 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPM 1.0: Video-based Character Performance Model
Apr 09, 2026Performance, the externalization of intent, emotion, and personality through visual, vocal, and temporal behavior, is what makes a character alive. Learning such performance from video is a promising alternative to traditional 3D pipelines. However, existing video models struggle to jointly achieve high expressiveness, real-time inference, and long-horizon identity stability, a tension we call the performance trilemma. Conversation is the most comprehensive performance scenario, as characters simultaneously speak, listen, react, and emote while maintaining identity over time. To address this, we present LPM 1.0 (Large Performance Model), focusing on single-person full-duplex audio-visual conversational performance. Concretely, we build a multimodal human-centric dataset through strict filtering, speaking-listening audio-video pairing, performance understanding, and identity-aware multi-reference extraction; train a 17B-parameter Diffusion Transformer (Base LPM) for highly controllable, identity-consistent performance through multimodal conditioning; and distill it into a causal streaming generator (Online LPM) for low-latency, infinite-length interaction. At inference, given a character image with identity-aware references, LPM 1.0 generates listening videos from user audio and speaking videos from synthesized audio, with text prompts for motion control, all at real-time speed with identity-stable, infinite-length generation. LPM 1.0 thus serves as a visual engine for conversational agents, live streaming characters, and game NPCs. To systematically evaluate this setting, we propose LPM-Bench, the first benchmark for interactive character performance. LPM 1.0 achieves state-of-the-art results across all evaluated dimensions while maintaining real-time inference.
AD-CARE: A Guideline-grounded, Modality-agnostic LLM Agent for Real-world Alzheimer's Disease Diagnosis with Multi-cohort Assessment, Fairness Analysis, and Reader Study
Mar 26, 2026Alzheimer's disease (AD) is a growing global health challenge as populations age, and timely, accurate diagnosis is essential to reduce individual and societal burden. However, real-world AD assessment is hampered by incomplete, heterogeneous multimodal data and variability across sites and patient demographics. Although large language models (LLMs) have shown promise in biomedicine, their use in AD has largely been confined to answering narrow, disease-specific questions rather than generating comprehensive diagnostic reports that support clinical decision-making. Here we expand LLM capabilities for clinical decision support by introducing AD-CARE, a modality-agnostic agent that performs guideline-grounded diagnostic assessment from incomplete, heterogeneous inputs without imputing missing modalities. By dynamically orchestrating specialized diagnostic tools and embedding clinical guidelines into LLM-driven reasoning, AD-CARE generates transparent, report-style outputs aligned with real-world clinical workflows. Across six cohorts comprising 10,303 cases, AD-CARE achieved 84.9% diagnostic accuracy, delivering 4.2%-13.7% relative improvements over baseline methods. Despite cohort-level differences, dataset-specific accuracies remain robust (80.4%-98.8%), and the agent consistently outperforms all baselines. AD-CARE reduced performance disparities across racial and age subgroups, decreasing the average dispersion of four metrics by 21%-68% and 28%-51%, respectively. In a controlled reader study, the agent improved neurologist and radiologist accuracy by 6%-11% and more than halved decision time. The framework yielded 2.29%-10.66% absolute gains over eight backbone LLMs and converges their performance. These results show that AD-CARE is a scalable, practically deployable framework that can be integrated into routine clinical workflows for multimodal decision support in AD.
OneEval: Benchmarking LLM Knowledge-intensive Reasoning over Diverse Knowledge Bases
Jun 14, 2025



Large Language Models (LLMs) have demonstrated substantial progress on reasoning tasks involving unstructured text, yet their capabilities significantly deteriorate when reasoning requires integrating structured external knowledge such as knowledge graphs, code snippets, or formal logic. This limitation is partly due to the absence of benchmarks capable of systematically evaluating LLM performance across diverse structured knowledge modalities. To address this gap, we introduce \textbf{\textsc{OneEval}}, a comprehensive benchmark explicitly designed to assess the knowledge-intensive reasoning capabilities of LLMs across four structured knowledge modalities, unstructured text, knowledge graphs, code, and formal logic, and five critical domains (general knowledge, government, science, law, and programming). \textsc{OneEval} comprises 4,019 carefully curated instances and includes a challenging subset, \textsc{OneEval}\textsubscript{Hard}, consisting of 1,285 particularly difficult cases. Through extensive evaluation of 18 state-of-the-art open-source and proprietary LLMs, we establish three core findings: a) \emph{persistent limitations in structured reasoning}, with even the strongest model achieving only 32.2\% accuracy on \textsc{OneEval}\textsubscript{Hard}; b) \emph{performance consistently declines as the structural complexity of the knowledge base increases}, with accuracy dropping sharply from 53\% (textual reasoning) to 25\% (formal logic); and c) \emph{diminishing returns from extended reasoning chains}, highlighting the critical need for models to adapt reasoning depth appropriately to task complexity. We release the \textsc{OneEval} datasets, evaluation scripts, and baseline results publicly, accompanied by a leaderboard to facilitate ongoing advancements in structured knowledge reasoning.
