 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmooth, Sparse, and Stable: Finite-Time Exact Skeleton Recovery via Smoothed Proximal Gradients
Jan 26, 2026Continuous optimization has significantly advanced causal discovery, yet existing methods (e.g., NOTEARS) generally guarantee only asymptotic convergence to a stationary point. This often yields dense weighted matrices that require arbitrary post-hoc thresholding to recover a DAG. This gap between continuous optimization and discrete graph structures remains a fundamental challenge. In this paper, we bridge this gap by proposing the Hybrid-Order Acyclicity Constraint (AHOC) and optimizing it via the Smoothed Proximal Gradient (SPG-AHOC). Leveraging the Manifold Identification Property of proximal algorithms, we provide a rigorous theoretical guarantee: the Finite-Time Oracle Property. We prove that under standard identifiability assumptions, SPG-AHOC recovers the exact DAG support (structure) in finite iterations, even when optimizing a smoothed approximation. This result eliminates structural ambiguity, as our algorithm returns graphs with exact zero entries without heuristic truncation. Empirically, SPG-AHOC achieves state-of-the-art accuracy and strongly corroborates the finite-time identification theory.
Chinese Labor Law Large Language Model Benchmark
Jan 15, 2026Recent advances in large language models (LLMs) have led to substantial progress in domain-specific applications, particularly within the legal domain. However, general-purpose models such as GPT-4 often struggle with specialized subdomains that require precise legal knowledge, complex reasoning, and contextual sensitivity. To address these limitations, we present LabourLawLLM, a legal large language model tailored to Chinese labor law. We also introduce LabourLawBench, a comprehensive benchmark covering diverse labor-law tasks, including legal provision citation, knowledge-based question answering, case classification, compensation computation, named entity recognition, and legal case analysis. Our evaluation framework combines objective metrics (e.g., ROUGE-L, accuracy, F1, and soft-F1) with subjective assessment based on GPT-4 scoring. Experiments show that LabourLawLLM consistently outperforms general-purpose and existing legal-specific LLMs across task categories. Beyond labor law, our methodology provides a scalable approach for building specialized LLMs in other legal subfields, improving accuracy, reliability, and societal value of legal AI applications.
Reasoning over Precedents Alongside Statutes: Case-Augmented Deliberative Alignment for LLM Safety
Jan 12, 2026Ensuring that Large Language Models (LLMs) adhere to safety principles without refusing benign requests remains a significant challenge. While OpenAI introduces deliberative alignment (DA) to enhance the safety of its o-series models through reasoning over detailed ``code-like'' safety rules, the effectiveness of this approach in open-source LLMs, which typically lack advanced reasoning capabilities, is understudied. In this work, we systematically evaluate the impact of explicitly specifying extensive safety codes versus demonstrating them through illustrative cases. We find that referencing explicit codes inconsistently improves harmlessness and systematically degrades helpfulness, whereas training on case-augmented simple codes yields more robust and generalized safety behaviors. By guiding LLMs with case-augmented reasoning instead of extensive code-like safety rules, we avoid rigid adherence to narrowly enumerated rules and enable broader adaptability. Building on these insights, we propose CADA, a case-augmented deliberative alignment method for LLMs utilizing reinforcement learning on self-generated safety reasoning chains. CADA effectively enhances harmlessness, improves robustness against attacks, and reduces over-refusal while preserving utility across diverse benchmarks, offering a practical alternative to rule-only DA for improving safety while maintaining helpfulness.
