 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCiQi-Agent: Aligning Vision, Tools and Aesthetics in Multimodal Agent for Cultural Reasoning on Chinese Porcelains
Mar 30, 2026The connoisseurship of antique Chinese porcelain demands extensive historical expertise, material understanding, and aesthetic sensitivity, making it difficult for non-specialists to engage. To democratize cultural-heritage understanding and assist expert connoisseurship, we introduce CiQi-Agent -- a domain-specific Porcelain Connoisseurship Agent for intelligent analysis of antique Chinese porcelain. CiQi-Agent supports multi-image porcelain inputs and enables vision tool invocation and multimodal retrieval-augmented generation, performing fine-grained connoisseurship analysis across six attributes: dynasty, reign period, kiln site, glaze color, decorative motif, and vessel shape. Beyond attribute classification, it captures subtle visual details, retrieves relevant domain knowledge, and integrates visual and textual evidence to produce coherent, explainable connoisseurship descriptions. To achieve this capability, we construct a large-scale, expert-annotated dataset CiQi-VQA, comprising 29,596 porcelain specimens, 51,553 images, and 557,940 visual question--answering pairs, and further establish a comprehensive benchmark CiQi-Bench aligned with the previously mentioned six attributes. CiQi-Agent is trained through supervised fine-tuning, reinforcement learning, and a tool-augmented reasoning framework that integrates two categories of tools: a vision tool and multimodal retrieval tools. Experimental results show that CiQi-Agent (7B) outperforms all competitive open- and closed-source models across all six attributes on CiQi-Bench, achieving on average 12.2\% higher accuracy than GPT-5. The model and dataset have been released and are publicly available at https://huggingface.co/datasets/SII-Monument-Valley/CiQi-VQA.
TriC-Motion: Tri-Domain Causal Modeling Grounded Text-to-Motion Generation
Feb 09, 2026Text-to-motion generation, a rapidly evolving field in computer vision, aims to produce realistic and text-aligned motion sequences. Current methods primarily focus on spatial-temporal modeling or independent frequency domain analysis, lacking a unified framework for joint optimization across spatial, temporal, and frequency domains. This limitation hinders the model's ability to leverage information from all domains simultaneously, leading to suboptimal generation quality. Additionally, in motion generation frameworks, motion-irrelevant cues caused by noise are often entangled with features that contribute positively to generation, thereby leading to motion distortion. To address these issues, we propose Tri-Domain Causal Text-to-Motion Generation (TriC-Motion), a novel diffusion-based framework integrating spatial-temporal-frequency-domain modeling with causal intervention. TriC-Motion includes three core modeling modules for domain-specific modeling, namely Temporal Motion Encoding, Spatial Topology Modeling, and Hybrid Frequency Analysis. After comprehensive modeling, a Score-guided Tri-domain Fusion module integrates valuable information from the triple domains, simultaneously ensuring temporal consistency, spatial topology, motion trends, and dynamics. Moreover, the Causality-based Counterfactual Motion Disentangler is meticulously designed to expose motion-irrelevant cues to eliminate noise, disentangling the real modeling contributions of each domain for superior generation. Extensive experimental results validate that TriC-Motion achieves superior performance compared to state-of-the-art methods, attaining an outstanding R@1 of 0.612 on the HumanML3D dataset. These results demonstrate its capability to generate high-fidelity, coherent, diverse, and text-aligned motion sequences. Code is available at: https://caoyiyang1105.github.io/TriC-Motion/.
A Robust Real-Time Lane Detection Method with Fog-Enhanced Feature Fusion for Foggy Conditions
Apr 08, 2025Lane detection is a critical component of Advanced Driver Assistance Systems (ADAS). Existing lane detection algorithms generally perform well under favorable weather conditions. However, their performance degrades significantly in adverse conditions, such as fog, which increases the risk of traffic accidents. This challenge is compounded by the lack of specialized datasets and methods designed for foggy environments. To address this, we introduce the FoggyLane dataset, captured in real-world foggy scenarios, and synthesize two additional datasets, FoggyCULane and FoggyTusimple, from existing popular lane detection datasets. Furthermore, we propose a robust Fog-Enhanced Network for lane detection, incorporating a Global Feature Fusion Module (GFFM) to capture global relationships in foggy images, a Kernel Feature Fusion Module (KFFM) to model the structural and positional relationships of lane instances, and a Low-level Edge Enhanced Module (LEEM) to address missing edge details in foggy conditions. Comprehensive experiments demonstrate that our method achieves state-of-the-art performance, with F1-scores of 95.04 on FoggyLane, 79.85 on FoggyCULane, and 96.95 on FoggyTusimple. Additionally, with TensorRT acceleration, the method reaches a processing speed of 38.4 FPS on the NVIDIA Jetson AGX Orin, confirming its real-time capabilities and robustness in foggy environments.
