 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing All-to-X Backdoor Attacks with Optimized Target Class Mapping
Nov 17, 2025



Backdoor attacks pose severe threats to machine learning systems, prompting extensive research in this area. However, most existing work focuses on single-target All-to-One (A2O) attacks, overlooking the more complex All-to-X (A2X) attacks with multiple target classes, which are often assumed to have low attack success rates. In this paper, we first demonstrate that A2X attacks are robust against state-of-the-art defenses. We then propose a novel attack strategy that enhances the success rate of A2X attacks while maintaining robustness by optimizing grouping and target class assignment mechanisms. Our method improves the attack success rate by up to 28%, with average improvements of 6.7%, 16.4%, 14.1% on CIFAR10, CIFAR100, and Tiny-ImageNet, respectively. We anticipate that this study will raise awareness of A2X attacks and stimulate further research in this under-explored area. Our code is available at https://github.com/kazefjj/A2X-backdoor .
Appformer: A Novel Framework for Mobile App Usage Prediction Leveraging Progressive Multi-Modal Data Fusion and Feature Extraction
Jul 28, 2024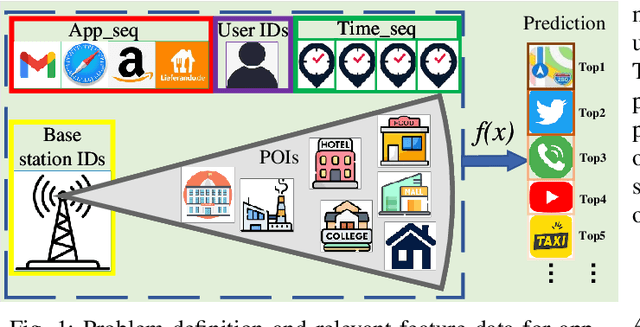
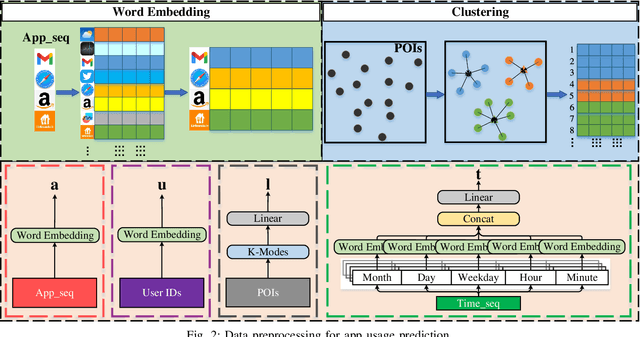
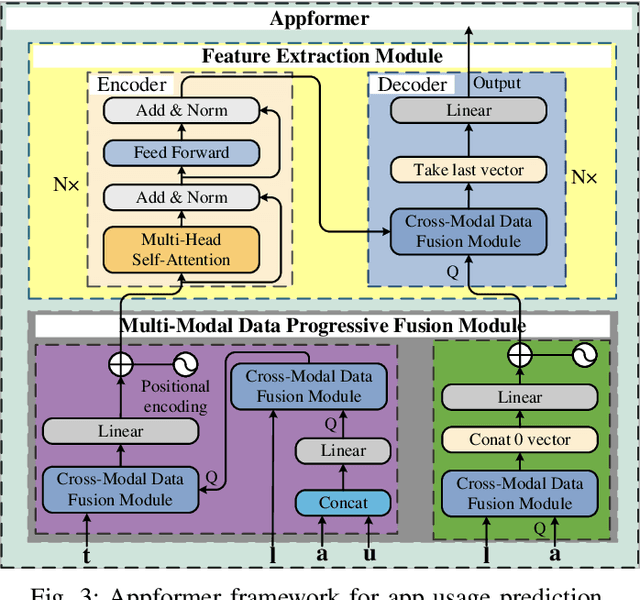
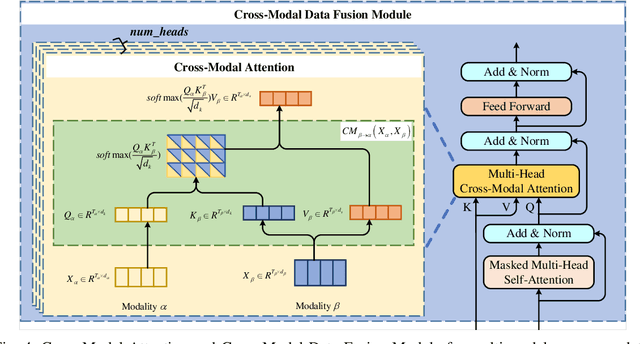
This article presents Appformer, a novel mobile application prediction framework inspired by the efficiency of Transformer-like architectures in processing sequential data through self-attention mechanisms. Combining a Multi-Modal Data Progressive Fusion Module with a sophisticated Feature Extraction Module, Appformer leverages the synergies of multi-modal data fusion and data mining techniques while maintaining user privacy. The framework employs Points of Interest (POIs) associated with base stations, optimizing them through comprehensive comparative experiments to identify the most effective clustering method. These refined inputs are seamlessly integrated into the initial phases of cross-modal data fusion, where temporal units are encoded via word embeddings and subsequently merged in later stages. The Feature Extraction Module, employing Transformer-like architectures specialized for time series analysis, adeptly distils comprehensive features. It meticulously fine-tunes the outputs from the fusion module, facilitating the extraction of high-calibre, multi-modal features, thus guaranteeing a robust and efficient extraction process. Extensive experimental validation confirms Appformer's effectiveness, attaining state-of-the-art (SOTA) metrics in mobile app usage prediction, thereby signifying a notable progression in this field.
