 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Multimodal Driving Scenes via Next-Scene Prediction
Mar 19, 2025Generative models in Autonomous Driving (AD) enable diverse scene creation, yet existing methods fall short by only capturing a limited range of modalities, restricting the capability of generating controllable scenes for comprehensive evaluation of AD systems. In this paper, we introduce a multimodal generation framework that incorporates four major data modalities, including a novel addition of map modality. With tokenized modalities, our scene sequence generation framework autoregressively predicts each scene while managing computational demands through a two-stage approach. The Temporal AutoRegressive (TAR) component captures inter-frame dynamics for each modality while the Ordered AutoRegressive (OAR) component aligns modalities within each scene by sequentially predicting tokens in a fixed order. To maintain coherence between map and ego-action modalities, we introduce the Action-aware Map Alignment (AMA) module, which applies a transformation based on the ego-action to maintain coherence between these modalities. Our framework effectively generates complex, realistic driving scenes over extended sequences, ensuring multimodal consistency and offering fine-grained control over scene elements.
M3DSSD: Monocular 3D Single Stage Object Detector
Mar 24, 2021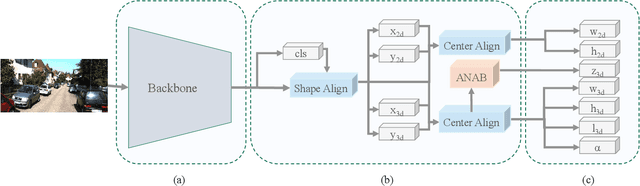
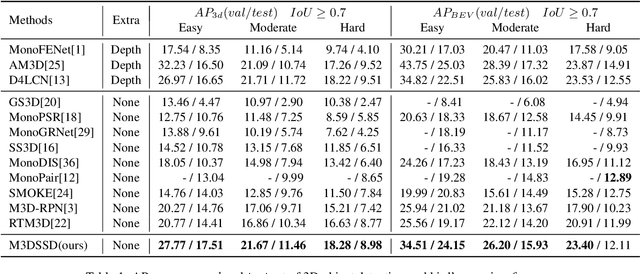
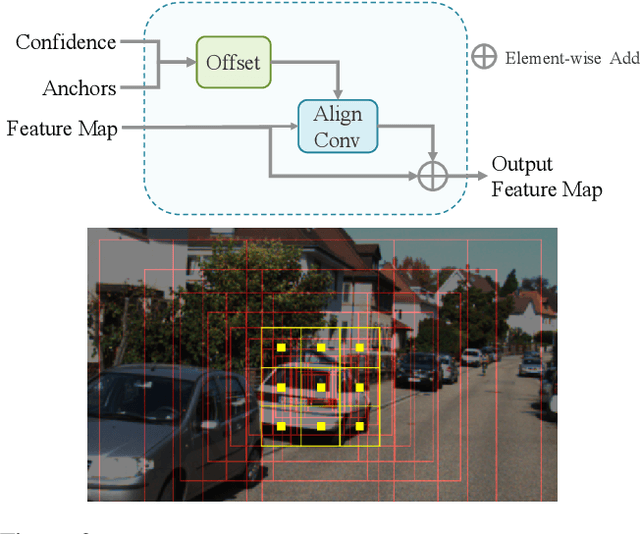
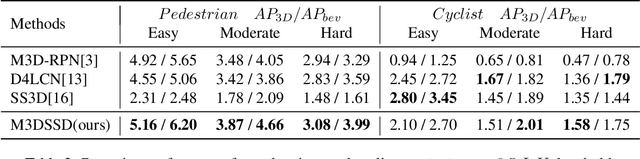
In this paper, we propose a Monocular 3D Single Stage object Detector (M3DSSD) with feature alignment and asymmetric non-local attention. Current anchor-based monocular 3D object detection methods suffer from feature mismatching. To overcome this, we propose a two-step feature alignment approach. In the first step, the shape alignment is performed to enable the receptive field of the feature map to focus on the pre-defined anchors with high confidence scores. In the second step, the center alignment is used to align the features at 2D/3D centers. Further, it is often difficult to learn global information and capture long-range relationships, which are important for the depth prediction of objects. Therefore, we propose a novel asymmetric non-local attention block with multi-scale sampling to extract depth-wise features. The proposed M3DSSD achieves significantly better performance than the monocular 3D object detection methods on the KITTI dataset, in both 3D object detection and bird's eye view tasks.
