 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePandora: Leveraging Code-driven Knowledge Transfer for Unified Structured Knowledge Reasoning
Aug 25, 2025Unified Structured Knowledge Reasoning (USKR) aims to answer natural language questions by using structured sources such as tables, databases, and knowledge graphs in a unified way. Existing USKR methods rely on task-specific strategies or bespoke representations, which hinder their ability to dismantle barriers between different SKR tasks, thereby constraining their overall performance in cross-task scenarios. In this paper, we introduce \textsc{Pandora}, a novel USKR framework that addresses the limitations of existing methods by leveraging two key innovations. First, we propose a code-based unified knowledge representation using \textsc{Python}'s \textsc{Pandas} API, which aligns seamlessly with the pre-training of LLMs. This representation facilitates a cohesive approach to handling different structured knowledge sources. Building on this foundation, we employ knowledge transfer to bolster the unified reasoning process of LLMs by automatically building cross-task memory. By adaptively correcting reasoning using feedback from code execution, \textsc{Pandora} showcases impressive unified reasoning capabilities. Extensive experiments on six widely used benchmarks across three SKR tasks demonstrate that \textsc{Pandora} outperforms existing unified reasoning frameworks and competes effectively with task-specific methods.
OneEval: Benchmarking LLM Knowledge-intensive Reasoning over Diverse Knowledge Bases
Jun 14, 2025



Large Language Models (LLMs) have demonstrated substantial progress on reasoning tasks involving unstructured text, yet their capabilities significantly deteriorate when reasoning requires integrating structured external knowledge such as knowledge graphs, code snippets, or formal logic. This limitation is partly due to the absence of benchmarks capable of systematically evaluating LLM performance across diverse structured knowledge modalities. To address this gap, we introduce \textbf{\textsc{OneEval}}, a comprehensive benchmark explicitly designed to assess the knowledge-intensive reasoning capabilities of LLMs across four structured knowledge modalities, unstructured text, knowledge graphs, code, and formal logic, and five critical domains (general knowledge, government, science, law, and programming). \textsc{OneEval} comprises 4,019 carefully curated instances and includes a challenging subset, \textsc{OneEval}\textsubscript{Hard}, consisting of 1,285 particularly difficult cases. Through extensive evaluation of 18 state-of-the-art open-source and proprietary LLMs, we establish three core findings: a) \emph{persistent limitations in structured reasoning}, with even the strongest model achieving only 32.2\% accuracy on \textsc{OneEval}\textsubscript{Hard}; b) \emph{performance consistently declines as the structural complexity of the knowledge base increases}, with accuracy dropping sharply from 53\% (textual reasoning) to 25\% (formal logic); and c) \emph{diminishing returns from extended reasoning chains}, highlighting the critical need for models to adapt reasoning depth appropriately to task complexity. We release the \textsc{OneEval} datasets, evaluation scripts, and baseline results publicly, accompanied by a leaderboard to facilitate ongoing advancements in structured knowledge reasoning.
Table-r1: Self-supervised and Reinforcement Learning for Program-based Table Reasoning in Small Language Models
Jun 06, 2025Table reasoning (TR) requires structured reasoning over semi-structured tabular data and remains challenging, particularly for small language models (SLMs, e.g., LLaMA-8B) due to their limited capacity compared to large LMs (LLMs, e.g., GPT-4o). To narrow this gap, we explore program-based TR (P-TR), which circumvents key limitations of text-based TR (T-TR), notably in numerical reasoning, by generating executable programs. However, applying P-TR to SLMs introduces two challenges: (i) vulnerability to heterogeneity in table layouts, and (ii) inconsistency in reasoning due to limited code generation capability. We propose Table-r1, a two-stage P-TR method designed for SLMs. Stage 1 introduces an innovative self-supervised learning task, Layout Transformation Inference, to improve tabular layout generalization from a programmatic view. Stage 2 adopts a mix-paradigm variant of Group Relative Policy Optimization, enhancing P-TR consistency while allowing dynamic fallback to T-TR when needed. Experiments on four TR benchmarks demonstrate that Table-r1 outperforms all SLM-based methods, achieving at least a 15% accuracy improvement over the base model (LLaMA-8B) across all datasets and reaching performance competitive with LLMs.
Magic Mushroom: A Customizable Benchmark for Fine-grained Analysis of Retrieval Noise Erosion in RAG Systems
Jun 05, 2025
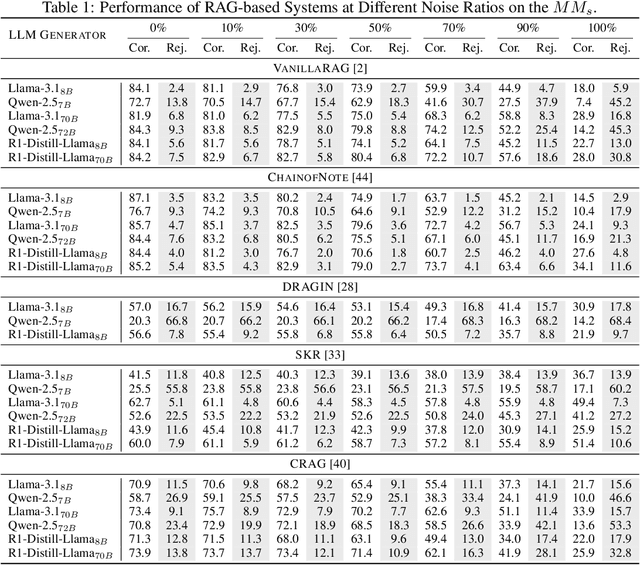


Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by incorporating external retrieved information, mitigating issues such as hallucination and outdated knowledge. However, RAG systems are highly sensitive to retrieval noise prevalent in real-world scenarios. Existing benchmarks fail to emulate the complex and heterogeneous noise distributions encountered in real-world retrieval environments, undermining reliable robustness assessment. In this paper, we define four categories of retrieval noise based on linguistic properties and noise characteristics, aiming to reflect the heterogeneity of noise in real-world scenarios. Building on this, we introduce Magic Mushroom, a benchmark for replicating "magic mushroom" noise: contexts that appear relevant on the surface but covertly mislead RAG systems. Magic Mushroom comprises 7,468 single-hop and 3,925 multi-hop question-answer pairs. More importantly, Magic Mushroom enables researchers to flexibly configure combinations of retrieval noise according to specific research objectives or application scenarios, allowing for highly controlled evaluation setups. We evaluate LLM generators of varying parameter scales and classic RAG denoising strategies under diverse noise distributions to investigate their performance dynamics during progressive noise encroachment. Our analysis reveals that both generators and denoising strategies have significant room for improvement and exhibit extreme sensitivity to noise distributions. Magic Mushroom emerges as a promising tool for evaluating and advancing noise-robust RAG systems, accelerating their widespread deployment in real-world applications. The Magic Mushroom benchmark is available at https://drive.google.com/file/d/1aP5kyPuk4L-L_uoI6T9UhxuTyt8oMqjT/view?usp=sharing.
After Retrieval, Before Generation: Enhancing the Trustworthiness of Large Language Models in RAG
May 21, 2025



Retrieval-augmented generation (RAG) systems face critical challenges in balancing internal (parametric) and external (retrieved) knowledge, especially when these sources conflict or are unreliable. To analyze these scenarios comprehensively, we construct the Trustworthiness Response Dataset (TRD) with 36,266 questions spanning four RAG settings. We reveal that existing approaches address isolated scenarios-prioritizing one knowledge source, naively merging both, or refusing answers-but lack a unified framework to handle different real-world conditions simultaneously. Therefore, we propose the BRIDGE framework, which dynamically determines a comprehensive response strategy of large language models (LLMs). BRIDGE leverages an adaptive weighting mechanism named soft bias to guide knowledge collection, followed by a Maximum Soft-bias Decision Tree to evaluate knowledge and select optimal response strategies (trust internal/external knowledge, or refuse). Experiments show BRIDGE outperforms baselines by 5-15% in accuracy while maintaining balanced performance across all scenarios. Our work provides an effective solution for LLMs' trustworthy responses in real-world RAG applications.
Pandora: A Code-Driven Large Language Model Agent for Unified Reasoning Across Diverse Structured Knowledge
Apr 17, 2025



