 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBCER Agent: Reliable Long-Horizon MRI Workflow Execution via Compilation, Artifact Binding, and Bounded Local Recovery
May 27, 2026Many recent medical VLM and agent studies are benchmarked on 2D images or comparatively short tool-calling exchanges, whereas real MRI analysis typically demands long, interdependent pipelines that operate on 3D/4D volumetric data. Under these conditions, reactive tool-calling agents are prone to cascading breakdowns triggered by faulty intermediate references, mismatched tool arguments, and limited control over cross-step dependencies. To address this, we introduce BCER (Brain-Cerebellum-Extremity-Reflector), a controller architecture aimed at dependable long-horizon MRI workflow execution. BCER decouples high-level planning from execution and provides bounded local recovery. We assess BCER on a multi-organ MRI benchmark covering brain, prostate, and cardiac tasks with both short- and long-chain workflows, using matched task contracts across controller variants and several backbone models. Relative to reactive baselines, BCER yields consistent improvements in end-to-end execution, with the most pronounced gains observed on long-chain workflows. BCER additionally enables auditability by maintaining explicit links between final outputs and intermediate artifacts and measurements. Code and benchmark are released at https://github.com/Albertlongzi/BCER.
WTEFNet: Real-Time Low-Light Object Detection for Advanced Driver-Assistance Systems
May 29, 2025Object detection is a cornerstone of environmental perception in advanced driver assistance systems(ADAS). However, most existing methods rely on RGB cameras, which suffer from significant performance degradation under low-light conditions due to poor image quality. To address this challenge, we proposes WTEFNet, a real-time object detection framework specifically designed for low-light scenarios, with strong adaptability to mainstream detectors. WTEFNet comprises three core modules: a Low-Light Enhancement (LLE) module, a Wavelet-based Feature Extraction (WFE) module, and an Adaptive Fusion Detection (AFFD) module. The LLE enhances dark regions while suppressing overexposed areas; the WFE applies multi-level discrete wavelet transforms to isolate high- and low-frequency components, enabling effective denoising and structural feature retention; the