3D IoU-Net: IoU Guided 3D Object Detector for Point Clouds
Apr 10, 2020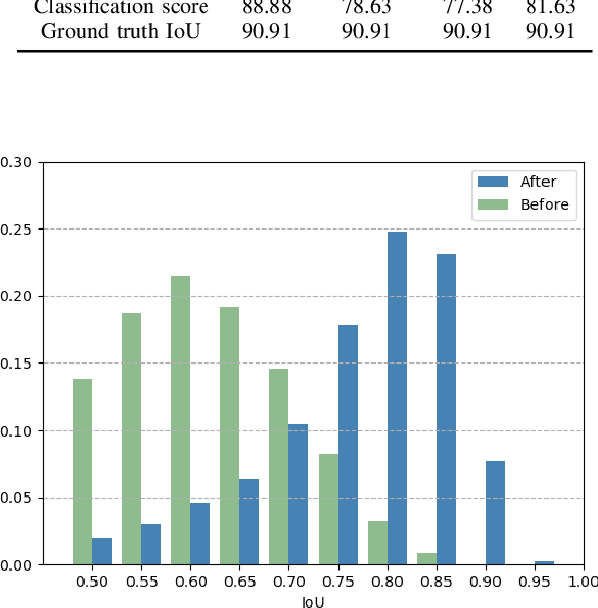
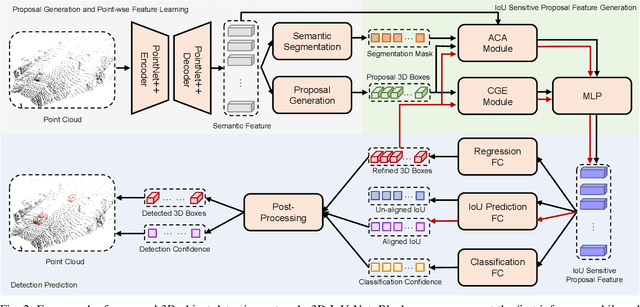
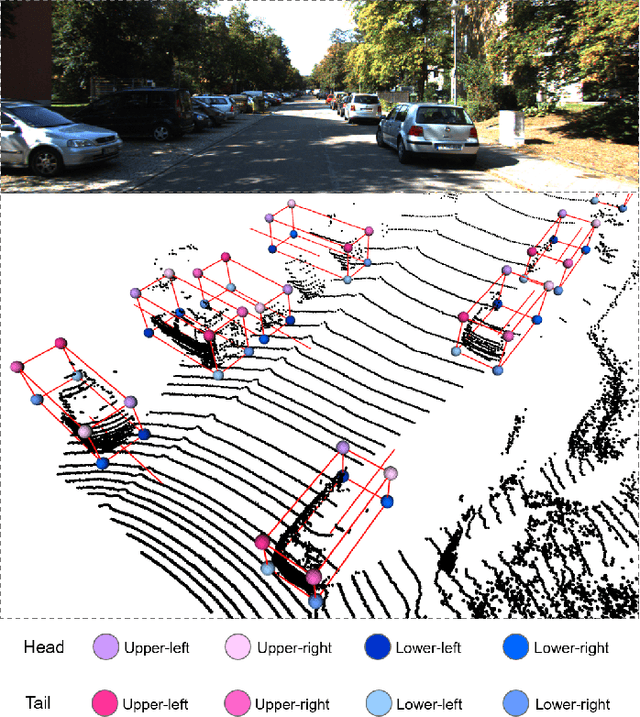
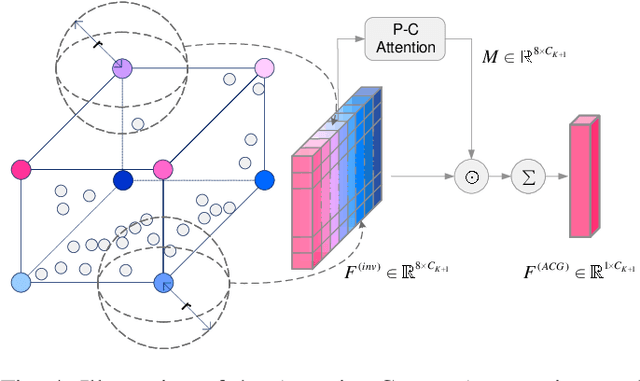
Most existing point cloud based 3D object detectors focus on the tasks of classification and box regression. However, another bottleneck in this area is achieving an accurate detection confidence for the Non-Maximum Suppression (NMS) post-processing. In this paper, we add a 3D IoU prediction branch to the regular classification and regression branches. The predicted IoU is used as the detection confidence for NMS. In order to obtain a more accurate IoU prediction, we propose a 3D IoU-Net with IoU sensitive feature learning and an IoU alignment operation. To obtain a perspective-invariant prediction head, we propose an Attentive Corner Aggregation (ACA) module by aggregating a local point cloud feature from each perspective of eight corners and adaptively weighting the contribution of each perspective with different attentions. We propose a Corner Geometry Encoding (CGE) module for geometry information embedding. To the best of our knowledge, this is the first time geometric embedding information has been introduced in proposal feature learning. These two feature parts are then adaptively fused by a multi-layer perceptron (MLP) network as our IoU sensitive feature. The IoU alignment operation is introduced to resolve the mismatching between the bounding box regression head and IoU prediction, thereby further enhancing the accuracy of IoU prediction. The experimental results on the KITTI car detection benchmark show that 3D IoU-Net with IoU perception achieves state-of-the-art performance.