 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Rival Data as Rival Products: An Encapsulation-Forging Approach for Data Synthesis
Nov 10, 2025

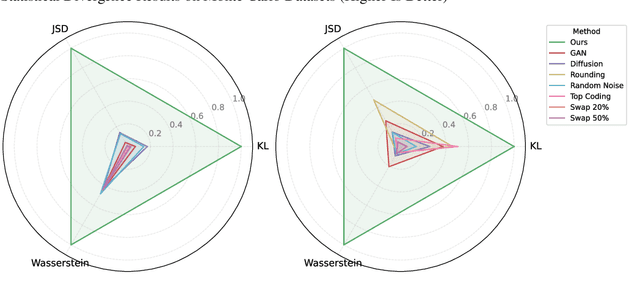

The non-rival nature of data creates a dilemma for firms: sharing data unlocks value but risks eroding competitive advantage. Existing data synthesis methods often exacerbate this problem by creating data with symmetric utility, allowing any party to extract its value. This paper introduces the Encapsulation-Forging (EnFo) framework, a novel approach to generate rival synthetic data with asymmetric utility. EnFo operates in two stages: it first encapsulates predictive knowledge from the original data into a designated ``key'' model, and then forges a synthetic dataset by optimizing the data to intentionally overfit this key model. This process transforms non-rival data into a rival product, ensuring its value is accessible only to the intended model, thereby preventing unauthorized use and preserving the data owner's competitive edge. Our framework demonstrates remarkable sample efficiency, matching the original data's performance with a fraction of its size, while providing robust privacy protection and resistance to misuse. EnFo offers a practical solution for firms to collaborate strategically without compromising their core analytical advantage.
MIHBench: Benchmarking and Mitigating Multi-Image Hallucinations in Multimodal Large Language Models
Aug 01, 2025Despite growing interest in hallucination in Multimodal Large Language Models, existing studies primarily focus on single-image settings, leaving hallucination in multi-image scenarios largely unexplored. To address this gap, we conduct the first systematic study of hallucinations in multi-image MLLMs and propose MIHBench, a benchmark specifically tailored for evaluating object-related hallucinations across multiple images. MIHBench comprises three core tasks: Multi-Image Object Existence Hallucination, Multi-Image Object Count Hallucination, and Object Identity Consistency Hallucination, targeting semantic understanding across object existence, quantity reasoning, and cross-view identity consistency. Through extensive evaluation, we identify key factors associated with the occurrence of multi-image hallucinations, including: a progressive relationship between the number of image inputs and the likelihood of hallucination occurrences; a strong correlation between single-image hallucination tendencies and those observed in multi-image contexts; and the influence of same-object image ratios and the positional placement of negative samples within image sequences on the occurrence of object identity consistency hallucination. To address these challenges, we propose a Dynamic Attention Balancing mechanism that adjusts inter-image attention distributions while preserving the overall visual attention proportion. Experiments across multiple state-of-the-art MLLMs demonstrate that our method effectively reduces hallucination occurrences and enhances semantic integration and reasoning stability in multi-image scenarios.
TraDiffusion: Trajectory-Based Training-Free Image Generation
Aug 19, 2024



In this work, we propose a training-free, trajectory-based controllable T2I approach, termed TraDiffusion. This novel method allows users to effortlessly guide image generation via mouse trajectories. To achieve precise control, we design a distance awareness energy function to effectively guide latent variables, ensuring that the focus of generation is within the areas defined by the trajectory. The energy function encompasses a control function to draw the generation closer to the specified trajectory and a movement function to diminish activity in areas distant from the trajectory. Through extensive experiments and qualitative assessments on the COCO dataset, the results reveal that TraDiffusion facilitates simpler, more natural image control. Moreover, it showcases the ability to manipulate salient regions, attributes, and relationships within the generated images, alongside visual input based on arbitrary or enhanced trajectories.
