 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment-Aware Code Generation: How far are We?
Jan 18, 2026Recent progress in large language models (LLMs) has improved code generation, but most evaluations still test isolated, small-scale code (e.g., a single function) under default or unspecified software environments. As a result, it is unclear whether LLMs can reliably generate executable code tailored to a user's specific environment. We present the first systematic study of Environment-Aware Code Generation (EACG), where generated code must be functionally correct and directly executable under arbitrary software configurations. To enable realistic evaluation, we introduce VersiBCB, a benchmark that is multi-package, execution-verified, and deprecation-aware, capturing complex and evolving environments that prior datasets often overlook. Using VersiBCB, we investigate three complementary adaptation axes: data, parameters, and cache, and develop representative strategies for each. Our results show that current LLMs struggle with environment-specific code generation, while our adaptations improve environment compatibility and executability. These findings highlight key challenges and opportunities for deploying LLMs in practical software engineering workflows.
C$^3$TG: Conflict-aware, Composite, and Collaborative Controlled Text Generation
Nov 16, 2025Recent advancements in large language models (LLMs) have demonstrated remarkable text generation capabilities. However, controlling specific attributes of generated text remains challenging without architectural modifications or extensive fine-tuning. Current methods typically toggle a single, basic attribute but struggle with precise multi-attribute control. In scenarios where attribute requirements conflict, existing methods lack coordination mechanisms, causing interference between desired attributes. Furthermore, these methods fail to incorporate iterative optimization processes in the controlled generation pipeline. To address these limitations, we propose Conflict-aware, Composite, and Collaborative Controlled Text Generation (C$^3$TG), a two-phase framework for fine-grained, multi-dimensional text attribute control. During generation, C$^3$TG selectively pairs the LLM with the required attribute classifiers from the 17 available dimensions and employs weighted KL-divergence to adjust token probabilities. The optimization phase then leverages an energy function combining classifier scores and penalty terms to resolve attribute conflicts through iterative feedback, enabling precise control over multiple dimensions simultaneously while preserving natural text flow. Experiments show that C$^3$TG significantly outperforms baselines across multiple metrics including attribute accuracy, linguistic fluency, and output diversity, while simultaneously reducing toxicity. These results establish C$^3$TG as an effective and flexible solution for multi-dimensional text attribute control that requires no costly model modifications.
Pandora: Leveraging Code-driven Knowledge Transfer for Unified Structured Knowledge Reasoning
Aug 25, 2025Unified Structured Knowledge Reasoning (USKR) aims to answer natural language questions by using structured sources such as tables, databases, and knowledge graphs in a unified way. Existing USKR methods rely on task-specific strategies or bespoke representations, which hinder their ability to dismantle barriers between different SKR tasks, thereby constraining their overall performance in cross-task scenarios. In this paper, we introduce \textsc{Pandora}, a novel USKR framework that addresses the limitations of existing methods by leveraging two key innovations. First, we propose a code-based unified knowledge representation using \textsc{Python}'s \textsc{Pandas} API, which aligns seamlessly with the pre-training of LLMs. This representation facilitates a cohesive approach to handling different structured knowledge sources. Building on this foundation, we employ knowledge transfer to bolster the unified reasoning process of LLMs by automatically building cross-task memory. By adaptively correcting reasoning using feedback from code execution, \textsc{Pandora} showcases impressive unified reasoning capabilities. Extensive experiments on six widely used benchmarks across three SKR tasks demonstrate that \textsc{Pandora} outperforms existing unified reasoning frameworks and competes effectively with task-specific methods.
OneEval: Benchmarking LLM Knowledge-intensive Reasoning over Diverse Knowledge Bases
Jun 14, 2025



Large Language Models (LLMs) have demonstrated substantial progress on reasoning tasks involving unstructured text, yet their capabilities significantly deteriorate when reasoning requires integrating structured external knowledge such as knowledge graphs, code snippets, or formal logic. This limitation is partly due to the absence of benchmarks capable of systematically evaluating LLM performance across diverse structured knowledge modalities. To address this gap, we introduce \textbf{\textsc{OneEval}}, a comprehensive benchmark explicitly designed to assess the knowledge-intensive reasoning capabilities of LLMs across four structured knowledge modalities, unstructured text, knowledge graphs, code, and formal logic, and five critical domains (general knowledge, government, science, law, and programming). \textsc{OneEval} comprises 4,019 carefully curated instances and includes a challenging subset, \textsc{OneEval}\textsubscript{Hard}, consisting of 1,285 particularly difficult cases. Through extensive evaluation of 18 state-of-the-art open-source and proprietary LLMs, we establish three core findings: a) \emph{persistent limitations in structured reasoning}, with even the strongest model achieving only 32.2\% accuracy on \textsc{OneEval}\textsubscript{Hard}; b) \emph{performance consistently declines as the structural complexity of the knowledge base increases}, with accuracy dropping sharply from 53\% (textual reasoning) to 25\% (formal logic); and c) \emph{diminishing returns from extended reasoning chains}, highlighting the critical need for models to adapt reasoning depth appropriately to task complexity. We release the \textsc{OneEval} datasets, evaluation scripts, and baseline results publicly, accompanied by a leaderboard to facilitate ongoing advancements in structured knowledge reasoning.