YOLO-LLTS: Real-Time Low-Light Traffic Sign Detection via Prior-Guided Enhancement and Multi-Branch Feature Interaction
Mar 18, 2025Detecting traffic signs effectively under low-light conditions remains a significant challenge. To address this issue, we propose YOLO-LLTS, an end-to-end real-time traffic sign detection algorithm specifically designed for low-light environments. Firstly, we introduce the High-Resolution Feature Map for Small Object Detection (HRFM-TOD) module to address indistinct small-object features in low-light scenarios. By leveraging high-resolution feature maps, HRFM-TOD effectively mitigates the feature dilution problem encountered in conventional PANet frameworks, thereby enhancing both detection accuracy and inference speed. Secondly, we develop the Multi-branch Feature Interaction Attention (MFIA) module, which facilitates deep feature interaction across multiple receptive fields in both channel and spatial dimensions, significantly improving the model's information extraction capabilities. Finally, we propose the Prior-Guided Enhancement Module (PGFE) to tackle common image quality challenges in low-light environments, such as noise, low contrast, and blurriness. This module employs prior knowledge to enrich image details and enhance visibility, substantially boosting detection performance. To support this research, we construct a novel dataset, the Chinese Nighttime Traffic Sign Sample Set (CNTSSS), covering diverse nighttime scenarios, including urban, highway, and rural environments under varying weather conditions. Experimental evaluations demonstrate that YOLO-LLTS achieves state-of-the-art performance, outperforming the previous best methods by 2.7% mAP50 and 1.6% mAP50:95 on TT100K-night, 1.3% mAP50 and 1.9% mAP50:95 on CNTSSS, and achieving superior results on the CCTSDB2021 dataset. Moreover, deployment experiments on edge devices confirm the real-time applicability and effectiveness of our proposed approach.
Predictive Lagrangian Optimization for Constrained Reinforcement Learning
Jan 25, 2025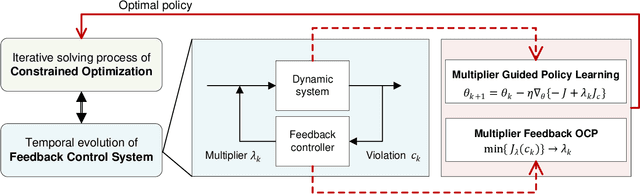
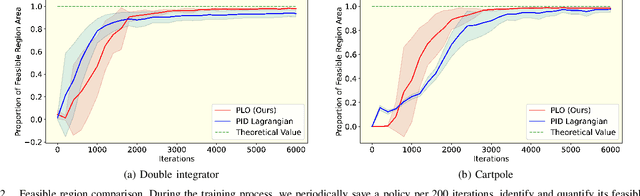
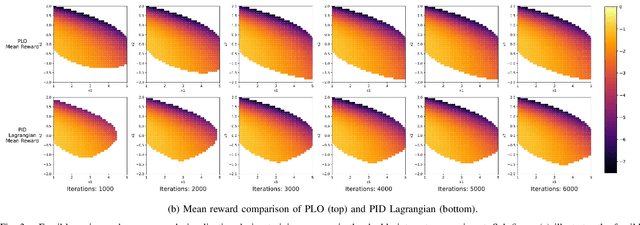

Constrained optimization is popularly seen in reinforcement learning for addressing complex control tasks. From the perspective of dynamic system, iteratively solving a constrained optimization problem can be framed as the temporal evolution of a feedback control system. Classical constrained optimization methods, such as penalty and Lagrangian approaches, inherently use proportional and integral feedback controllers. In this paper, we propose a more generic equivalence framework to build the connection between constrained optimization and feedback control system, for the purpose of developing more effective constrained RL algorithms. Firstly, we define that each step of the system evolution determines the Lagrange multiplier by solving a multiplier feedback optimal control problem (MFOCP). In this problem, the control input is multiplier, the state is policy parameters, the dynamics is described by policy gradient descent, and the objective is to minimize constraint violations. Then, we introduce a multiplier guided policy learning (MGPL) module to perform policy parameters updating. And we prove that the resulting optimal policy, achieved through alternating MFOCP and MGPL, aligns with the solution of the primal constrained RL problem, thereby establishing our equivalence framework. Furthermore, we point out that the existing PID Lagrangian is merely one special case within our framework that utilizes a PID controller. We also accommodate the integration of other various feedback controllers, thereby facilitating the development of new algorithms. As a representative, we employ model predictive control (MPC) as the feedback controller and consequently propose a new algorithm called predictive Lagrangian optimization (PLO). Numerical experiments demonstrate its superiority over the PID Lagrangian method, achieving a larger feasible region up to 7.2% and a comparable average reward.