AlignDrive: Aligned Lateral-Longitudinal Planning for End-to-End Autonomous Driving
Jan 05, 2026End-to-end autonomous driving has rapidly progressed, enabling joint perception and planning in complex environments. In the planning stage, state-of-the-art (SOTA) end-to-end autonomous driving models decouple planning into parallel lateral and longitudinal predictions. While effective, this parallel design can lead to i) coordination failures between the planned path and speed, and ii) underutilization of the drive path as a prior for longitudinal planning, thus redundantly encoding static information. To address this, we propose a novel cascaded framework that explicitly conditions longitudinal planning on the drive path, enabling coordinated and collision-aware lateral and longitudinal planning. Specifically, we introduce a path-conditioned formulation that explicitly incorporates the drive path into longitudinal planning. Building on this, the model predicts longitudinal displacements along the drive path rather than full 2D trajectory waypoints. This design simplifies longitudinal reasoning and more tightly couples it with lateral planning. Additionally, we introduce a planning-oriented data augmentation strategy that simulates rare safety-critical events, such as vehicle cut-ins, by adding agents and relabeling longitudinal targets to avoid collision. Evaluated on the challenging Bench2Drive benchmark, our method sets a new SOTA, achieving a driving score of 89.07 and a success rate of 73.18%, demonstrating significantly improved coordination and safety
The Causal Round Trip: Generating Authentic Counterfactuals by Eliminating Information Loss
Nov 07, 2025Judea Pearl's vision of Structural Causal Models (SCMs) as engines for counterfactual reasoning hinges on faithful abduction: the precise inference of latent exogenous noise. For decades, operationalizing this step for complex, non-linear mechanisms has remained a significant computational challenge. The advent of diffusion models, powerful universal function approximators, offers a promising solution. However, we argue that their standard design, optimized for perceptual generation over logical inference, introduces a fundamental flaw for this classical problem: an inherent information loss we term the Structural Reconstruction Error (SRE). To address this challenge, we formalize the principle of Causal Information Conservation (CIC) as the necessary condition for faithful abduction. We then introduce BELM-MDCM, the first diffusion-based framework engineered to be causally sound by eliminating SRE by construction through an analytically invertible mechanism. To operationalize this framework, a Targeted Modeling strategy provides structural regularization, while a Hybrid Training Objective instills a strong causal inductive bias. Rigorous experiments demonstrate that our Zero-SRE framework not only achieves state-of-the-art accuracy but, more importantly, enables the high-fidelity, individual-level counterfactuals required for deep causal inquiries. Our work provides a foundational blueprint that reconciles the power of modern generative models with the rigor of classical causal theory, establishing a new and more rigorous standard for this emerging field.
Read the Scene, Not the Script: Outcome-Aware Safety for LLMs
Oct 05, 2025Safety-aligned Large Language Models (LLMs) still show two dominant failure modes: they are easily jailbroken, or they over-refuse harmless inputs that contain sensitive surface signals. We trace both to a common cause: current models reason weakly about links between actions and outcomes and over-rely on surface-form signals, lexical or stylistic cues that do not encode consequences. We define this failure mode as Consequence-blindness. To study consequence-blindness, we build a benchmark named CB-Bench covering four risk scenarios that vary whether semantic risk aligns with outcome risk, enabling evaluation under both matched and mismatched conditions which are often ignored by existing safety benchmarks. Mainstream models consistently fail to separate these risks and exhibit consequence-blindness, indicating that consequence-blindness is widespread and systematic. To mitigate consequence-blindness, we introduce CS-Chain-4k, a consequence-reasoning dataset for safety alignment. Models fine-tuned on CS-Chain-4k show clear gains against semantic-camouflage jailbreaks and reduce over-refusal on harmless inputs, while maintaining utility and generalization on other benchmarks. These results clarify the limits of current alignment, establish consequence-aware reasoning as a core alignment goal and provide a more practical and reproducible evaluation path.
A Learning-based Domain Decomposition Method
Jul 23, 2025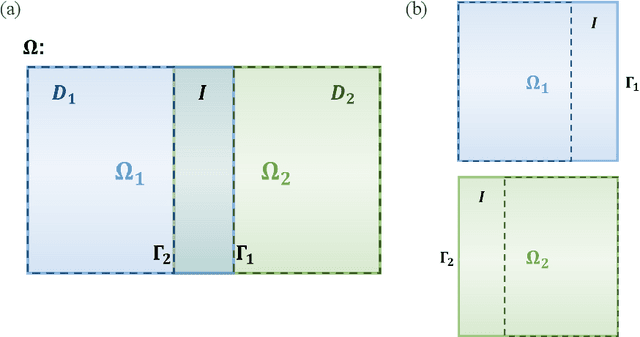