Dual-Priv Pruning : Efficient Differential Private Fine-Tuning in Multimodal Large Language Models
Jun 08, 2025Differential Privacy (DP) is a widely adopted technique, valued for its effectiveness in protecting the privacy of task-specific datasets, making it a critical tool for large language models. However, its effectiveness in Multimodal Large Language Models (MLLMs) remains uncertain. Applying Differential Privacy (DP) inherently introduces substantial computation overhead, a concern particularly relevant for MLLMs which process extensive textual and visual data. Furthermore, a critical challenge of DP is that the injected noise, necessary for privacy, scales with parameter dimensionality, leading to pronounced model degradation; This trade-off between privacy and utility complicates the application of Differential Privacy (DP) to complex architectures like MLLMs. To address these, we propose Dual-Priv Pruning, a framework that employs two complementary pruning mechanisms for DP fine-tuning in MLLMs: (i) visual token pruning to reduce input dimensionality by removing redundant visual information, and (ii) gradient-update pruning during the DP optimization process. This second mechanism selectively prunes parameter updates based on the magnitude of noisy gradients, aiming to mitigate noise impact and improve utility. Experiments demonstrate that our approach achieves competitive results with minimal performance degradation. In terms of computational efficiency, our approach consistently utilizes less memory than standard DP-SGD. While requiring only 1.74% more memory than zeroth-order methods which suffer from severe performance issues on A100 GPUs, our method demonstrates leading memory efficiency on H20 GPUs. To the best of our knowledge, we are the first to explore DP fine-tuning in MLLMs. Our code is coming soon.
Table-r1: Self-supervised and Reinforcement Learning for Program-based Table Reasoning in Small Language Models
Jun 06, 2025Table reasoning (TR) requires structured reasoning over semi-structured tabular data and remains challenging, particularly for small language models (SLMs, e.g., LLaMA-8B) due to their limited capacity compared to large LMs (LLMs, e.g., GPT-4o). To narrow this gap, we explore program-based TR (P-TR), which circumvents key limitations of text-based TR (T-TR), notably in numerical reasoning, by generating executable programs. However, applying P-TR to SLMs introduces two challenges: (i) vulnerability to heterogeneity in table layouts, and (ii) inconsistency in reasoning due to limited code generation capability. We propose Table-r1, a two-stage P-TR method designed for SLMs. Stage 1 introduces an innovative self-supervised learning task, Layout Transformation Inference, to improve tabular layout generalization from a programmatic view. Stage 2 adopts a mix-paradigm variant of Group Relative Policy Optimization, enhancing P-TR consistency while allowing dynamic fallback to T-TR when needed. Experiments on four TR benchmarks demonstrate that Table-r1 outperforms all SLM-based methods, achieving at least a 15% accuracy improvement over the base model (LLaMA-8B) across all datasets and reaching performance competitive with LLMs.
Magic Mushroom: A Customizable Benchmark for Fine-grained Analysis of Retrieval Noise Erosion in RAG Systems
Jun 05, 2025Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by incorporating external retrieved information, mitigating issues such as hallucination and outdated knowledge. However, RAG systems are highly sensitive to retrieval noise prevalent in real-world scenarios. Existing benchmarks fail to emulate the complex and heterogeneous noise distributions encountered in real-world retrieval environments, undermining reliable robustness assessment. In this paper, we define four categories of retrieval noise based on linguistic properties and noise characteristics, aiming to reflect the heterogeneity of noise in real-world scenarios. Building on this, we introduce Magic Mushroom, a benchmark for replicating "magic mushroom" noise: contexts that appear relevant on the surface but covertly mislead RAG systems. Magic Mushroom comprises 7,468 single-hop and 3,925 multi-hop question-answer pairs. More importantly, Magic Mushroom enables researchers to flexibly configure combinations of retrieval noise according to specific research objectives or application scenarios, allowing for highly controlled evaluation setups. We evaluate LLM generators of varying parameter scales and classic RAG denoising strategies under diverse noise distributions to investigate their performance dynamics during progressive noise encroachment. Our analysis reveals that both generators and denoising strategies have significant room for improvement and exhibit extreme sensitivity to noise distributions. Magic Mushroom emerges as a promising tool for evaluating and advancing noise-robust RAG systems, accelerating their widespread deployment in real-world applications. The Magic Mushroom benchmark is available at https://drive.google.com/file/d/1aP5kyPuk4L-L_uoI6T9UhxuTyt8oMqjT/view?usp=sharing.