ControlMLLM: Training-Free Visual Prompt Learning for Multimodal Large Language Models
Jul 31, 2024In this work, we propose a training-free method to inject visual referring into Multimodal Large Language Models (MLLMs) through learnable visual token optimization. We observe the relationship between text prompt tokens and visual tokens in MLLMs, where attention layers model the connection between them. Our approach involves adjusting visual tokens from the MLP output during inference, controlling which text prompt tokens attend to which visual tokens. We optimize a learnable visual token based on an energy function, enhancing the strength of referential regions in the attention map. This enables detailed region description and reasoning without the need for substantial training costs or model retraining. Our method offers a promising direction for integrating referential abilities into MLLMs. Our method support referring with box, mask, scribble and point. The results demonstrate that our method exhibits controllability and interpretability.
Evaluating and Analyzing Relationship Hallucinations in LVLMs
Jun 24, 2024



The issue of hallucinations is a prevalent concern in existing Large Vision-Language Models (LVLMs). Previous efforts have primarily focused on investigating object hallucinations, which can be easily alleviated by introducing object detectors. However, these efforts neglect hallucinations in inter-object relationships, which is essential for visual comprehension. In this work, we introduce R-Bench, a novel benchmark for evaluating Vision Relationship Hallucination. R-Bench features image-level questions that focus on the existence of relationships and instance-level questions that assess local visual comprehension. We identify three types of relationship co-occurrences that lead to hallucinations: relationship-relationship, subject-relationship, and relationship-object. The visual instruction tuning dataset's long-tail distribution significantly impacts LVLMs' understanding of visual relationships. Furthermore, our analysis reveals that current LVLMs tend to disregard visual content and overly rely on the common sense knowledge of Large Language Models. They also struggle with reasoning about spatial relationships based on contextual information.
DBFed: Debiasing Federated Learning Framework based on Domain-Independent
Jul 10, 2023

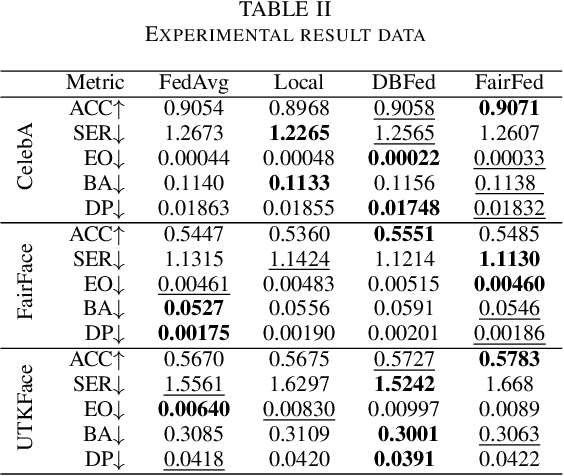
As digital transformation continues, enterprises are generating, managing, and storing vast amounts of data, while artificial intelligence technology is rapidly advancing. However, it brings challenges in information security and data security. Data security refers to the protection of digital information from unauthorized access, damage, theft, etc. throughout its entire life cycle. With the promulgation and implementation of data security laws and the emphasis on data security and data privacy by organizations and users, Privacy-preserving technology represented by federated learning has a wide range of application scenarios. Federated learning is a distributed machine learning computing framework that allows multiple subjects to train joint models without sharing data to protect data privacy and solve the problem of data islands. However, the data among multiple subjects are independent of each other, and the data differences in quality may cause fairness issues in federated learning modeling, such as data bias among multiple subjects, resulting in biased and discriminatory models. Therefore, we propose DBFed, a debiasing federated learning framework based on domain-independent, which mitigates model bias by explicitly encoding sensitive attributes during client-side training. This paper conducts experiments on three real datasets and uses five evaluation metrics of accuracy and fairness to quantify the effect of the model. Most metrics of DBFed exceed those of the other three comparative methods, fully demonstrating the debiasing effect of DBFed.