AFFD fuses semantic and illumination features for robust detection. To support training and evaluation, we introduce GSN, a manually annotated dataset covering both clear and rainy night-time scenes. Extensive experiments on BDD100K, SHIFT, nuScenes, and GSN demonstrate that WTEFNet achieves state-of-the-art accuracy under low-light conditions. Furthermore, deployment on a embedded platform (NVIDIA Jetson AGX Orin) confirms the framework's suitability for real-time ADAS applications.
Using Large Language Models to Tackle Fundamental Challenges in Graph Learning: A Comprehensive Survey
May 24, 2025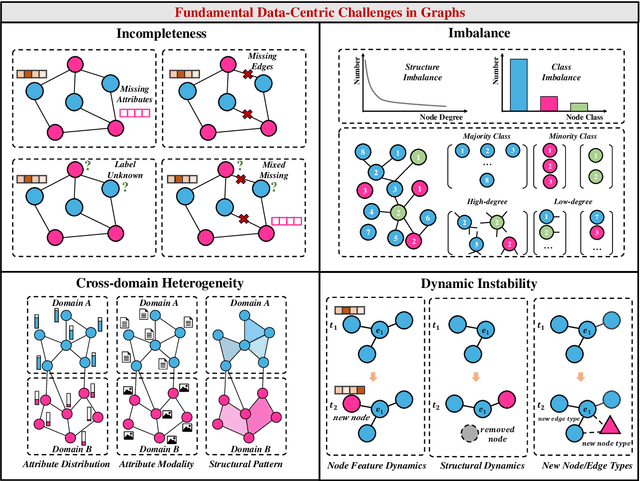
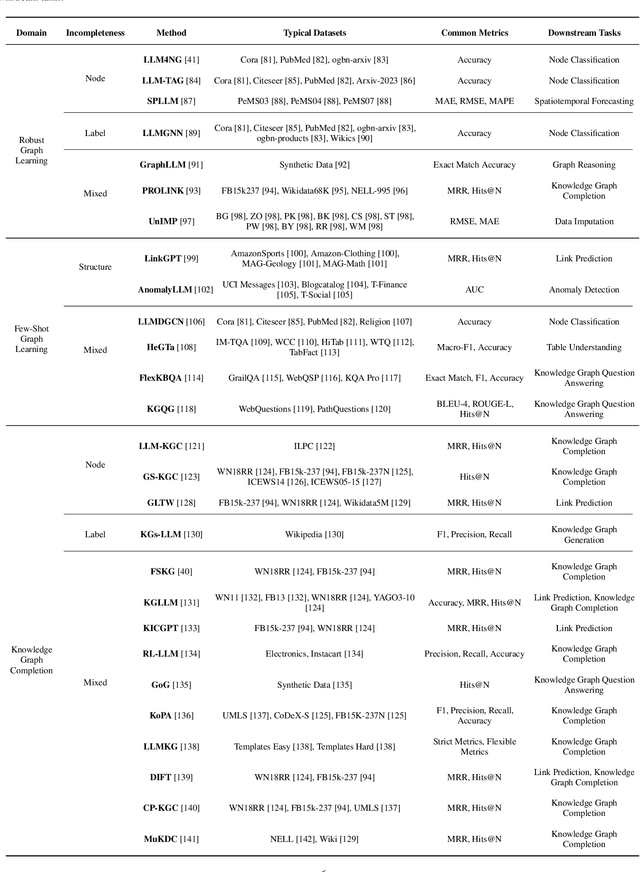
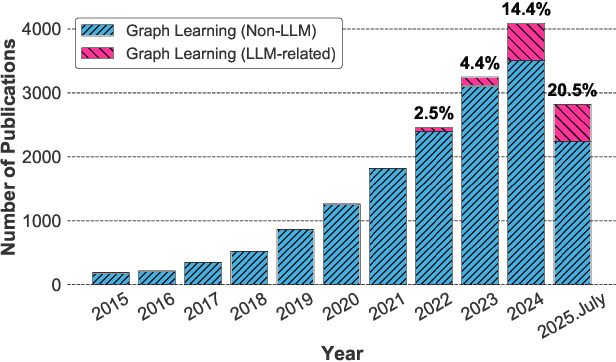
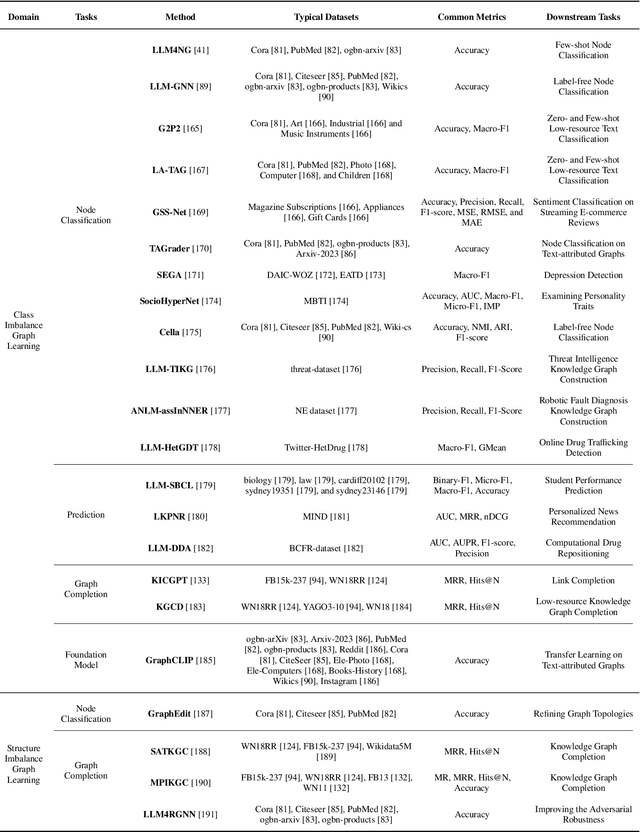
Graphs are a widely used paradigm for representing non-Euclidean data, with applications ranging from social network analysis to biomolecular prediction. Conventional graph learning approaches typically rely on fixed structural assumptions or fully observed data, limiting their effectiveness in more complex, noisy, or evolving settings. Consequently, real-world graph data often violates the assumptions of traditional graph learning methods, in particular, it leads to four fundamental challenges: (1) Incompleteness, real-world graphs have missing nodes, edges, or attributes; (2) Imbalance, the distribution of the labels of nodes or edges and their structures for real-world graphs are highly skewed; (3) Cross-domain Heterogeneity, graphs from different domains exhibit incompatible feature spaces or structural patterns; and (4) Dynamic Instability, graphs evolve over time in unpredictable ways. Recent advances in Large Language Models (LLMs) offer the potential to tackle these challenges by leveraging rich semantic reasoning and external knowledge. This survey provides a comprehensive review of how LLMs can be integrated with graph learning to address the aforementioned challenges. For each challenge, we review both traditional solutions and modern LLM-driven approaches, highlighting how LLMs contribute unique advantages. Finally, we discuss open research questions and promising future directions in this emerging interdisciplinary field. To support further exploration, we have curated a repository of recent advances on graph learning challenges: https://github.com/limengran98/Awesome-Literature-Graph-Learning-Challenges.
