 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiming at the Target: Filter Collaborative Information for Cross-Domain Recommendation
Mar 29, 2024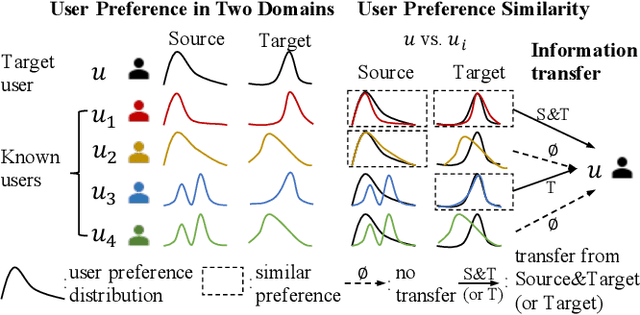
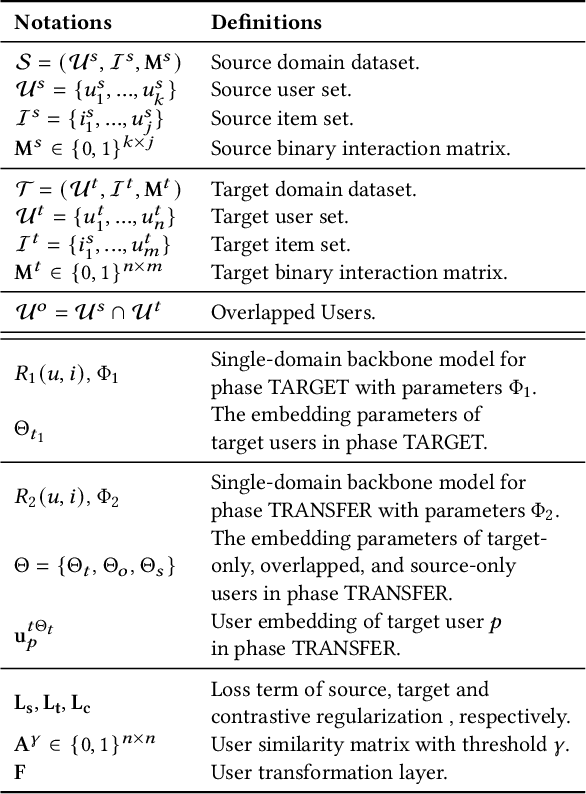
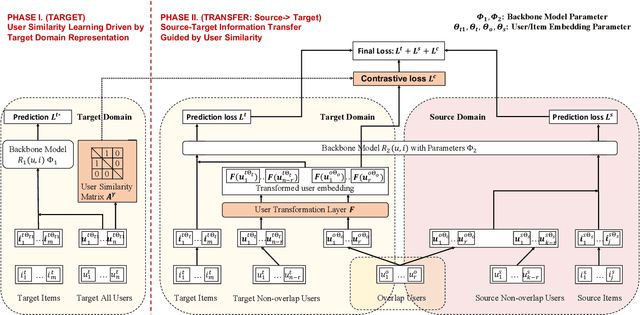
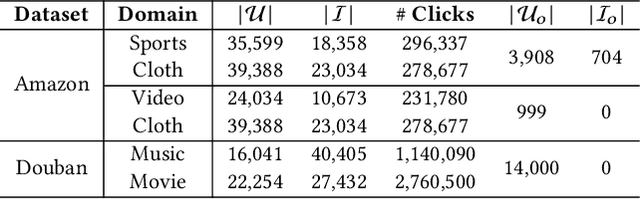
Cross-domain recommender (CDR) systems aim to enhance the performance of the target domain by utilizing data from other related domains. However, irrelevant information from the source domain may instead degrade target domain performance, which is known as the negative transfer problem. There have been some attempts to address this problem, mostly by designing adaptive representations for overlapped users. Whereas, representation adaptions solely rely on the expressive capacity of the CDR model, lacking explicit constraint to filter the irrelevant source-domain collaborative information for the target domain. In this paper, we propose a novel Collaborative information regularized User Transformation (CUT) framework to tackle the negative transfer problem by directly filtering users' collaborative information. In CUT, user similarity in the target domain is adopted as a constraint for user transformation learning to filter the user collaborative information from the source domain. CUT first learns user similarity relationships from the target domain. Then, source-target information transfer is guided by the user similarity, where we design a user transformation layer to learn target-domain user representations and a contrastive loss to supervise the user collaborative information transferred. The results show significant performance improvement of CUT compared with SOTA single and cross-domain methods. Further analysis of the target-domain results illustrates that CUT can effectively alleviate the negative transfer problem.