MSeg3D: Multi-modal 3D Semantic Segmentation for Autonomous Driving
Mar 15, 2023


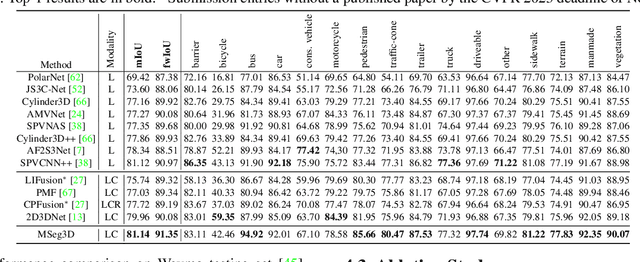
LiDAR and camera are two modalities available for 3D semantic segmentation in autonomous driving. The popular LiDAR-only methods severely suffer from inferior segmentation on small and distant objects due to insufficient laser points, while the robust multi-modal solution is under-explored, where we investigate three crucial inherent difficulties: modality heterogeneity, limited sensor field of view intersection, and multi-modal data augmentation. We propose a multi-modal 3D semantic segmentation model (MSeg3D) with joint intra-modal feature extraction and inter-modal feature fusion to mitigate the modality heterogeneity. The multi-modal fusion in MSeg3D consists of geometry-based feature fusion GF-Phase, cross-modal feature completion, and semantic-based feature fusion SF-Phase on all visible points. The multi-modal data augmentation is reinvigorated by applying asymmetric transformations on LiDAR point cloud and multi-camera images individually, which benefits the model training with diversified augmentation transformations. MSeg3D achieves state-of-the-art results on nuScenes, Waymo, and SemanticKITTI datasets. Under the malfunctioning multi-camera input and the multi-frame point clouds input, MSeg3D still shows robustness and improves the LiDAR-only baseline. Our code is publicly available at \url{https://github.com/jialeli1/lidarseg3d}.
From Voxel to Point: IoU-guided 3D Object Detection for Point Cloud with Voxel-to-Point Decoder
Aug 08, 2021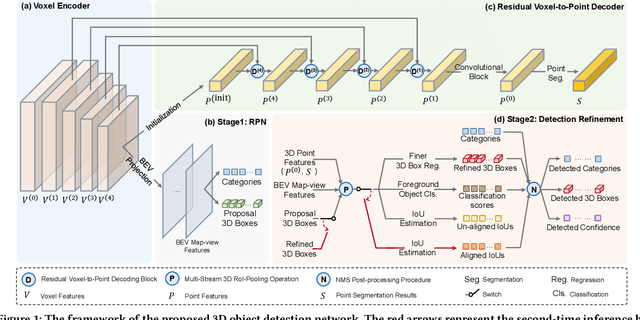
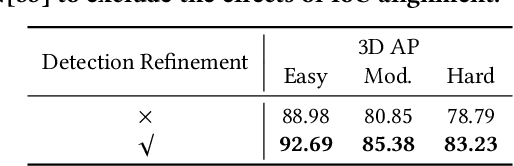
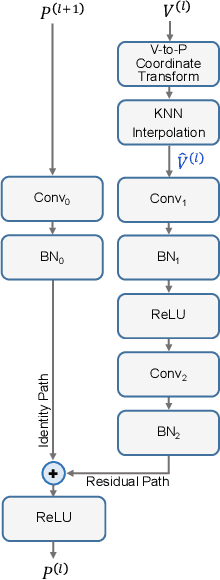
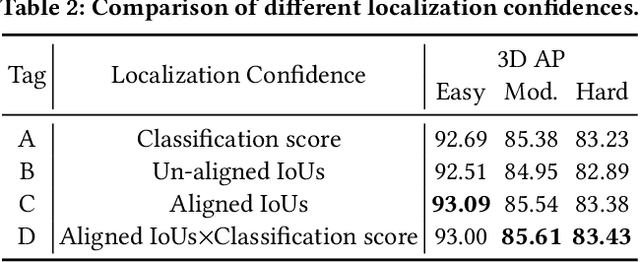
In this paper, we present an Intersection-over-Union (IoU) guided two-stage 3D object detector with a voxel-to-point decoder. To preserve the necessary information from all raw points and maintain the high box recall in voxel based Region Proposal Network (RPN), we propose a residual voxel-to-point decoder to extract the point features in addition to the map-view features from the voxel based RPN. We use a 3D Region of Interest (RoI) alignment to crop and align the features with the proposal boxes for accurately perceiving the object position. The RoI-Aligned features are finally aggregated with the corner geometry embeddings that can provide the potentially missing corner information in the box refinement stage. We propose a simple and efficient method to align the estimated IoUs to the refined proposal boxes as a more relevant localization confidence. The comprehensive experiments on KITTI and Waymo Open Dataset demonstrate that our method achieves significant improvements with novel architectures against the existing methods. The code is available on Github URL\footnote{\url{https://github.com/jialeli1/From-Voxel-to-Point}}.