After Retrieval, Before Generation: Enhancing the Trustworthiness of Large Language Models in RAG
May 21, 2025



Retrieval-augmented generation (RAG) systems face critical challenges in balancing internal (parametric) and external (retrieved) knowledge, especially when these sources conflict or are unreliable. To analyze these scenarios comprehensively, we construct the Trustworthiness Response Dataset (TRD) with 36,266 questions spanning four RAG settings. We reveal that existing approaches address isolated scenarios-prioritizing one knowledge source, naively merging both, or refusing answers-but lack a unified framework to handle different real-world conditions simultaneously. Therefore, we propose the BRIDGE framework, which dynamically determines a comprehensive response strategy of large language models (LLMs). BRIDGE leverages an adaptive weighting mechanism named soft bias to guide knowledge collection, followed by a Maximum Soft-bias Decision Tree to evaluate knowledge and select optimal response strategies (trust internal/external knowledge, or refuse). Experiments show BRIDGE outperforms baselines by 5-15% in accuracy while maintaining balanced performance across all scenarios. Our work provides an effective solution for LLMs' trustworthy responses in real-world RAG applications.
Pandora: A Code-Driven Large Language Model Agent for Unified Reasoning Across Diverse Structured Knowledge
Apr 17, 2025



Unified Structured Knowledge Reasoning (USKR) aims to answer natural language questions (NLQs) by using structured sources such as tables, databases, and knowledge graphs in a unified way. Existing USKR methods either rely on employing task-specific strategies or custom-defined representations, which struggle to leverage the knowledge transfer between different SKR tasks or align with the prior of LLMs, thereby limiting their performance. This paper proposes a novel USKR framework named \textsc{Pandora}, which takes advantage of \textsc{Python}'s \textsc{Pandas} API to construct a unified knowledge representation for alignment with LLM pre-training. It employs an LLM to generate textual reasoning steps and executable Python code for each question. Demonstrations are drawn from a memory of training examples that cover various SKR tasks, facilitating knowledge transfer. Extensive experiments on four benchmarks involving three SKR tasks demonstrate that \textsc{Pandora} outperforms existing unified frameworks and competes effectively with task-specific methods.
From Superficial to Deep: Integrating External Knowledge for Follow-up Question Generation Using Knowledge Graph and LLM
Apr 08, 2025
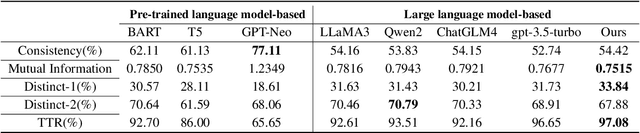
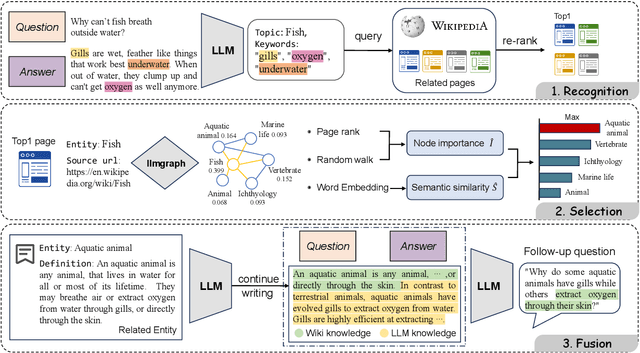

In a conversational system, dynamically generating follow-up questions based on context can help users explore information and provide a better user experience. Humans are usually able to ask questions that involve some general life knowledge and demonstrate higher order cognitive skills. However, the questions generated by existing methods are often limited to shallow contextual questions that are uninspiring and have a large gap to the human level. In this paper, we propose a three-stage external knowledge-enhanced follow-up question generation method, which generates questions by identifying contextual topics, constructing a knowledge graph (KG) online, and finally combining these with a large language model to generate the final question. The model generates information-rich and exploratory follow-up questions by introducing external common sense knowledge and performing a knowledge fusion operation. Experiments show that compared to baseline models, our method generates questions that are more informative and closer to human questioning levels while maintaining contextual relevance.