Magic Mushroom: A Customizable Benchmark for Fine-grained Analysis of Retrieval Noise Erosion in RAG Systems
Jun 05, 2025
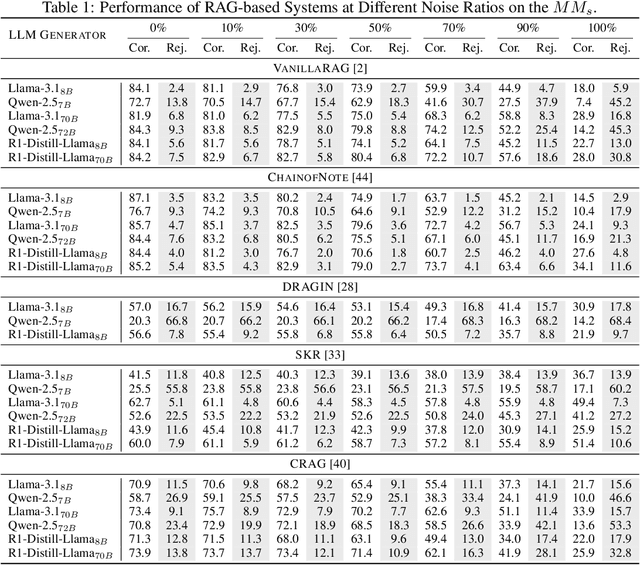


Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by incorporating external retrieved information, mitigating issues such as hallucination and outdated knowledge. However, RAG systems are highly sensitive to retrieval noise prevalent in real-world scenarios. Existing benchmarks fail to emulate the complex and heterogeneous noise distributions encountered in real-world retrieval environments, undermining reliable robustness assessment. In this paper, we define four categories of retrieval noise based on linguistic properties and noise characteristics, aiming to reflect the heterogeneity of noise in real-world scenarios. Building on this, we introduce Magic Mushroom, a benchmark for replicating "magic mushroom" noise: contexts that appear relevant on the surface but covertly mislead RAG systems. Magic Mushroom comprises 7,468 single-hop and 3,925 multi-hop question-answer pairs. More importantly, Magic Mushroom enables researchers to flexibly configure combinations of retrieval noise according to specific research objectives or application scenarios, allowing for highly controlled evaluation setups. We evaluate LLM generators of varying parameter scales and classic RAG denoising strategies under diverse noise distributions to investigate their performance dynamics during progressive noise encroachment. Our analysis reveals that both generators and denoising strategies have significant room for improvement and exhibit extreme sensitivity to noise distributions. Magic Mushroom emerges as a promising tool for evaluating and advancing noise-robust RAG systems, accelerating their widespread deployment in real-world applications. The Magic Mushroom benchmark is available at https://drive.google.com/file/d/1aP5kyPuk4L-L_uoI6T9UhxuTyt8oMqjT/view?usp=sharing.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
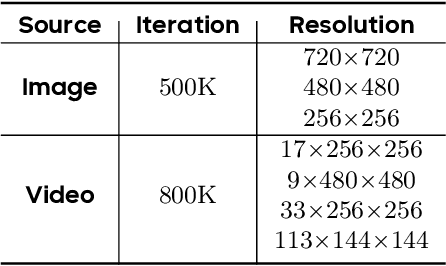
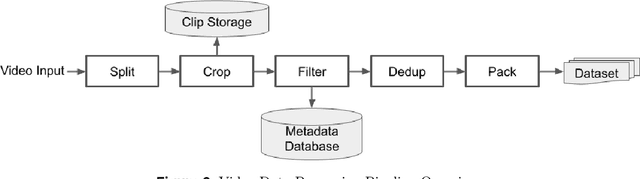

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
From Superficial to Deep: Integrating External Knowledge for Follow-up Question Generation Using Knowledge Graph and LLM
Apr 08, 2025
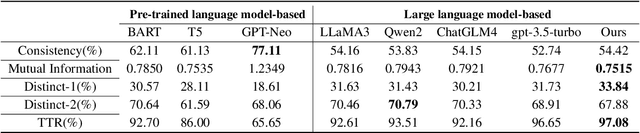
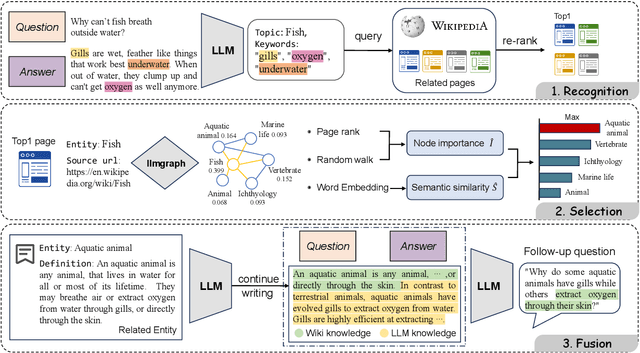

