture-agnostic bounds demonstrating that improvements depend on how many effective channels the system accesses. Homogeneous agents saturate early because their outputs are strongly correlated, whereas heterogeneous agents contribute complementary evidence. We further introduce $K^*$, an effective channel count that quantifies the number of effective channels without ground-truth labels. Empirically, we show that heterogeneous configurations consistently outperform homogeneous scaling: 2 diverse agents can match or exceed the performance of 16 homogeneous agents. Our results provide principled guidelines for building efficient and robust MAS through diversity-aware design. Code and Dataset are available at the link: https://github.com/SafeRL-Lab/Agent-Scaling.
EnvX: Agentize Everything with Agentic AI
Sep 09, 2025


The widespread availability of open-source repositories has led to a vast collection of reusable software components, yet their utilization remains manual, error-prone, and disconnected. Developers must navigate documentation, understand APIs, and write integration code, creating significant barriers to efficient software reuse. To address this, we present EnvX, a framework that leverages Agentic AI to agentize GitHub repositories, transforming them into intelligent, autonomous agents capable of natural language interaction and inter-agent collaboration. Unlike existing approaches that treat repositories as static code resources, EnvX reimagines them as active agents through a three-phase process: (1) TODO-guided environment initialization, which sets up the necessary dependencies, data, and validation datasets; (2) human-aligned agentic automation, allowing repository-specific agents to autonomously perform real-world tasks; and (3) Agent-to-Agent (A2A) protocol, enabling multiple agents to collaborate. By combining large language model capabilities with structured tool integration, EnvX automates not just code generation, but the entire process of understanding, initializing, and operationalizing repository functionality. We evaluate EnvX on the GitTaskBench benchmark, using 18 repositories across domains such as image processing, speech recognition, document analysis, and video manipulation. Our results show that EnvX achieves a 74.07% execution completion rate and 51.85% task pass rate, outperforming existing frameworks. Case studies further demonstrate EnvX's ability to enable multi-repository collaboration via the A2A protocol. This work marks a shift from treating repositories as passive code resources to intelligent, interactive agents, fostering greater accessibility and collaboration within the open-source ecosystem.
A Survey of AI Agent Protocols
Apr 23, 2025The rapid development of large language models (LLMs) has led to the widespread deployment of LLM agents across diverse industries, including customer service, content generation, data analysis, and even healthcare. However, as more LLM agents are deployed, a major issue has emerged: there is no standard way for these agents to communicate with external tools or data sources. This lack of standardized protocols makes it difficult for agents to work together or scale effectively, and it limits their ability to tackle complex, real-world tasks. A unified communication protocol for LLM agents could change this. It would allow agents and tools to interact more smoothly, encourage collaboration, and triggering the formation of collective intelligence. In this paper, we provide a systematic overview of existing communication protocols for LLM agents. We classify them into four main categories and make an analysis to help users and developers select the most suitable protocols for specific applications. Additionally, we conduct a comparative performance analysis of these protocols across key dimensions such as security, scalability, and latency. Finally, we explore future challenges, such as how protocols can adapt and survive in fast-evolving environments, and what qualities future protocols might need to support the next generation of LLM agent ecosystems. We expect this work to serve as a practical reference for both researchers and engineers seeking to design, evaluate, or integrate robust communication infrastructures for intelligent agents.
AgentNet: Decentralized Evolutionary Coordination for LLM-based Multi-Agent Systems
Apr 01, 2025The rapid advancement of Large Language Models (LLMs) has catalyzed the development of multi-agent systems, where multiple LLM-based agents collaborate to solve complex tasks. However, existing systems predominantly rely on centralized coordination, which introduces scalability bottlenecks, limits adaptability, and creates single points of failure. Additionally, concerns over privacy and proprietary knowledge sharing hinder cross-organizational collaboration, leading to siloed expertise. To address these challenges, we propose AgentNet, a decentralized, Retrieval-Augmented Generation (RAG)-based framework that enables LLM-based agents to autonomously evolve their capabilities and collaborate efficiently in a Directed Acyclic Graph (DAG)-structured network. Unlike traditional multi-agent systems that depend on static role assignments or centralized control, AgentNet allows agents to specialize dynamically, adjust their connectivity, and route tasks without relying on predefined workflows. AgentNet's core design is built upon several key innovations: (1) Fully Decentralized Paradigm: Removing the central orchestrator, allowing agents to coordinate and specialize autonomously, fostering fault tolerance and emergent collective intelligence. (2) Dynamically Evolving Graph Topology: Real-time adaptation of agent connections based on task demands, ensuring scalability and resilience.(3) Adaptive Learning for Expertise Refinement: A retrieval-based memory system that enables agents to continuously update and refine their specialized skills. By eliminating centralized control, AgentNet enhances fault tolerance, promotes scalable specialization, and enables privacy-preserving collaboration across organizations. Through decentralized coordination and minimal data exchange, agents can leverage diverse knowledge sources while safeguarding sensitive information.
Multi-LLM-Agent Systems: Techniques and Business Perspectives
Nov 21, 2024