TRAD: Enhancing LLM Agents with Step-Wise Thought Retrieval and Aligned Decision
Mar 10, 2024



Numerous large language model (LLM) agents have been built for different tasks like web navigation and online shopping due to LLM's wide knowledge and text-understanding ability. Among these works, many of them utilize in-context examples to achieve generalization without the need for fine-tuning, while few of them have considered the problem of how to select and effectively utilize these examples. Recently, methods based on trajectory-level retrieval with task meta-data and using trajectories as in-context examples have been proposed to improve the agent's overall performance in some sequential decision making tasks. However, these methods can be problematic due to plausible examples retrieved without task-specific state transition dynamics and long input with plenty of irrelevant context. In this paper, we propose a novel framework (TRAD) to address these issues. TRAD first conducts Thought Retrieval, achieving step-level demonstration selection via thought matching, leading to more helpful demonstrations and less irrelevant input noise. Then, TRAD introduces Aligned Decision, complementing retrieved demonstration steps with their previous or subsequent steps, which enables tolerance for imperfect thought and provides a choice for balance between more context and less noise. Extensive experiments on ALFWorld and Mind2Web benchmarks show that TRAD not only outperforms state-of-the-art models but also effectively helps in reducing noise and promoting generalization. Furthermore, TRAD has been deployed in real-world scenarios of a global business insurance company and improves the success rate of robotic process automation.
Fine-grainedly Synthesize Streaming Data Based On Large Language Models With Graph Structure Understanding For Data Sparsity
Mar 10, 2024



Due to the sparsity of user data, sentiment analysis on user reviews in e-commerce platforms often suffers from poor performance, especially when faced with extremely sparse user data or long-tail labels. Recently, the emergence of LLMs has introduced new solutions to such problems by leveraging graph structures to generate supplementary user profiles. However, previous approaches have not fully utilized the graph understanding capabilities of LLMs and have struggled to adapt to complex streaming data environments. In this work, we propose a fine-grained streaming data synthesis framework that categorizes sparse users into three categories: Mid-tail, Long-tail, and Extreme. Specifically, we design LLMs to comprehensively understand three key graph elements in streaming data, including Local-global Graph Understanding, Second-Order Relationship Extraction, and Product Attribute Understanding, which enables the generation of high-quality synthetic data to effectively address sparsity across different categories. Experimental results on three real datasets demonstrate significant performance improvements, with synthesized data contributing to MSE reductions of 45.85%, 3.16%, and 62.21%, respectively.
Causal Prompting: Debiasing Large Language Model Prompting based on Front-Door Adjustment
Mar 05, 2024



Despite the significant achievements of existing prompting methods such as in-context learning and chain-of-thought for large language models (LLMs), they still face challenges of various biases. Traditional debiasing methods primarily focus on the model training stage, including data augmentation-based and reweight-based approaches, with the limitations of addressing the complex biases of LLMs. To address such limitations, the causal relationship behind the prompting methods is uncovered using a structural causal model, and a novel causal prompting method based on front-door adjustment is proposed to effectively mitigate the bias of LLMs. In specific, causal intervention is implemented by designing the prompts without accessing the parameters and logits of LLMs.The chain-of-thoughts generated by LLMs are employed as the mediator variable and the causal effect between the input prompt and the output answers is calculated through front-door adjustment to mitigate model biases. Moreover, to obtain the representation of the samples precisely and estimate the causal effect more accurately, contrastive learning is used to fine-tune the encoder of the samples by aligning the space of the encoder with the LLM. Experimental results show that the proposed causal prompting approach achieves excellent performance on 3 natural language processing datasets on both open-source and closed-source LLMs.