Unified Structured Knowledge Reasoning (USKR) aims to answer natural language questions (NLQs) by using structured sources such as tables, databases, and knowledge graphs in a unified way. Existing USKR methods either rely on employing task-specific strategies or custom-defined representations, which struggle to leverage the knowledge transfer between different SKR tasks or align with the prior of LLMs, thereby limiting their performance. This paper proposes a novel USKR framework named \textsc{Pandora}, which takes advantage of \textsc{Python}'s \textsc{Pandas} API to construct a unified knowledge representation for alignment with LLM pre-training. It employs an LLM to generate textual reasoning steps and executable Python code for each question. Demonstrations are drawn from a memory of training examples that cover various SKR tasks, facilitating knowledge transfer. Extensive experiments on four benchmarks involving three SKR tasks demonstrate that \textsc{Pandora} outperforms existing unified frameworks and competes effectively with task-specific methods.
Harnessing Diverse Perspectives: A Multi-Agent Framework for Enhanced Error Detection in Knowledge Graphs
Jan 27, 2025



Knowledge graphs are widely used in industrial applications, making error detection crucial for ensuring the reliability of downstream applications. Existing error detection methods often fail to effectively leverage fine-grained subgraph information and rely solely on fixed graph structures, while also lacking transparency in their decision-making processes, which results in suboptimal detection performance. In this paper, we propose a novel Multi-Agent framework for Knowledge Graph Error Detection (MAKGED) that utilizes multiple large language models (LLMs) in a collaborative setting. By concatenating fine-grained, bidirectional subgraph embeddings with LLM-based query embeddings during training, our framework integrates these representations to produce four specialized agents. These agents utilize subgraph information from different dimensions to engage in multi-round discussions, thereby improving error detection accuracy and ensuring a transparent decision-making process. Extensive experiments on FB15K and WN18RR demonstrate that MAKGED outperforms state-of-the-art methods, enhancing the accuracy and robustness of KG evaluation. For specific industrial scenarios, our framework can facilitate the training of specialized agents using domain-specific knowledge graphs for error detection, which highlights the potential industrial application value of our framework. Our code and datasets are available at https://github.com/kse-ElEvEn/MAKGED.
Single Image Unlearning: Efficient Machine Unlearning in Multimodal Large Language Models
May 21, 2024



Machine unlearning empowers individuals with the `right to be forgotten' by removing their private or sensitive information encoded in machine learning models. However, it remains uncertain whether MU can be effectively applied to Multimodal Large Language Models (MLLMs), particularly in scenarios of forgetting the leaked visual data of concepts. To overcome the challenge, we propose an efficient method, Single Image Unlearning (SIU), to unlearn the visual recognition of a concept by fine-tuning a single associated image for few steps. SIU consists of two key aspects: (i) Constructing Multifaceted fine-tuning data. We introduce four targets, based on which we construct fine-tuning data for the concepts to be forgotten; (ii) Jointly training loss. To synchronously forget the visual recognition of concepts and preserve the utility of MLLMs, we fine-tune MLLMs through a novel Dual Masked KL-divergence Loss combined with Cross Entropy loss. Alongside our method, we establish MMUBench, a new benchmark for MU in MLLMs and introduce a collection of metrics for its evaluation. Experimental results on MMUBench show that SIU completely surpasses the performance of existing methods. Furthermore, we surprisingly find that SIU can avoid invasive membership inference attacks and jailbreak attacks. To the best of our knowledge, we are the first to explore MU in MLLMs. We will release the code and benchmark in the near future.
HGT: Leveraging Heterogeneous Graph-enhanced Large Language Models for Few-shot Complex Table Understanding
Mar 28, 2024
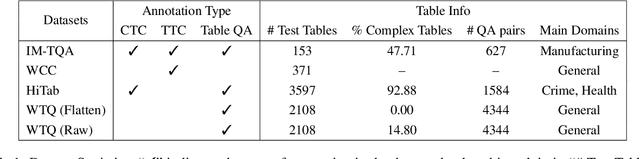