MSeg3D: Multi-modal 3D Semantic Segmentation for Autonomous Driving
Mar 15, 2023


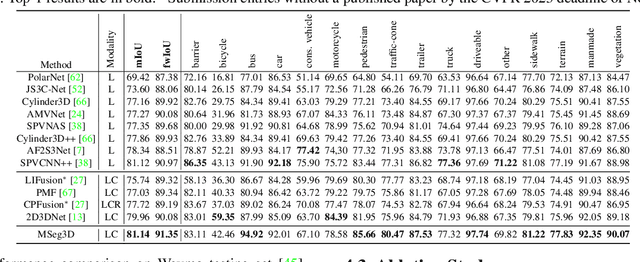
LiDAR and camera are two modalities available for 3D semantic segmentation in autonomous driving. The popular LiDAR-only methods severely suffer from inferior segmentation on small and distant objects due to insufficient laser points, while the robust multi-modal solution is under-explored, where we investigate three crucial inherent difficulties: modality heterogeneity, limited sensor field of view intersection, and multi-modal data augmentation. We propose a multi-modal 3D semantic segmentation model (MSeg3D) with joint intra-modal feature extraction and inter-modal feature fusion to mitigate the modality heterogeneity. The multi-modal fusion in MSeg3D consists of geometry-based feature fusion GF-Phase, cross-modal feature completion, and semantic-based feature fusion SF-Phase on all visible points. The multi-modal data augmentation is reinvigorated by applying asymmetric transformations on LiDAR point cloud and multi-camera images individually, which benefits the model training with diversified augmentation transformations. MSeg3D achieves state-of-the-art results on nuScenes, Waymo, and SemanticKITTI datasets. Under the malfunctioning multi-camera input and the multi-frame point clouds input, MSeg3D still shows robustness and improves the LiDAR-only baseline. Our code is publicly available at \url{https://github.com/jialeli1/lidarseg3d}.
CelebA-Spoof Challenge 2020 on Face Anti-Spoofing: Methods and Results
Feb 26, 2021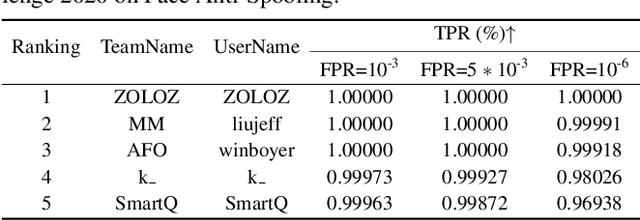
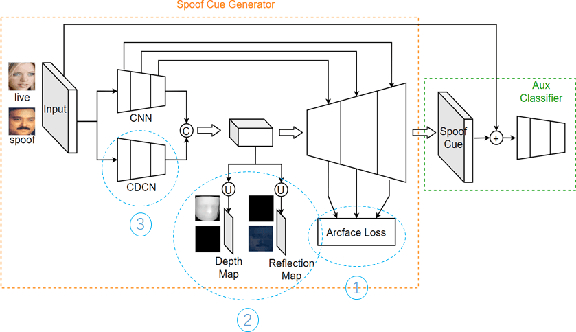
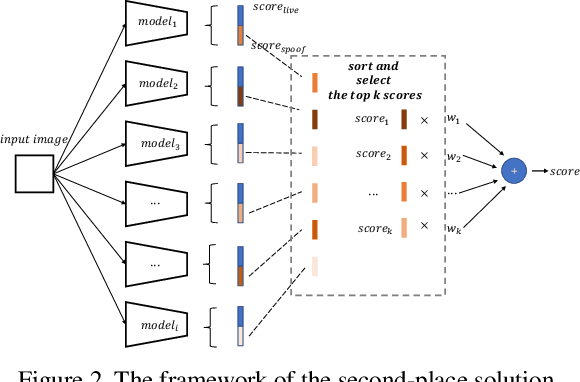
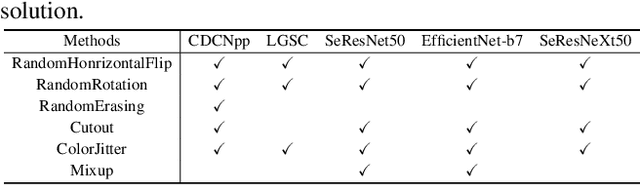
As facial interaction systems are prevalently deployed, security and reliability of these systems become a critical issue, with substantial research efforts devoted. Among them, face anti-spoofing emerges as an important area, whose objective is to identify whether a presented face is live or spoof. Recently, a