Anchor-free 3D Single Stage Detector with Mask-Guided Attention for Point Cloud
Aug 08, 2021
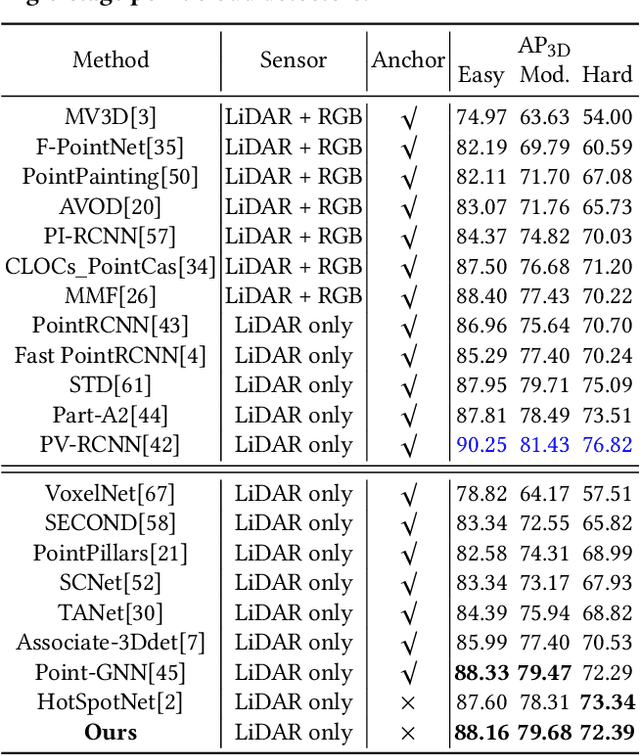


Most of the existing single-stage and two-stage 3D object detectors are anchor-based methods, while the efficient but challenging anchor-free single-stage 3D object detection is not well investigated. Recent studies on 2D object detection show that the anchor-free methods also are of great potential. However, the unordered and sparse properties of point clouds prevent us from directly leveraging the advanced 2D methods on 3D point clouds. We overcome this by converting the voxel-based sparse 3D feature volumes into the sparse 2D feature maps. We propose an attentive module to fit the sparse feature maps to dense mostly on the object regions through the deformable convolution tower and the supervised mask-guided attention. By directly regressing the 3D bounding box from the enhanced and dense feature maps, we construct a novel single-stage 3D detector for point clouds in an anchor-free manner. We propose an IoU-based detection confidence re-calibration scheme to improve the correlation between the detection confidence score and the accuracy of the bounding box regression. Our code is publicly available at \url{https://github.com/jialeli1/MGAF-3DSSD}.