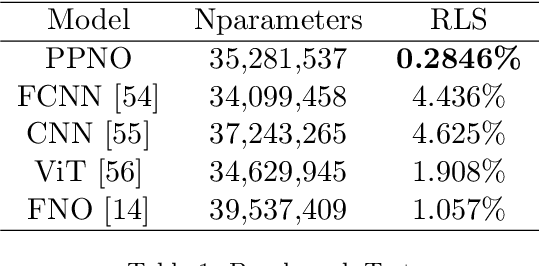
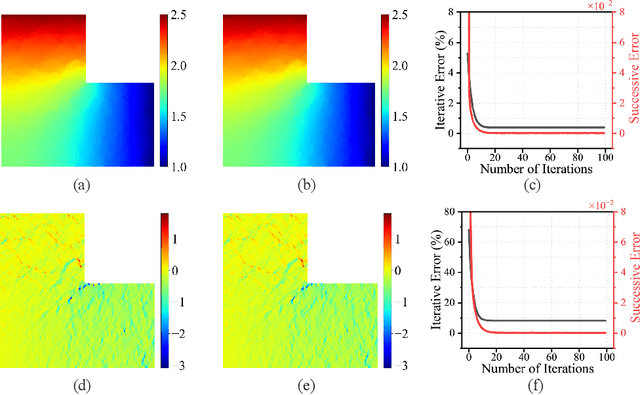
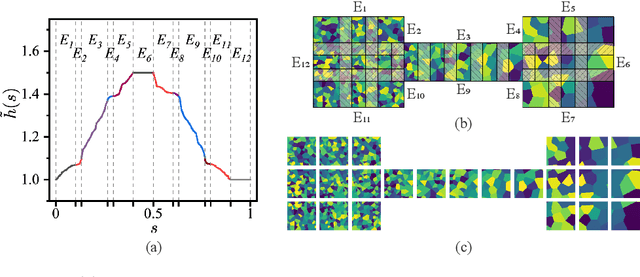
Recent developments in mechanical, aerospace, and structural engineering have driven a growing need for efficient ways to model and analyse structures at much larger and more complex scales than before. While established numerical methods like the Finite Element Method remain reliable, they often struggle with computational cost and scalability when dealing with large and geometrically intricate problems. In recent years, neural network-based methods have shown promise because of their ability to efficiently approximate nonlinear mappings. However, most existing neural approaches are still largely limited to simple domains, which makes it difficult to apply to real-world PDEs involving complex geometries. In this paper, we propose a learning-based domain decomposition method (L-DDM) that addresses this gap. Our approach uses a single, pre-trained neural operator-originally trained on simple domains-as a surrogate model within a domain decomposition scheme, allowing us to tackle large and complicated domains efficiently. We provide a general theoretical result on the existence of neural operator approximations in the context of domain decomposition solution of abstract PDEs. We then demonstrate our method by accurately approximating solutions to elliptic PDEs with discontinuous microstructures in complex geometries, using a physics-pretrained neural operator (PPNO). Our results show that this approach not only outperforms current state-of-the-art methods on these challenging problems, but also offers resolution-invariance and strong generalization to microstructural patterns unseen during training.
Generating Multimodal Driving Scenes via Next-Scene Prediction
Mar 19, 2025Generative models in Autonomous Driving (AD) enable diverse scene creation, yet existing methods fall short by only capturing a limited range of modalities, restricting the capability of generating controllable scenes for comprehensive evaluation of AD systems. In this paper, we introduce a multimodal generation framework that incorporates four major data modalities, including a novel addition of map modality. With tokenized modalities, our scene sequence generation framework autoregressively predicts each scene while managing computational demands through a two-stage approach. The Temporal AutoRegressive (TAR) component captures inter-frame dynamics for each modality while the Ordered AutoRegressive (OAR) component aligns modalities within each scene by sequentially predicting tokens in a fixed order. To maintain coherence between map and ego-action modalities, we introduce the Action-aware Map Alignment (AMA) module, which applies a transformation based on the ego-action to maintain coherence between these modalities. Our framework effectively generates complex, realistic driving scenes over extended sequences, ensuring multimodal consistency and offering fine-grained control over scene elements.
MobileFlow: A Multimodal LLM For Mobile GUI Agent
Jul 05, 2024Currently, the integration of mobile Graphical User Interfaces (GUIs) is ubiquitous in most people's daily lives. And the ongoing evolution of multimodal large-scale models, such as GPT-4v, Qwen-VL-Max, has significantly bolstered the capabilities of GUI comprehension and user action analysis, showcasing the potentiality of intelligent GUI assistants. However, current GUI Agents often need to access page layout information through calling system APIs, which may pose privacy risks. Fixing GUI (such as mobile interfaces) to a certain low resolution might result in the loss of fine-grained image details. At the same time, the multimodal large models built for GUI Agents currently have poor understanding and decision-making abilities for Chinese GUI interfaces, making them difficult to apply to a large number of Chinese apps. This paper introduces MobileFlow, a multimodal large language model meticulously crafted for mobile GUI agents. Transforming from the open-source model Qwen-VL-Chat into GUI domain, MobileFlow contains approximately 21 billion parameters and is equipped with novel hybrid visual encoders, making it possible for variable resolutions of image inputs and good support for multilingual GUI. By incorporating Mixture of Experts (MoE) expansions and pioneering alignment training strategies, MobileFlow has the capacity to fully interpret image data and comprehend user instructions for GUI interaction tasks. Finally, MobileFlow outperforms Qwen-VL-Max and GPT-4v in terms of task execution by GUI agents on both public and our proposed evaluation metrics, and has been successfully deployed in real-world business contexts, proving its effectiveness for practical applications.