SCoTTi: Save Computation at Training Time with an adaptive framework
Dec 19, 2023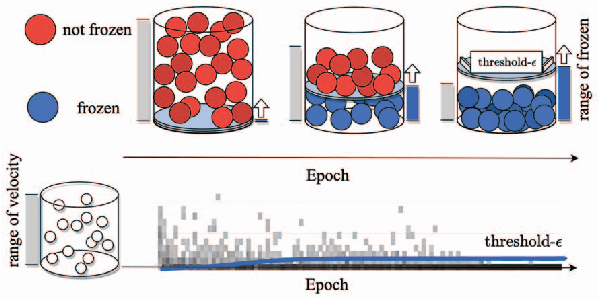
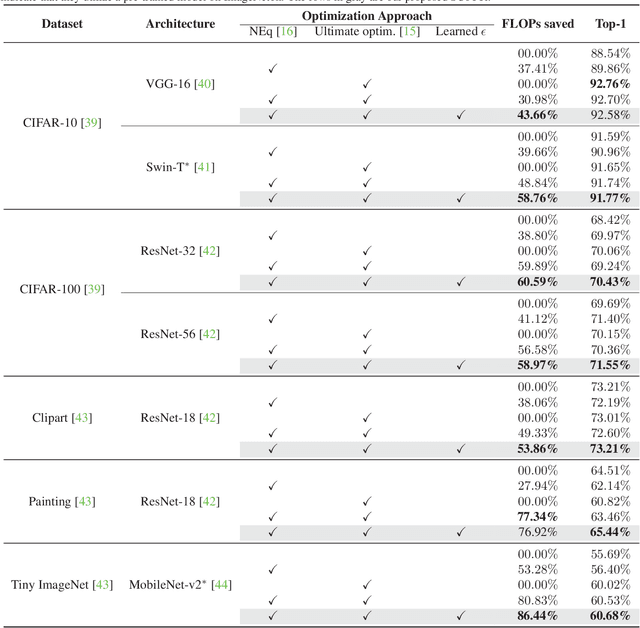
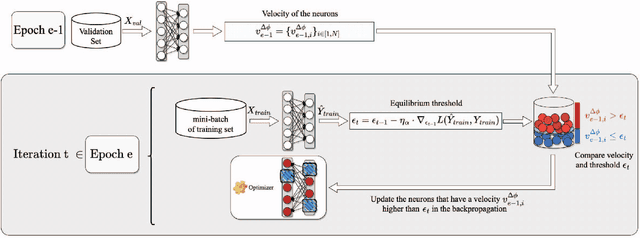
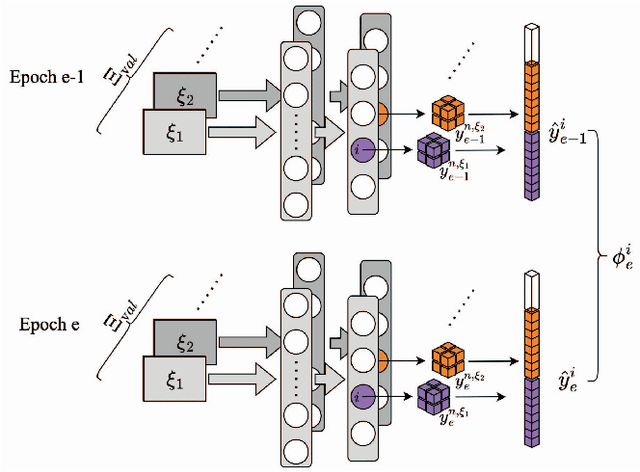
On-device training is an emerging approach in machine learning where models are trained on edge devices, aiming to enhance privacy protection and real-time performance. However, edge devices typically possess restricted computational power and resources, making it challenging to perform computationally intensive model training tasks. Consequently, reducing resource consumption during training has become a pressing concern in this field. To this end, we propose SCoTTi (Save Computation at Training Time), an adaptive framework that addresses the aforementioned challenge. It leverages an optimizable threshold parameter to effectively reduce the number of neuron updates during training which corresponds to a decrease in memory and computation footprint. Our proposed approach demonstrates superior performance compared to the state-of-the-art methods regarding computational resource savings on various commonly employed benchmarks and popular architectures, including ResNets, MobileNet, and Swin-T.