In a conversational system, dynamically generating follow-up questions based on context can help users explore information and provide a better user experience. Humans are usually able to ask questions that involve some general life knowledge and demonstrate higher order cognitive skills. However, the questions generated by existing methods are often limited to shallow contextual questions that are uninspiring and have a large gap to the human level. In this paper, we propose a three-stage external knowledge-enhanced follow-up question generation method, which generates questions by identifying contextual topics, constructing a knowledge graph (KG) online, and finally combining these with a large language model to generate the final question. The model generates information-rich and exploratory follow-up questions by introducing external common sense knowledge and performing a knowledge fusion operation. Experiments show that compared to baseline models, our method generates questions that are more informative and closer to human questioning levels while maintaining contextual relevance.
PRIMO: Progressive Induction for Multi-hop Open Rule Generation
Nov 02, 2024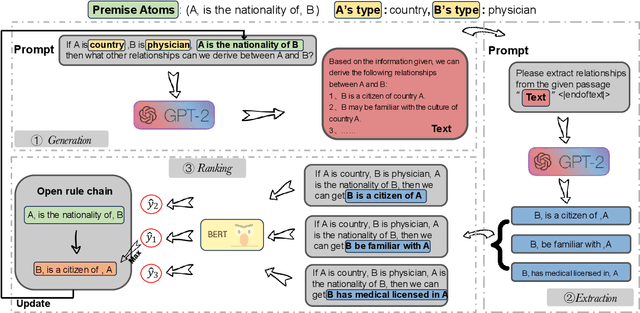
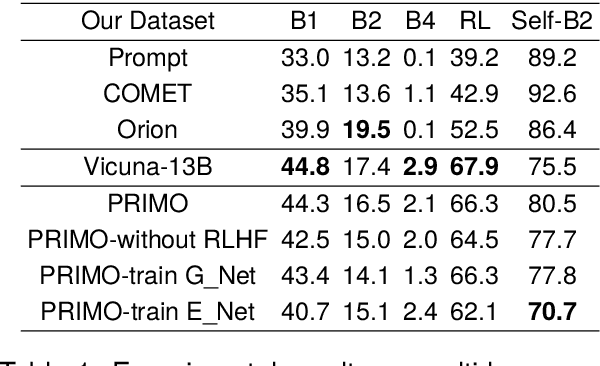

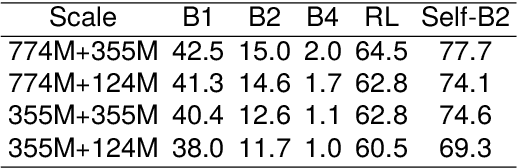
Open rule refer to the implication from premise atoms to hypothesis atoms, which captures various relations between instances in the real world. Injecting open rule knowledge into the machine helps to improve the performance of downstream tasks such as dialogue and relation extraction. Existing approaches focus on single-hop open rule generation, ignoring multi-hop scenarios, leading to logical inconsistencies between premise and hypothesis atoms, as well as semantic duplication of generated rule atoms. To address these issues, we propose a progressive multi-stage open rule generation method called PRIMO. We introduce ontology information during the rule generation stage to reduce ambiguity and improve rule accuracy. PRIMO constructs a multi-stage structure consisting of generation, extraction, and ranking modules to fully leverage the latent knowledge within the language model across multiple dimensions. Furthermore, we employ reinforcement learning from human feedback to further optimize model, enhancing the model's understanding of commonsense knowledge. Experiments show that compared to baseline models, PRIMO significantly improves rule quality and diversity while reducing the repetition rate of rule atoms.