Undergraduate Robotics Education with General Instructors using a Student-Centered Personalized Learning Framework
Jun 12, 2024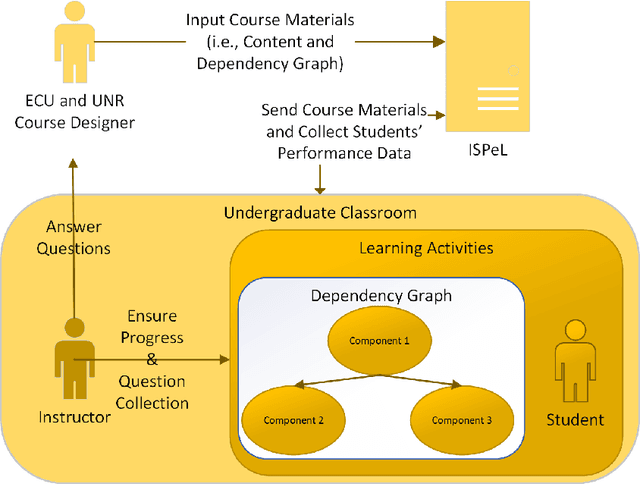
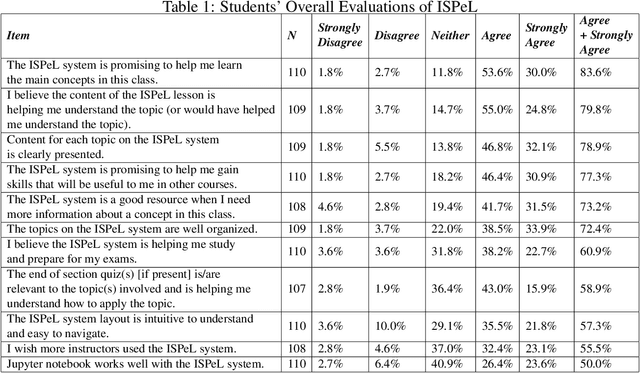
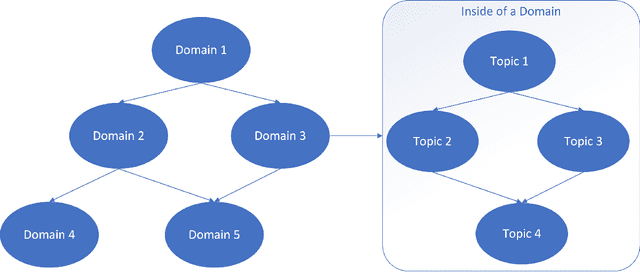
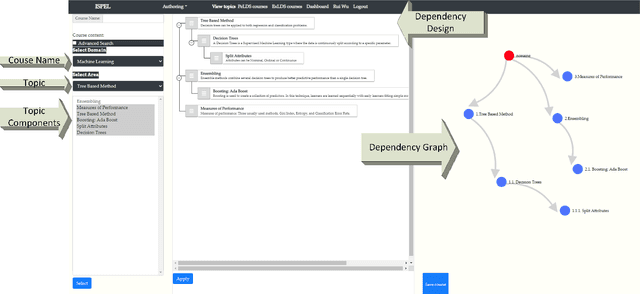
Recent advancements in robotics, including applications like self-driving cars, unmanned systems, and medical robots, have had a significant impact on the job market. On one hand, big robotics companies offer training programs based on the job requirements. However, these training programs may not be as beneficial as general robotics programs offered by universities or community colleges. On the other hand, community colleges and universities face challenges with required resources, especially qualified instructors, to offer students advanced robotics education. Furthermore, the diverse backgrounds of undergraduate students present additional challenges. Some students bring extensive industry experiences, while others are newcomers to the field. To address these challenges, we propose a student-centered personalized learning framework for robotics. This framework allows a general instructor to teach undergraduate-level robotics courses by breaking down course topics into smaller components with well-defined topic dependencies, structured as a graph. This modular approach enables students to choose their learning path, catering to their unique preferences and pace. Moreover, our framework's flexibility allows for easy customization of teaching materials to meet the specific needs of host institutions. In addition to teaching materials, a frequently-asked-questions document would be prepared for a general instructor. If students' robotics questions cannot be answered by the instructor, the answers to these questions may be included in this document. For questions not covered in this document, we can gather and address them through collaboration with the robotics community and course content creators. Our user study results demonstrate the promise of this method in delivering undergraduate-level robotics education tailored to individual learning outcomes and preferences.