MM-STFlowNet: A Transportation Hub-Oriented Multi-Mode Passenger Flow Prediction Method via Spatial-Temporal Dynamic Graph Modeling
Apr 08, 2025Accurate and refined passenger flow prediction is essential for optimizing the collaborative management of multiple collection and distribution modes in large-scale transportation hubs. Traditional methods often focus only on the overall passenger volume, neglecting the interdependence between different modes within the hub. To address this limitation, we propose MM-STFlowNet, a comprehensive multi-mode prediction framework grounded in dynamic spatial-temporal graph modeling. Initially, an integrated temporal feature processing strategy is implemented using signal decomposition and convolution techniques to address data spikes and high volatility. Subsequently, we introduce the Spatial-Temporal Dynamic Graph Convolutional Recurrent Network (STDGCRN) to capture detailed spatial-temporal dependencies across multiple traffic modes, enhanced by an adaptive channel attention mechanism. Finally, the self-attention mechanism is applied to incorporate various external factors, further enhancing prediction accuracy. Experiments on a real-world dataset from Guangzhounan Railway Station in China demonstrate that MM-STFlowNet achieves state-of-the-art performance, particularly during peak periods, providing valuable insight for transportation hub management.
A Robust Real-Time Lane Detection Method with Fog-Enhanced Feature Fusion for Foggy Conditions
Apr 08, 2025Lane detection is a critical component of Advanced Driver Assistance Systems (ADAS). Existing lane detection algorithms generally perform well under favorable weather conditions. However, their performance degrades significantly in adverse conditions, such as fog, which increases the risk of traffic accidents. This challenge is compounded by the lack of specialized datasets and methods designed for foggy environments. To address this, we introduce the FoggyLane dataset, captured in real-world foggy scenarios, and synthesize two additional datasets, FoggyCULane and FoggyTusimple, from existing popular lane detection datasets. Furthermore, we propose a robust Fog-Enhanced Network for lane detection, incorporating a Global Feature Fusion Module (GFFM) to capture global relationships in foggy images, a Kernel Feature Fusion Module (KFFM) to model the structural and positional relationships of lane instances, and a Low-level Edge Enhanced Module (LEEM) to address missing edge details in foggy conditions. Comprehensive experiments demonstrate that our method achieves state-of-the-art performance, with F1-scores of 95.04 on FoggyLane, 79.85 on FoggyCULane, and 96.95 on FoggyTusimple. Additionally, with TensorRT acceleration, the method reaches a processing speed of 38.4 FPS on the NVIDIA Jetson AGX Orin, confirming its real-time capabilities and robustness in foggy environments.
ABCDWaveNet: Advancing Robust Road Ponding Detection in Fog through Dynamic Frequency-Spatial Synergy
Apr 07, 2025Road ponding presents a significant threat to vehicle safety, particularly in adverse fog conditions, where reliable detection remains a persistent challenge for Advanced Driver Assistance Systems (ADAS). To address this, we propose ABCDWaveNet, a novel deep learning framework leveraging Dynamic Frequency-Spatial Synergy for robust ponding detection in fog. The core of ABCDWaveNet achieves this synergy by integrating dynamic convolution for adaptive feature extraction across varying visibilities with a wavelet-based module for synergistic frequency-spatial feature enhancement, significantly improving robustness against fog interference. Building on this foundation, ABCDWaveNet captures multi-scale structural and contextual information, subsequently employing an Adaptive Attention Coupling Gate (AACG) to adaptively fuse global and local features for enhanced accuracy. To facilitate realistic evaluations under combined adverse conditions, we introduce the Foggy Low-Light Puddle dataset. Extensive experiments demonstrate that ABCDWaveNet establishes new state-of-the-art performance, achieving significant Intersection over Union (IoU) gains of 3.51%, 1.75%, and 1.03% on the Foggy-Puddle, Puddle-1000, and our Foggy Low-Light Puddle datasets, respectively. Furthermore, its processing speed of 25.48 FPS on an NVIDIA Jetson AGX Orin confirms its suitability for ADAS deployment. These findings underscore the effectiveness of the proposed Dynamic Frequency-Spatial Synergy within ABCDWaveNet, offering valuable insights for developing proactive road safety solutions capable of operating reliably in challenging weather conditions.