Fixed-Dimensional and Permutation Invariant State Representation of Autonomous Driving
May 24, 2021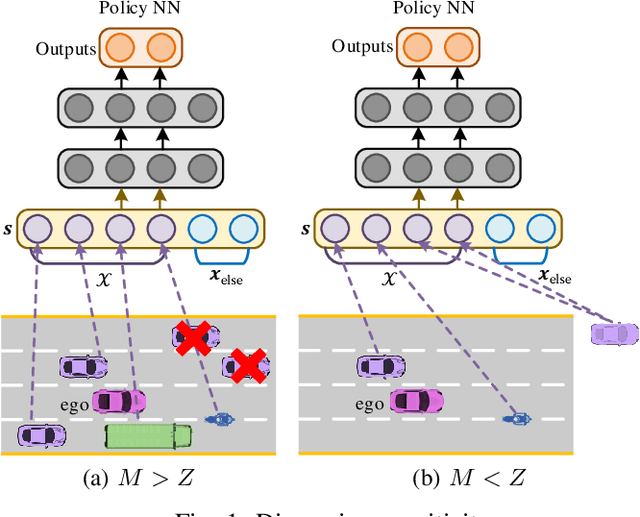
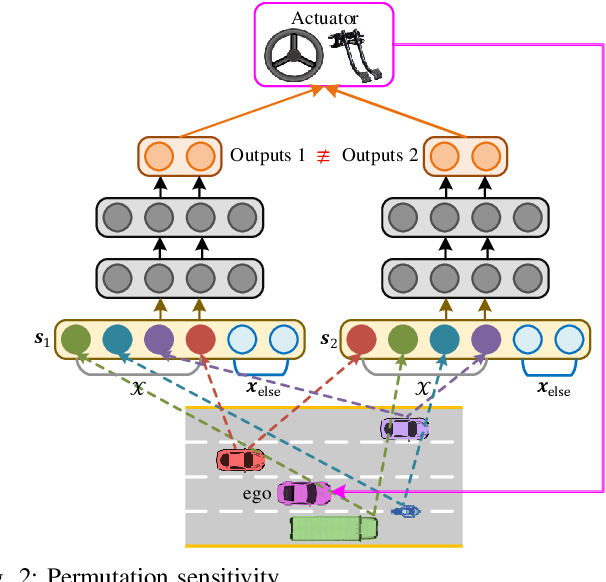
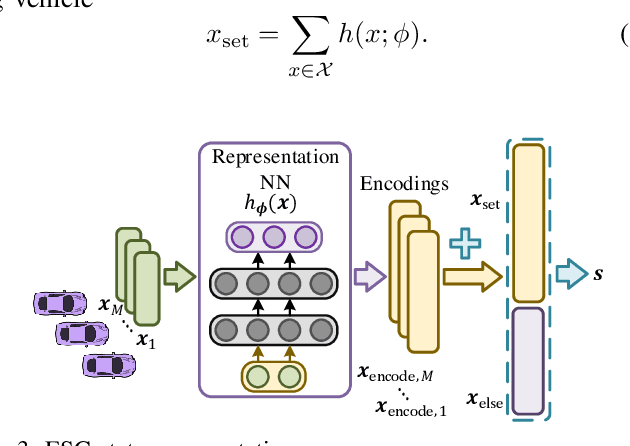
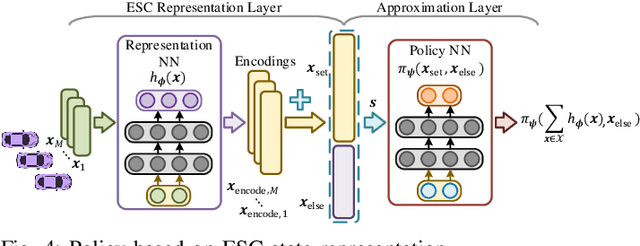
In this paper, we propose a new state representation method, called encoding sum and concatenation (ESC), for the state representation of decision-making in autonomous driving. Unlike existing state representation methods, ESC is applicable to a variable number of surrounding vehicles and eliminates the need for manually pre-designed sorting rules, leading to higher representation ability and generality. The proposed ESC method introduces a representation neural network (NN) to encode each surrounding vehicle into an encoding vector, and then adds these vectors to obtain the representation vector of the set of surrounding vehicles. By concatenating the set representation with other variables, such as indicators of the ego vehicle and road, we realize the fixed-dimensional and permutation invariant state representation. This paper has further proved that the proposed ESC method can realize the injective representation if the output dimension of the representation NN is greater than the number of variables of all surrounding vehicles. This means that by taking the ESC representation as policy inputs, we can find the nearly optimal representation NN and policy NN by simultaneously optimizing them using gradient-based updating. Experiments demonstrate that compared with the fixed-permutation representation method, the proposed method improves the representation ability of the surrounding vehicles, and the corresponding approximation error is reduced by 62.2%.
