 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Is All It Takes: Spike-Retiming Attacks on Event-Driven Spiking Neural Networks
Feb 03, 2026Spiking neural networks (SNNs) compute with discrete spikes and exploit temporal structure, yet most adversarial attacks change intensities or event counts instead of timing. We study a timing-only adversary that retimes existing spikes while preserving spike counts and amplitudes in event-driven SNNs, thus remaining rate-preserving. We formalize a capacity-1 spike-retiming threat model with a unified trio of budgets: per-spike jitter $\mathcal{B}_{\infty}$, total delay $\mathcal{B}_{1}$, and tamper count $\mathcal{B}_{0}$. Feasible adversarial examples must satisfy timeline consistency and non-overlap, which makes the search space discrete and constrained. To optimize such retimings at scale, we use projected-in-the-loop (PIL) optimization: shift-probability logits yield a differentiable soft retiming for backpropagation, and a strict projection in the forward pass produces a feasible discrete schedule that satisfies capacity-1, non-overlap, and the chosen budget at every step. The objective maximizes task loss on the projected input and adds a capacity regularizer together with budget-aware penalties, which stabilizes gradients and aligns optimization with evaluation. Across event-driven benchmarks (CIFAR10-DVS, DVS-Gesture, N-MNIST) and diverse SNN architectures, we evaluate under binary and integer event grids and a range of retiming budgets, and also test models trained with timing-aware adversarial training designed to counter timing-only attacks. For example, on DVS-Gesture the attack attains high success (over $90\%$) while touching fewer than $2\%$ of spikes under $\mathcal{B}_{0}$. Taken together, our results show that spike retiming is a practical and stealthy attack surface that current defenses struggle to counter, providing a clear reference for temporal robustness in event-driven SNNs. Code is available at https://github.com/yuyi-sd/Spike-Retiming-Attacks.
Toward Efficient Agents: Memory, Tool learning, and Planning
Jan 20, 2026Recent years have witnessed increasing interest in extending large language models into agentic systems. While the effectiveness of agents has continued to improve, efficiency, which is crucial for real-world deployment, has often been overlooked. This paper therefore investigates efficiency from three core components of agents: memory, tool learning, and planning, considering costs such as latency, tokens, steps, etc. Aimed at conducting comprehensive research addressing the efficiency of the agentic system itself, we review a broad range of recent approaches that differ in implementation yet frequently converge on shared high-level principles including but not limited to bounding context via compression and management, designing reinforcement learning rewards to minimize tool invocation, and employing controlled search mechanisms to enhance efficiency, which we discuss in detail. Accordingly, we characterize efficiency in two complementary ways: comparing effectiveness under a fixed cost budget, and comparing cost at a comparable level of effectiveness. This trade-off can also be viewed through the Pareto frontier between effectiveness and cost. From this perspective, we also examine efficiency oriented benchmarks by summarizing evaluation protocols for these components and consolidating commonly reported efficiency metrics from both benchmark and methodological studies. Moreover, we discuss the key challenges and future directions, with the goal of providing promising insights.
Being-M0.5: A Real-Time Controllable Vision-Language-Motion Model
Aug 11, 2025Human motion generation has emerged as a critical technology with transformative potential for real-world applications. However, existing vision-language-motion models (VLMMs) face significant limitations that hinder their practical deployment. We identify controllability as a main bottleneck, manifesting in five key aspects: inadequate response to diverse human commands, limited pose initialization capabilities, poor performance on long-term sequences, insufficient handling of unseen scenarios, and lack of fine-grained control over individual body parts. To overcome these limitations, we present Being-M0.5, the first real-time, controllable VLMM that achieves state-of-the-art performance across multiple motion generation tasks. Our approach is built upon HuMo100M, the largest and most comprehensive human motion dataset to date, comprising over 5 million self-collected motion sequences, 100 million multi-task instructional instances, and detailed part-level annotations that address a critical gap in existing datasets. We introduce a novel part-aware residual quantization technique for motion tokenization that enables precise, granular control over individual body parts during generation. Extensive experimental validation demonstrates Being-M0.5's superior performance across diverse motion benchmarks, while comprehensive efficiency analysis confirms its real-time capabilities. Our contributions include design insights and detailed computational analysis to guide future development of practical motion generators. We believe that HuMo100M and Being-M0.5 represent significant advances that will accelerate the adoption of motion generation technologies in real-world applications. The project page is available at https://beingbeyond.github.io/Being-M0.5.
Dual-Priv Pruning : Efficient Differential Private Fine-Tuning in Multimodal Large Language Models
Jun 08, 2025Differential Privacy (DP) is a widely adopted technique, valued for its effectiveness in protecting the privacy of task-specific datasets, making it a critical tool for large language models. However, its effectiveness in Multimodal Large Language Models (MLLMs) remains uncertain. Applying Differential Privacy (DP) inherently introduces substantial computation overhead, a concern particularly relevant for MLLMs which process extensive textual and visual data. Furthermore, a critical challenge of DP is that the injected noise, necessary for privacy, scales with parameter dimensionality, leading to pronounced model degradation; This trade-off between privacy and utility complicates the application of Differential Privacy (DP) to complex architectures like MLLMs. To address these, we propose Dual-Priv Pruning, a framework that employs two complementary pruning mechanisms for DP fine-tuning in MLLMs: (i) visual token pruning to reduce input dimensionality by removing redundant visual information, and (ii) gradient-update pruning during the DP optimization process. This second mechanism selectively prunes parameter updates based on the magnitude of noisy gradients, aiming to mitigate noise impact and improve utility. Experiments demonstrate that our approach achieves competitive results with minimal performance degradation. In terms of computational efficiency, our approach consistently utilizes less memory than standard DP-SGD. While requiring only 1.74% more memory than zeroth-order methods which suffer from severe performance issues on A100 GPUs, our method demonstrates leading memory efficiency on H20 GPUs. To the best of our knowledge, we are the first to explore DP fine-tuning in MLLMs. Our code is coming soon.