General Robot Dynamics Learning and Gen2Real
Apr 06, 2021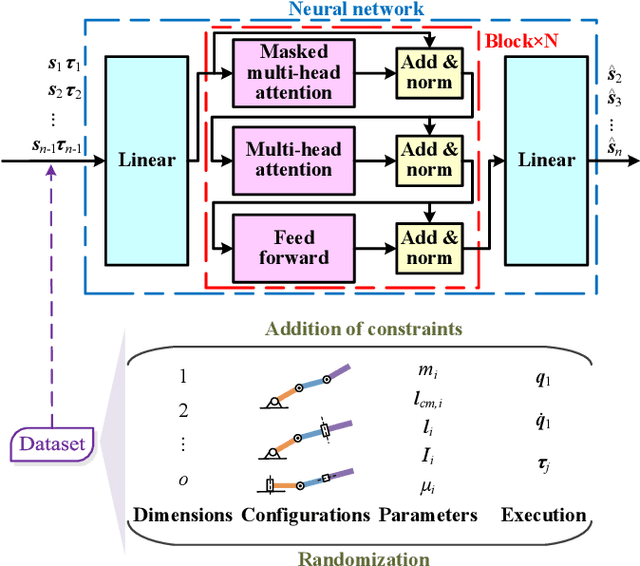
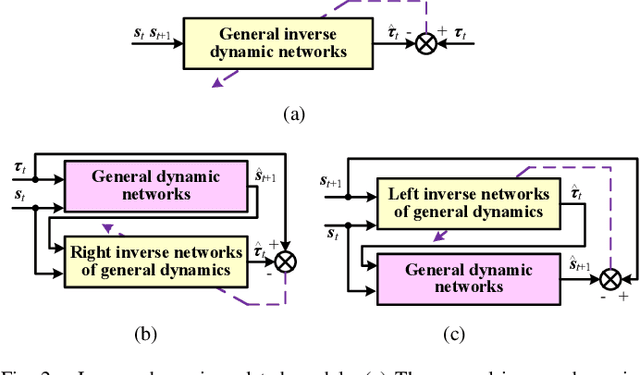
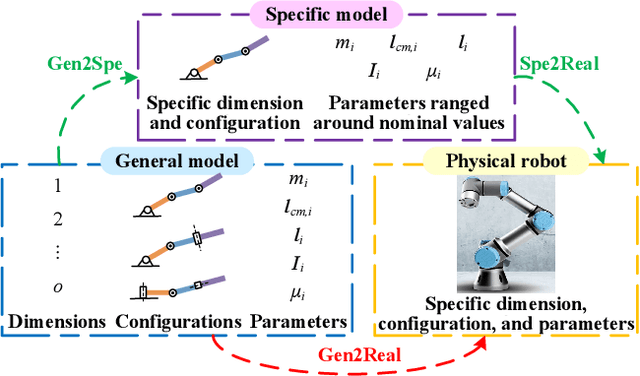
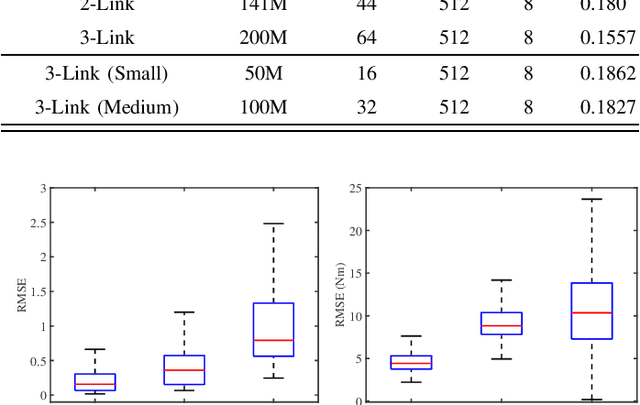
Acquiring dynamics is an essential topic in robot learning, but up-to-date methods, such as dynamics randomization, need to restart to check nominal parameters, generate simulation data, and train networks whenever they face different robots. To improve it, we novelly investigate general robot dynamics, its inverse models, and Gen2Real, which means transferring to reality. Our motivations are to build a model that learns the intrinsic dynamics of various robots and lower the threshold of dynamics learning by enabling an amateur to obtain robot models without being trapped in details. This paper achieves the "generality" by randomizing dynamics parameters, topology configurations, and model dimensions, which in sequence cover the property, the connection, and the number of robot links. A structure modified from GPT is applied to access the pre-training model of general dynamics. We also study various inverse models of dynamics to facilitate different applications. We step further to investigate a new concept, "Gen2Real", to transfer simulated, general models to physical, specific robots. Simulation and experiment results demonstrate the validity of the proposed models and method.\footnote{ These authors contribute equally.