 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Image Unlearning: Efficient Machine Unlearning in Multimodal Large Language Models
May 21, 2024



Machine unlearning empowers individuals with the `right to be forgotten' by removing their private or sensitive information encoded in machine learning models. However, it remains uncertain whether MU can be effectively applied to Multimodal Large Language Models (MLLMs), particularly in scenarios of forgetting the leaked visual data of concepts. To overcome the challenge, we propose an efficient method, Single Image Unlearning (SIU), to unlearn the visual recognition of a concept by fine-tuning a single associated image for few steps. SIU consists of two key aspects: (i) Constructing Multifaceted fine-tuning data. We introduce four targets, based on which we construct fine-tuning data for the concepts to be forgotten; (ii) Jointly training loss. To synchronously forget the visual recognition of concepts and preserve the utility of MLLMs, we fine-tune MLLMs through a novel Dual Masked KL-divergence Loss combined with Cross Entropy loss. Alongside our method, we establish MMUBench, a new benchmark for MU in MLLMs and introduce a collection of metrics for its evaluation. Experimental results on MMUBench show that SIU completely surpasses the performance of existing methods. Furthermore, we surprisingly find that SIU can avoid invasive membership inference attacks and jailbreak attacks. To the best of our knowledge, we are the first to explore MU in MLLMs. We will release the code and benchmark in the near future.
MIKE: A New Benchmark for Fine-grained Multimodal Entity Knowledge Editing
Feb 18, 2024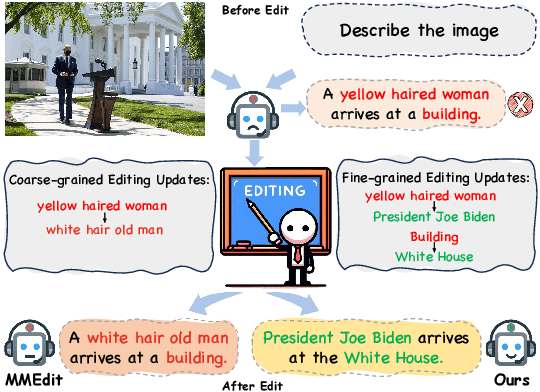
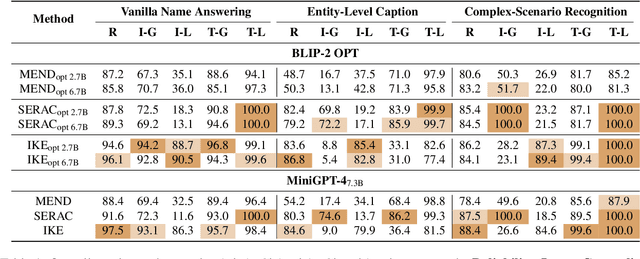

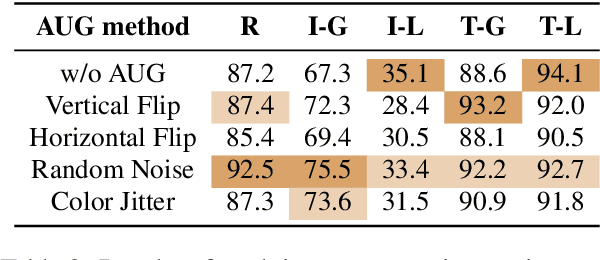
Multimodal knowledge editing represents a critical advancement in enhancing the capabilities of Multimodal Large Language Models (MLLMs). Despite its potential, current benchmarks predominantly focus on coarse-grained knowledge, leaving the intricacies of fine-grained (FG) multimodal entity knowledge largely unexplored. This gap presents a notable challenge, as FG entity recognition is pivotal for the practical deployment and effectiveness of MLLMs in diverse real-world scenarios. To bridge this gap, we introduce MIKE, a comprehensive benchmark and dataset specifically designed for the FG multimodal entity knowledge editing. MIKE encompasses a suite of tasks tailored to assess different perspectives, including Vanilla Name Answering, Entity-Level Caption, and Complex-Scenario Recognition. In addition, a new form of knowledge editing, Multi-step Editing, is introduced to evaluate the editing efficiency. Through our extensive evaluations, we demonstrate that the current state-of-the-art methods face significant challenges in tackling our proposed benchmark, underscoring the complexity of FG knowledge editing in MLLMs. Our findings spotlight the urgent need for novel approaches in this domain, setting a clear agenda for future research and development efforts within the community.