Quo Vadis, Motion Generation? From Large Language Models to Large Motion Models
Oct 04, 2024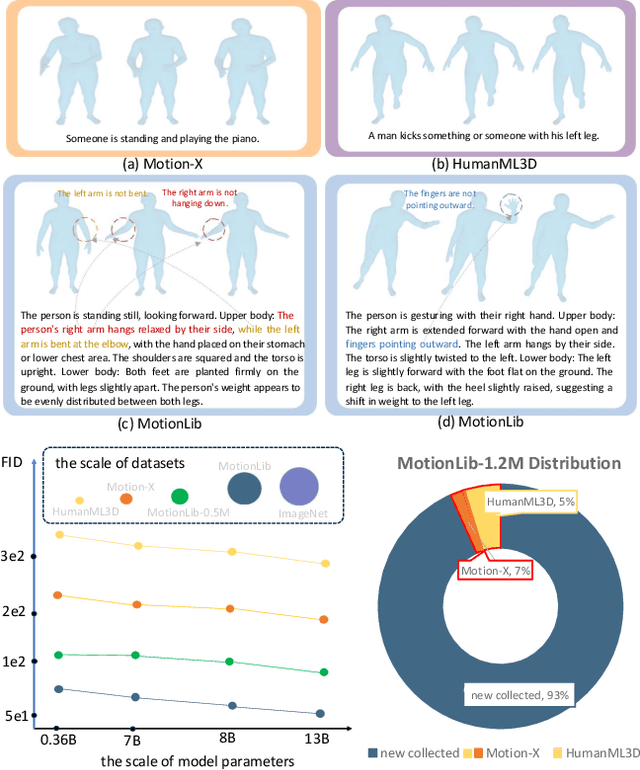


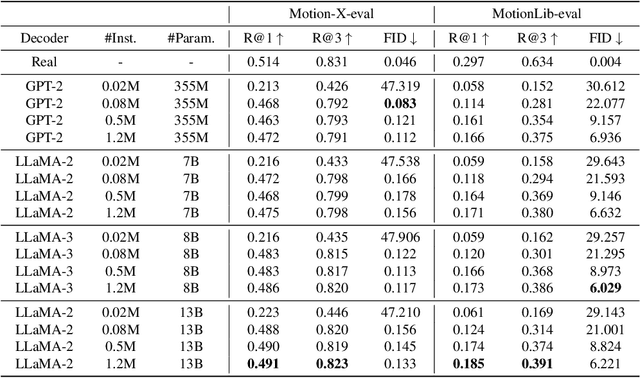
Inspired by the recent success of LLMs, the field of human motion understanding has increasingly shifted towards the development of large motion models. Despite some progress, current state-of-the-art works remain far from achieving truly generalist models, largely due to the lack of large-scale, high-quality motion data. To address this, we present MotionBase, the first million-level motion generation benchmark, offering 15 times the data volume of the previous largest dataset, and featuring multimodal data with hierarchically detailed text descriptions. By leveraging this vast dataset, our large motion model demonstrates strong performance across a broad range of motions, including unseen ones. Through systematic investigation, we underscore the importance of scaling both data and model size, with synthetic data and pseudo labels playing a crucial role in mitigating data acquisition costs. Moreover, our research reveals the limitations of existing evaluation metrics, particularly in handling out-of-domain text instructions -- an issue that has long been overlooked. In addition to these, we introduce a novel 2D lookup-free approach for motion tokenization, which preserves motion information and expands codebook capacity, further enhancing the representative ability of large motion models. The release of MotionBase and the insights gained from this study are expected to pave the way for the development of more powerful and versatile motion generation models.
Single Image Unlearning: Efficient Machine Unlearning in Multimodal Large Language Models
May 21, 2024



Machine unlearning empowers individuals with the `right to be forgotten' by removing their private or sensitive information encoded in machine learning models. However, it remains uncertain whether MU can be effectively applied to Multimodal Large Language Models (MLLMs), particularly in scenarios of forgetting the leaked visual data of concepts. To overcome the challenge, we propose an efficient method, Single Image Unlearning (SIU), to unlearn the visual recognition of a concept by fine-tuning a single associated image for few steps. SIU consists of two key aspects: (i) Constructing Multifaceted fine-tuning data. We introduce four targets, based on which we construct fine-tuning data for the concepts to be forgotten; (ii) Jointly training loss. To synchronously forget the visual recognition of concepts and preserve the utility of MLLMs, we fine-tune MLLMs through a novel Dual Masked KL-divergence Loss combined with Cross Entropy loss. Alongside our method, we establish MMUBench, a new benchmark for MU in MLLMs and introduce a collection of metrics for its evaluation. Experimental results on MMUBench show that SIU completely surpasses the performance of existing methods. Furthermore, we surprisingly find that SIU can avoid invasive membership inference attacks and jailbreak attacks. To the best of our knowledge, we are the first to explore MU in MLLMs. We will release the code and benchmark in the near future.