STAR: Constraint LoRA with Dynamic Active Learning for Data-Efficient Fine-Tuning of Large Language Models
Mar 02, 2024



Though Large Language Models (LLMs) have demonstrated the powerful capabilities of few-shot learning through prompting methods, supervised training is still necessary for complex reasoning tasks. Because of their extensive parameters and memory consumption, both Parameter-Efficient Fine-Tuning (PEFT) methods and Memory-Efficient Fine-Tuning methods have been proposed for LLMs. Nevertheless, the issue of large annotated data consumption, the aim of Data-Efficient Fine-Tuning, remains unexplored. One obvious way is to combine the PEFT method with active learning. However, the experimental results show that such a combination is not trivial and yields inferior results. Through probe experiments, such observation might be explained by two main reasons: uncertainty gap and poor model calibration. Therefore, in this paper, we propose a novel approach to effectively integrate uncertainty-based active learning and LoRA. Specifically, for the uncertainty gap, we introduce a dynamic uncertainty measurement that combines the uncertainty of the base model and the uncertainty of the full model during the iteration of active learning. For poor model calibration, we incorporate the regularization method during LoRA training to keep the model from being over-confident, and the Monte-Carlo dropout mechanism is employed to enhance the uncertainty estimation. Experimental results show that the proposed approach outperforms existing baseline models on three complex reasoning tasks.
DINER: Debiasing Aspect-based Sentiment Analysis with Multi-variable Causal Inference
Mar 02, 2024



Though notable progress has been made, neural-based aspect-based sentiment analysis (ABSA) models are prone to learn spurious correlations from annotation biases, resulting in poor robustness on adversarial data transformations. Among the debiasing solutions, causal inference-based methods have attracted much research attention, which can be mainly categorized into causal intervention methods and counterfactual reasoning methods. However, most of the present debiasing methods focus on single-variable causal inference, which is not suitable for ABSA with two input variables (the target aspect and the review). In this paper, we propose a novel framework based on multi-variable causal inference for debiasing ABSA. In this framework, different types of biases are tackled based on different causal intervention methods. For the review branch, the bias is modeled as indirect confounding from context, where backdoor adjustment intervention is employed for debiasing. For the aspect branch, the bias is described as a direct correlation with labels, where counterfactual reasoning is adopted for debiasing. Extensive experiments demonstrate the effectiveness of the proposed method compared to various baselines on the two widely used real-world aspect robustness test set datasets.
Modeling User Repeat Consumption Behavior for Online Novel Recommendation
Sep 05, 2022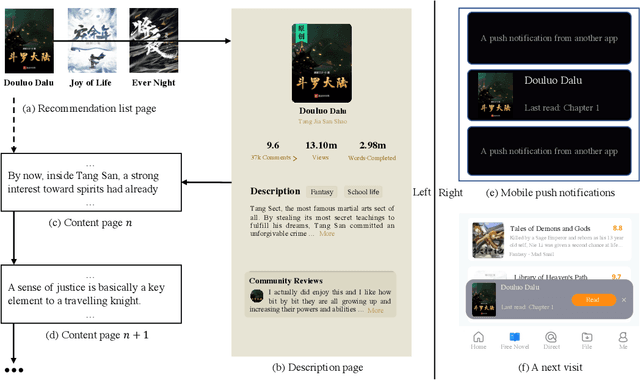

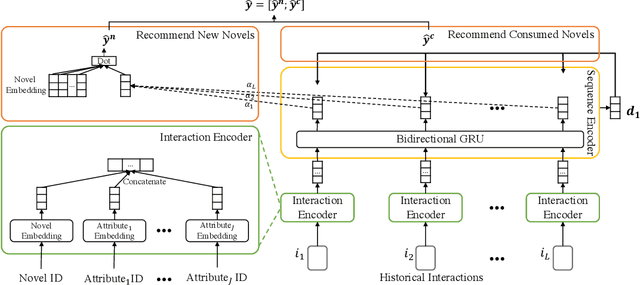
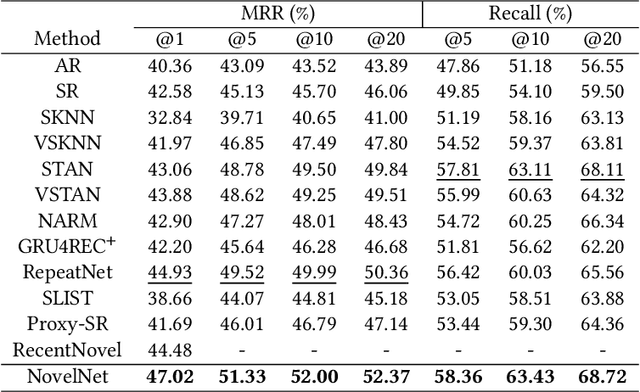
Given a user's historical interaction sequence, online novel recommendation suggests the next novel the user may be interested in. Online novel recommendation is important but underexplored. In this paper, we concentrate on recommending online novels to new users of an online novel reading platform, whose first visits to the platform occurred in the last seven days. We have two observations about online novel recommendation for new users. First, repeat novel consumption of new users is a common phenomenon. Second, interactions between users and novels are informative. To accurately predict whether a user will reconsume a novel, it is crucial to characterize each interaction at a fine-grained level. Based on these two observations, we propose a neural network for online novel recommendation, called NovelNet. NovelNet can recommend the next novel from both the user's consumed novels and new novels simultaneously. Specifically, an interaction encoder is used to obtain accurate interaction representation considering fine-grained attributes of interaction, and a pointer network with a pointwise loss is incorporated into NovelNet to recommend previously-consumed novels. Moreover, an online novel recommendation dataset is built from a well-known online novel reading platform and is released for public use as a benchmark. Experimental results on the dataset demonstrate the effectiveness of NovelNet.