TEII: Think, Explain, Interact and Iterate with Large Language Models to Solve Cross-lingual Emotion Detection
May 27, 2024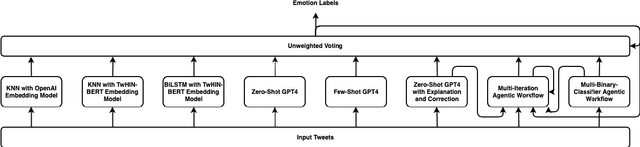
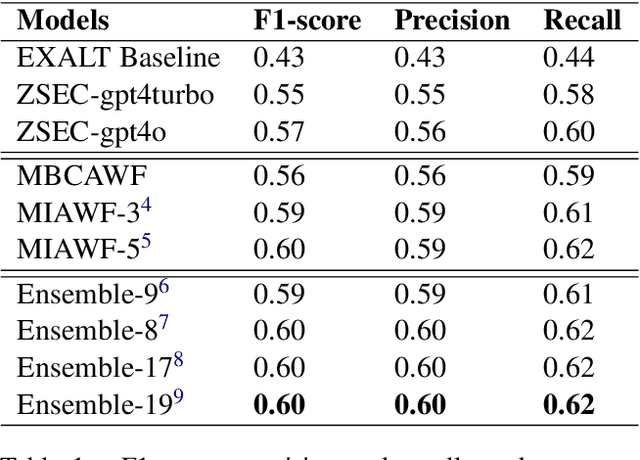
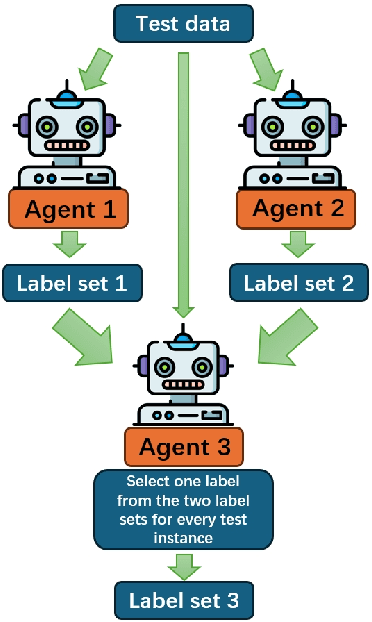
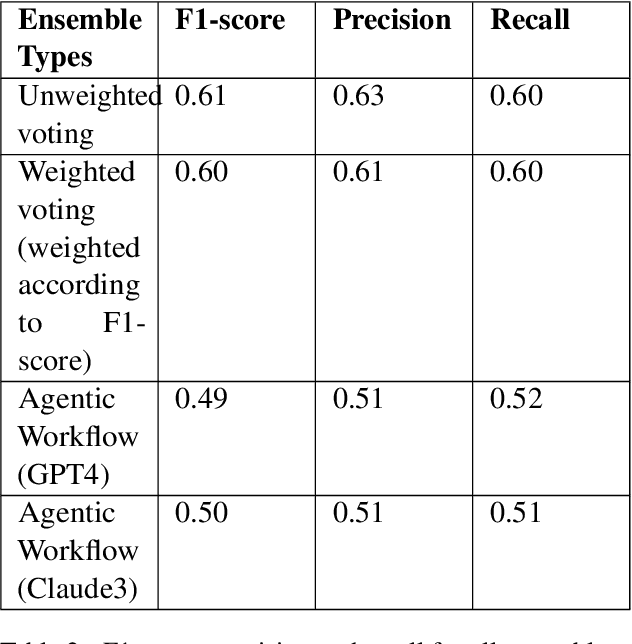
Cross-lingual emotion detection allows us to analyze global trends, public opinion, and social phenomena at scale. We participated in the Explainability of Cross-lingual Emotion Detection (EXALT) shared task, achieving an F1-score of 0.6046 on the evaluation set for the emotion detection sub-task. Our system outperformed the baseline by more than 0.16 F1-score absolute, and ranked second amongst competing systems. We conducted experiments using fine-tuning, zero-shot learning, and few-shot learning for Large Language Model (LLM)-based models as well as embedding-based BiLSTM and KNN for non-LLM-based techniques. Additionally, we introduced two novel methods: the Multi-Iteration Agentic Workflow and the Multi-Binary-Classifier Agentic Workflow. We found that LLM-based approaches provided good performance on multilingual emotion detection. Furthermore, ensembles combining all our experimented models yielded higher F1-scores than any single approach alone.