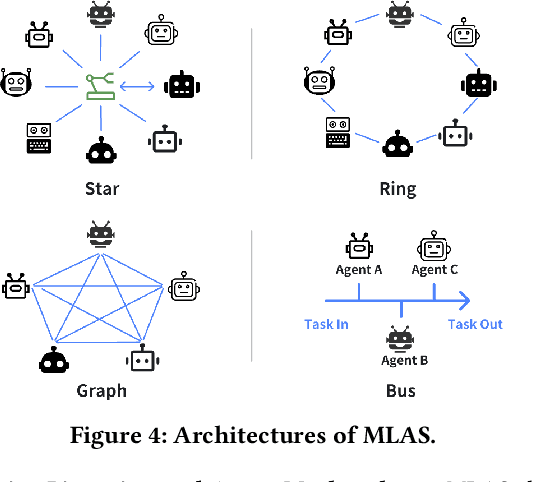
In the era of (multi-modal) large language models, most operational processes can be reformulated and reproduced using LLM agents. The LLM agents can perceive, control, and get feedback from the environment so as to accomplish the given tasks in an autonomous manner. Besides the environment-interaction property, the LLM agents can call various external tools to ease the task completion process. The tools can be regarded as a predefined operational process with private or real-time knowledge that does not exist in the parameters of LLMs. As a natural trend of development, the tools for calling are becoming autonomous agents, thus the full intelligent system turns out to be a multi-LLM-agent system (MLAS). This paper discusses the technical and business landscapes of MLAS. Compared to the previous single-LLM-agent system, a MLAS has the advantages of i) higher potential of task-solving performance, ii) higher flexibility for system changing, iii) proprietary data preserving for each participating entity, and iv) feasibility of monetization for each entity. To support the ecosystem of MLAS, we provide a preliminary version of such MLAS protocol considering technical requirements, data privacy, and business incentives. As such, MLAS would be a practical solution to achieve artificial collective intelligence in the near future.
P3: A Policy-Driven, Pace-Adaptive, and Diversity-Promoted Framework for Optimizing LLM Training
Aug 10, 2024



In the rapidly evolving field of Large Language Models (LLMs), selecting high-quality data for fine-tuning is essential. This paper focuses on task-specific data pruning and selection to enhance fine-tuning. We introduce an innovative framework, termed P3, which improves LLM performance through a dynamic, adaptive training strategy. Specifically, P3 comprises the following components: (1) Policy-driven Difficulty Measurement: we begin by measuring the difficulty of data based on the model's real-time performance, transitioning from static, predefined metrics to more dynamic and adaptable ones. (2) Pace-adaptive Selection: we employ self-paced learning (SPL) to gradually select increasingly challenging data, thereby progressively enhancing the model's performance. (3) Diversity Promotion: we integrate Determinantal Point Process (DPP) into the selection process to promote the diversity within and between samples, enriching the learning process. We have validated our method on two well-known LLM datasets, APPS and MATH, designed for logical reasoning scenarios. The results show that our P3 framework significantly improves training outcomes compared to traditional methods. By fundamentally refining data selection and utilization strategies, P3 not only advances theoretical understanding of dynamic training approaches but also provides a versatile framework that can revolutionize model training in natural language processing.
TRAD: Enhancing LLM Agents with Step-Wise Thought Retrieval and Aligned Decision
Mar 10, 2024



Numerous large language model (LLM) agents have been built for different tasks like web navigation and online shopping due to LLM's wide knowledge and text-understanding ability. Among these works, many of them utilize in-context examples to achieve generalization without the need for fine-tuning, while few of them have considered the problem of how to select and effectively utilize these examples. Recently, methods based on trajectory-level retrieval with task meta-data and using trajectories as in-context examples have been proposed to improve the agent's overall performance in some sequential decision making tasks. However, these methods can be problematic due to plausible examples retrieved without task-specific state transition dynamics and long input with plenty of irrelevant context. In this paper, we propose a novel framework (TRAD) to address these issues. TRAD first conducts Thought Retrieval, achieving step-level demonstration selection via thought matching, leading to more helpful demonstrations and less irrelevant input noise. Then, TRAD introduces Aligned Decision, complementing retrieved demonstration steps with their previous or subsequent steps, which enables tolerance for imperfect thought and provides a choice for balance between more context and less noise. Extensive experiments on ALFWorld and Mind2Web benchmarks show that TRAD not only outperforms state-of-the-art models but also effectively helps in reducing noise and promoting generalization. Furthermore, TRAD has been deployed in real-world scenarios of a global business insurance company and improves the success rate of robotic process automation.
Alioth: A Machine Learning Based Interference-Aware Performance Monitor for Multi-Tenancy Applications in Public Cloud
Jul 18, 2023Multi-tenancy in public clouds may lead to co-location interference on shared resources, which possibly results in performance degradation of cloud applications. Cloud providers want to know when such events happen and how serious the degradation is, to perform interference-aware migrations and alleviate the problem. However, virtual machines (VM) in Infrastructure-as-a-Service public clouds are black-boxes to providers, where application-level performance information cannot be acquired. This makes performance monitoring intensely challenging as cloud providers can only rely on low-level metrics such as CPU usage and hardware counters. We propose a novel machine learning framework, Alioth, to monitor the performance degradation of cloud applications. To feed the data-hungry models, we first elaborate interference generators and conduct comprehensive co-location experiments on a testbed to build Alioth-dataset which reflects the complexity and dynamicity in real-world scenarios. Then we construct Alioth by (1) augmenting features via recovering low-level metrics under no interference using denoising auto-encoders, (2) devising a transfer learning model based on domain adaptation neural network to make models generalize on test cases unseen in offline training, and (3) developing a SHAP explainer to automate feature selection and enhance model interpretability. Experiments show that Alioth achieves an average mean absolute error of 5.29% offline and 10.8% when testing on applications unseen in the training stage, outperforming the baseline methods. Alioth is also robust in signaling quality-of-service violation under dynamicity. Finally, we demonstrate a possible application of Alioth's interpretability, providing insights to benefit the decision-making of cloud operators. The dataset and code of Alioth have been released on GitHub.