A Multi-modal and Multi-task Learning Method for Action Unit and Expression Recognition
Jul 15, 2021



Analyzing human affect is vital for human-computer interaction systems. Most methods are developed in restricted scenarios which are not practical for in-the-wild settings. The Affective Behavior Analysis in-the-wild (ABAW) 2021 Contest provides a benchmark for this in-the-wild problem. In this paper, we introduce a multi-modal and multi-task learning method by using both visual and audio information. We use both AU and expression annotations to train the model and apply a sequence model to further extract associations between video frames. We achieve an AU score of 0.712 and an expression score of 0.477 on the validation set. These results demonstrate the effectiveness of our approach in improving model performance.
Curriculum-Meta Learning for Order-Robust Continual Relation Extraction
Jan 08, 2021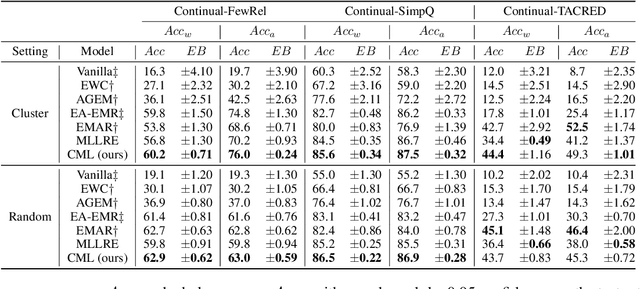
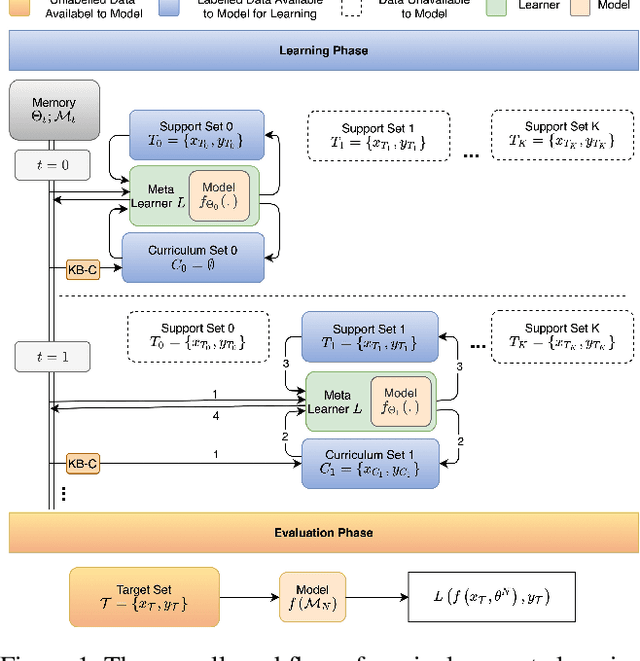
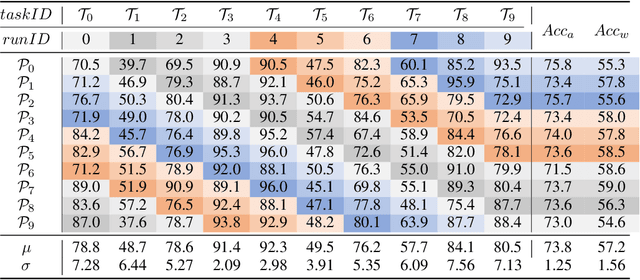
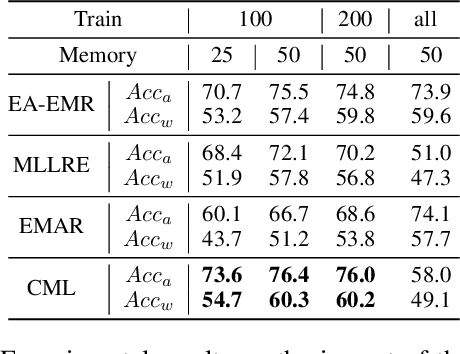
Continual relation extraction is an important task that focuses on extracting new facts incrementally from unstructured text. Given the sequential arrival order of the relations, this task is prone to two serious challenges, namely catastrophic forgetting and order-sensitivity. We propose a novel curriculum-meta learning method to tackle the above two challenges in continual relation extraction. We combine meta learning and curriculum learning to quickly adapt model parameters to a new task and to reduce interference of previously seen tasks on the current task. We design a novel relation representation learning method through the distribution of domain and range types of relations. Such representations are utilized to quantify the difficulty of tasks for the construction of curricula. Moreover, we also present novel difficulty-based metrics to quantitatively measure the extent of order-sensitivity of a given model, suggesting new ways to evaluate model robustness. Our comprehensive experiments on three benchmark datasets show that our proposed method outperforms the state-of-the-art techniques. The code is available at the anonymous GitHub repository: https://github.com/wutong8023/AAAI_CML.
