 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIMO: Progressive Induction for Multi-hop Open Rule Generation
Paper and Code
Nov 02, 2024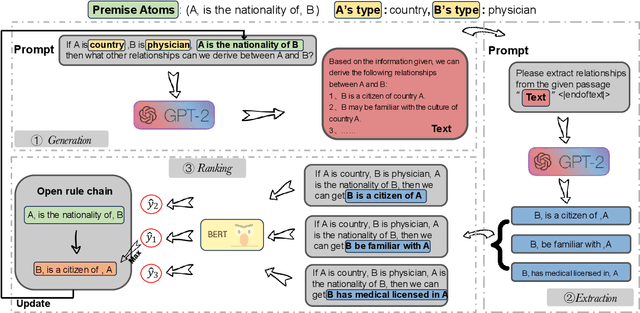
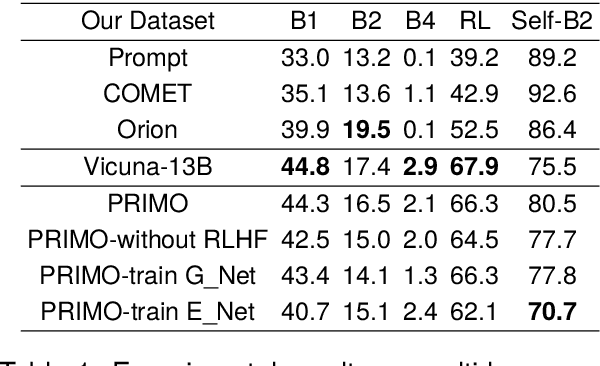

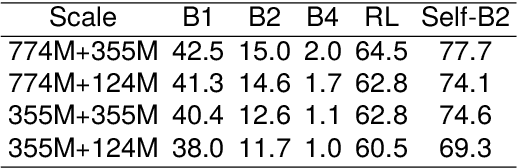
Open rule refer to the implication from premise atoms to hypothesis atoms, which captures various relations between instances in the real world. Injecting open rule knowledge into the machine helps to improve the performance of downstream tasks such as dialogue and relation extraction. Existing approaches focus on single-hop open rule generation, ignoring multi-hop scenarios, leading to logical inconsistencies between premise and hypothesis atoms, as well as semantic duplication of generated rule atoms. To address these issues, we propose a progressive multi-stage open rule generation method called PRIMO. We introduce ontology information during the rule generation stage to reduce ambiguity and improve rule accuracy. PRIMO constructs a multi-stage structure consisting of generation, extraction, and ranking modules to fully leverage the latent knowledge within the language model across multiple dimensions. Furthermore, we employ reinforcement learning from human feedback to further optimize model, enhancing the model's understanding of commonsense knowledge. Experiments show that compared to baseline models, PRIMO significantly improves rule quality and diversity while reducing the repetition rate of rule atoms.