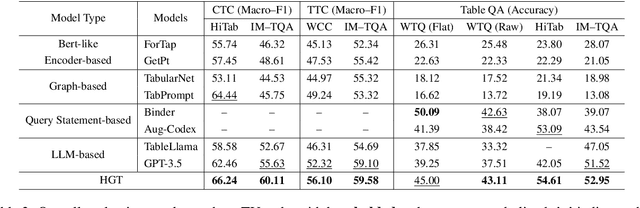
Table understanding (TU) has achieved promising advancements, but it faces the challenges of the scarcity of manually labeled tables and the presence of complex table structures.To address these challenges, we propose HGT, a framework with a heterogeneous graph (HG)-enhanced large language model (LLM) to tackle few-shot TU tasks.It leverages the LLM by aligning the table semantics with the LLM's parametric knowledge through soft prompts and instruction turning and deals with complex tables by a multi-task pre-training scheme involving three novel multi-granularity self-supervised HG pre-training objectives.We empirically demonstrate the effectiveness of HGT, showing that it outperforms the SOTA for few-shot complex TU on several benchmarks.
MATEval: A Multi-Agent Discussion Framework for Advancing Open-Ended Text Evaluation
Mar 28, 2024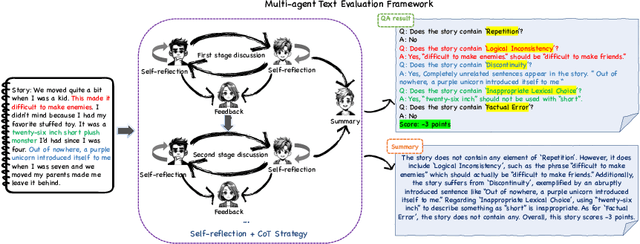


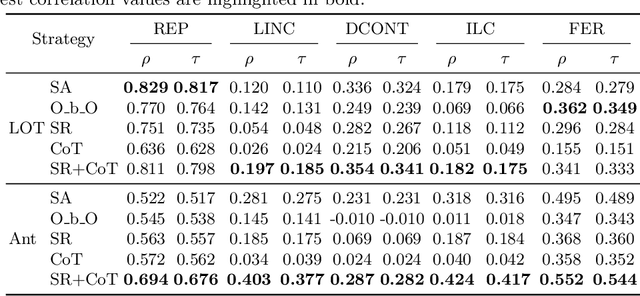
Recent advancements in generative Large Language Models(LLMs) have been remarkable, however, the quality of the text generated by these models often reveals persistent issues. Evaluating the quality of text generated by these models, especially in open-ended text, has consistently presented a significant challenge. Addressing this, recent work has explored the possibility of using LLMs as evaluators. While using a single LLM as an evaluation agent shows potential, it is filled with significant uncertainty and instability. To address these issues, we propose the MATEval: A "Multi-Agent Text Evaluation framework" where all agents are played by LLMs like GPT-4. The MATEval framework emulates human collaborative discussion methods, integrating multiple agents' interactions to evaluate open-ended text. Our framework incorporates self-reflection and Chain-of-Thought (CoT) strategies, along with feedback mechanisms, enhancing the depth and breadth of the evaluation process and guiding discussions towards consensus, while the framework generates comprehensive evaluation reports, including error localization, error types and scoring. Experimental results show that our framework outperforms existing open-ended text evaluation methods and achieves the highest correlation with human evaluation, which confirms the effectiveness and advancement of our framework in addressing the uncertainties and instabilities in evaluating LLMs-generated text. Furthermore, our framework significantly improves the efficiency of text evaluation and model iteration in industrial scenarios.