Single Image Unlearning: Efficient Machine Unlearning in Multimodal Large Language Models
May 21, 2024



Machine unlearning empowers individuals with the `right to be forgotten' by removing their private or sensitive information encoded in machine learning models. However, it remains uncertain whether MU can be effectively applied to Multimodal Large Language Models (MLLMs), particularly in scenarios of forgetting the leaked visual data of concepts. To overcome the challenge, we propose an efficient method, Single Image Unlearning (SIU), to unlearn the visual recognition of a concept by fine-tuning a single associated image for few steps. SIU consists of two key aspects: (i) Constructing Multifaceted fine-tuning data. We introduce four targets, based on which we construct fine-tuning data for the concepts to be forgotten; (ii) Jointly training loss. To synchronously forget the visual recognition of concepts and preserve the utility of MLLMs, we fine-tune MLLMs through a novel Dual Masked KL-divergence Loss combined with Cross Entropy loss. Alongside our method, we establish MMUBench, a new benchmark for MU in MLLMs and introduce a collection of metrics for its evaluation. Experimental results on MMUBench show that SIU completely surpasses the performance of existing methods. Furthermore, we surprisingly find that SIU can avoid invasive membership inference attacks and jailbreak attacks. To the best of our knowledge, we are the first to explore MU in MLLMs. We will release the code and benchmark in the near future.
Benchmarking Large Language Models in Complex Question Answering Attribution using Knowledge Graphs
Jan 26, 2024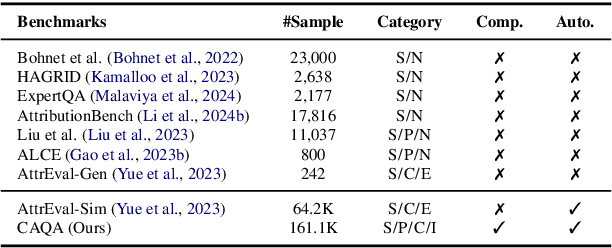
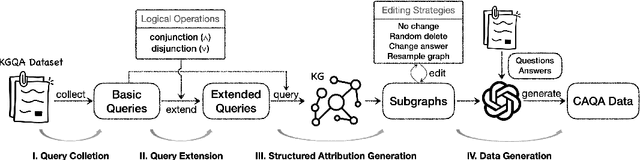

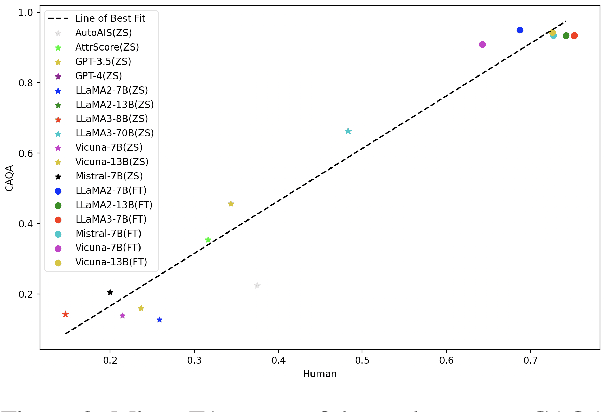
The attribution of question answering is to provide citations for supporting generated statements, and has attracted wide research attention. The current methods for automatically evaluating the attribution, which are often based on Large Language Models (LLMs), are still inadequate, particularly in recognizing subtle differences between attributions, and complex relationships between citations and statements. To compare these attribution evaluation methods and develop new ones, we introduce a set of fine-grained categories (i.e., supportive, insufficient, contradictory and irrelevant) for measuring the attribution, and develop a Complex Attributed Question Answering (CAQA) benchmark by leveraging knowledge graphs (KGs) for automatically generating attributions of different categories to question-answer pairs. Our analysis reveals that existing evaluators perform poorly under fine-grained attribution settings and exhibit weaknesses in complex citation-statement reasoning. Our CAQA benchmark, validated with human annotations, emerges as a promising tool for selecting and developing LLM attribution evaluators.