YOLO-LLTS: Real-Time Low-Light Traffic Sign Detection via Prior-Guided Enhancement and Multi-Branch Feature Interaction
Mar 18, 2025Detecting traffic signs effectively under low-light conditions remains a significant challenge. To address this issue, we propose YOLO-LLTS, an end-to-end real-time traffic sign detection algorithm specifically designed for low-light environments. Firstly, we introduce the High-Resolution Feature Map for Small Object Detection (HRFM-TOD) module to address indistinct small-object features in low-light scenarios. By leveraging high-resolution feature maps, HRFM-TOD effectively mitigates the feature dilution problem encountered in conventional PANet frameworks, thereby enhancing both detection accuracy and inference speed. Secondly, we develop the Multi-branch Feature Interaction Attention (MFIA) module, which facilitates deep feature interaction across multiple receptive fields in both channel and spatial dimensions, significantly improving the model's information extraction capabilities. Finally, we propose the Prior-Guided Enhancement Module (PGFE) to tackle common image quality challenges in low-light environments, such as noise, low contrast, and blurriness. This module employs prior knowledge to enrich image details and enhance visibility, substantially boosting detection performance. To support this research, we construct a novel dataset, the Chinese Nighttime Traffic Sign Sample Set (CNTSSS), covering diverse nighttime scenarios, including urban, highway, and rural environments under varying weather conditions. Experimental evaluations demonstrate that YOLO-LLTS achieves state-of-the-art performance, outperforming the previous best methods by 2.7% mAP50 and 1.6% mAP50:95 on TT100K-night, 1.3% mAP50 and 1.9% mAP50:95 on CNTSSS, and achieving superior results on the CCTSDB2021 dataset. Moreover, deployment experiments on edge devices confirm the real-time applicability and effectiveness of our proposed approach.
Topology-Driven Attribute Recovery for Attribute Missing Graph Learning in Social Internet of Things
Jan 17, 2025



With the advancement of information technology, the Social Internet of Things (SIoT) has fostered the integration of physical devices and social networks, deepening the study of complex interaction patterns. Text Attribute Graphs (TAGs) capture both topological structures and semantic attributes, enhancing the analysis of complex interactions within the SIoT. However, existing graph learning methods are typically designed for complete attributed graphs, and the common issue of missing attributes in Attribute Missing Graphs (AMGs) increases the difficulty of analysis tasks. To address this, we propose the Topology-Driven Attribute Recovery (TDAR) framework, which leverages topological data for AMG learning. TDAR introduces an improved pre-filling method for initial attribute recovery using native graph topology. Additionally, it dynamically adjusts propagation weights and incorporates homogeneity strategies within the embedding space to suit AMGs' unique topological structures, effectively reducing noise during information propagation. Extensive experiments on public datasets demonstrate that TDAR significantly outperforms state-of-the-art methods in attribute reconstruction and downstream tasks, offering a robust solution to the challenges posed by AMGs. The code is available at https://github.com/limengran98/TDAR.
AttriReBoost: A Gradient-Free Propagation Optimization Method for Cold Start Mitigation in Attribute Missing Graphs
Jan 01, 2025



Missing attribute issues are prevalent in the graph learning, leading to biased outcomes in Graph Neural Networks (GNNs). Existing methods that rely on feature propagation are prone to cold start problem, particularly when dealing with attribute resetting and low-degree nodes, which hinder effective propagation and convergence. To address these challenges, we propose AttriReBoost (ARB), a novel method that incorporates propagation-based method to mitigate cold start problems in attribute-missing graphs. ARB enhances global feature propagation by redefining initial boundary conditions and strategically integrating virtual edges, thereby improving node connectivity and ensuring more stable and efficient convergence. This method facilitates gradient-free attribute reconstruction with lower computational overhead. The proposed method is theoretically grounded, with its convergence rigorously established. Extensive experiments on several real-world benchmark datasets demonstrate the effectiveness of ARB, achieving an average accuracy improvement of 5.11% over state-of-the-art methods. Additionally, ARB exhibits remarkable computational efficiency, processing a large-scale graph with 2.49 million nodes in just 16 seconds on a single GPU. Our code is available at https://github.com/limengran98/ARB.
TAS-TsC: A Data-Driven Framework for Estimating Time of Arrival Using Temporal-Attribute-Spatial Tri-space Coordination of Truck Trajectories
Dec 02, 2024



Accurately estimating time of arrival (ETA) for trucks is crucial for optimizing transportation efficiency in logistics. GPS trajectory data offers valuable information for ETA, but challenges arise due to temporal sparsity, variable sequence lengths, and the interdependencies among multiple trucks. To address these issues, we propose the Temporal-Attribute-Spatial Tri-space Coordination (TAS-TsC) framework, which leverages three feature spaces-temporal, attribute, and spatial-to enhance ETA. Our framework consists of a Temporal Learning Module (TLM) using state space models to capture temporal dependencies, an Attribute Extraction Module (AEM) that transforms sequential features into structured attribute embeddings, and a Spatial Fusion Module (SFM) that models the interactions among multiple trajectories using graph representation learning.These modules collaboratively learn trajectory embeddings, which are then used by a Downstream Prediction Module (DPM) to estimate arrival times. We validate TAS-TsC on real truck trajectory datasets collected from Shenzhen, China, demonstrating its superior performance compared to existing methods.