large-scale face anti-spoofing dataset, CelebA-Spoof which comprised of 625,537 pictures of 10,177 subjects has been released. It is the largest face anti-spoofing dataset in terms of the numbers of the data and the subjects. This paper reports methods and results in the CelebA-Spoof Challenge 2020 on Face AntiSpoofing which employs the CelebA-Spoof dataset. The model evaluation is conducted online on the hidden test set. A total of 134 participants registered for the competition, and 19 teams made valid submissions. We will analyze the top ranked solutions and present some discussion on future work directions.
RCR: Robust Compound Regression for Robust Estimation of Errors-in-Variables Model
Aug 12, 2015
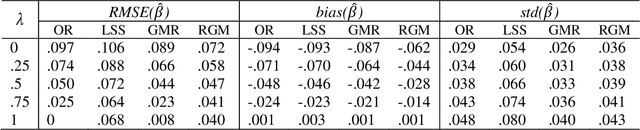
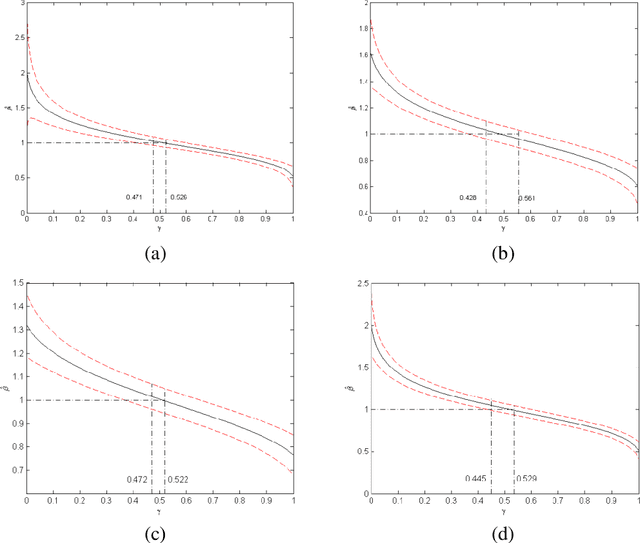
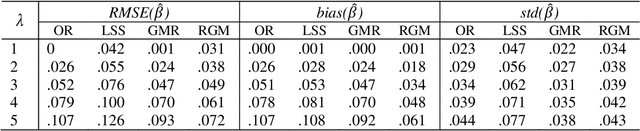
The errors-in-variables (EIV) regression model, being more realistic by accounting for measurement errors in both the dependent and the independent variables, is widely adopted in applied sciences. The traditional EIV model estimators, however, can be highly biased by outliers and other departures from the underlying assumptions. In this paper, we develop a novel nonparametric regression approach - the robust compound regression (RCR) analysis method for the robust estimation of EIV models. We first introduce a robust and efficient estimator called least sine squares (LSS). Taking full advantage of both the new LSS method and the compound regression analysis method developed in our own group, we subsequently propose the RCR approach as a generalization of those two, which provides a robust counterpart of the entire class of the maximum likelihood estimation (MLE) solutions of the EIV model, in a 1-1 mapping. Technically, our approach gives users the flexibility to select from a class of RCR estimates the optimal one with a predefined regression efficiency criterion satisfied. Simulation studies and real-life examples are provided to illustrate the effectiveness of the RCR approach.