Learning to Augment Expressions for Few-shot Fine-grained Facial Expression Recognition
Jan 17, 2020

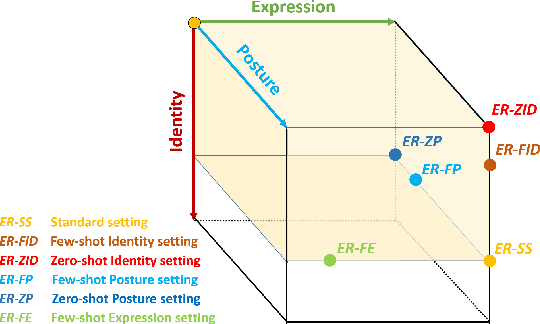
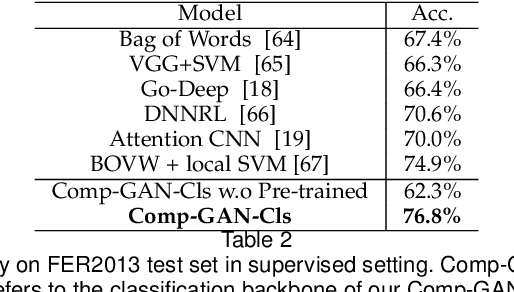
Affective computing and cognitive theory are widely used in modern human-computer interaction scenarios. Human faces, as the most prominent and easily accessible features, have attracted great attention from researchers. Since humans have rich emotions and developed musculature, there exist a lot of fine-grained expressions in real-world applications. However, it is extremely time-consuming to collect and annotate a large number of facial images, of which may even require psychologists to correctly categorize them. To the best of our knowledge, the existing expression datasets are only limited to several basic facial expressions, which are not sufficient to support our ambitions in developing successful human-computer interaction systems. To this end, a novel Fine-grained Facial Expression Database - F2ED is contributed in this paper, and it includes more than 200k images with 54 facial expressions from 119 persons. Considering the phenomenon of uneven data distribution and lack of samples is common in real-world scenarios, we further evaluate several tasks of few-shot expression learning by virtue of our F2ED, which are to recognize the facial expressions given only few training instances. These tasks mimic human performance to learn robust and general representation from few examples. To address such few-shot tasks, we propose a unified task-driven framework - Compositional Generative Adversarial Network (Comp-GAN) learning to synthesize facial images and thus augmenting the instances of few-shot expression classes. Extensive experiments are conducted on F2ED and existing facial expression datasets, i.e., JAFFE and FER2013, to validate the efficacy of our F2ED in pre-training facial expression recognition network and the effectiveness of our proposed approach Comp-GAN to improve the performance of few-shot recognition tasks.