Model-based Constrained Reinforcement Learning using Generalized Control Barrier Function
Mar 05, 2021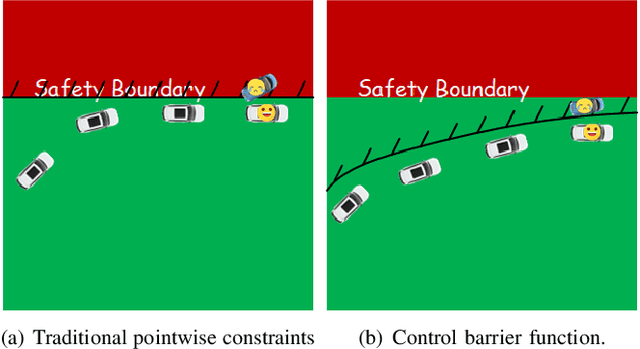
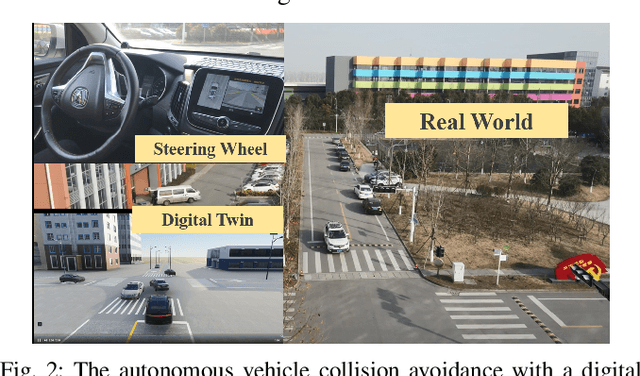
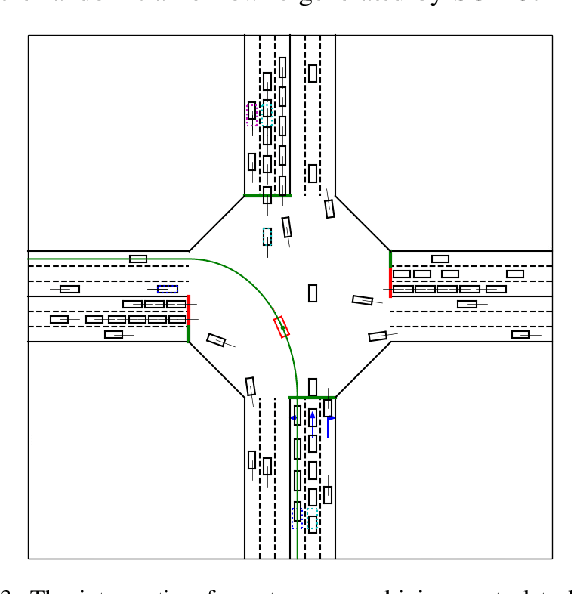
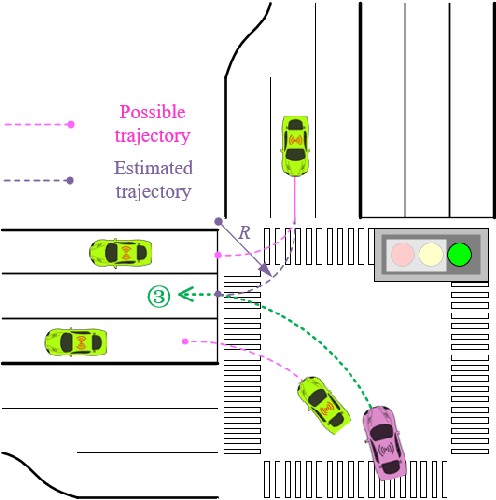
Model information can be used to predict future trajectories, so it has huge potential to avoid dangerous region when implementing reinforcement learning (RL) on real-world tasks, like autonomous driving. However, existing studies mostly use model-free constrained RL, which causes inevitable constraint violations. This paper proposes a model-based feasibility enhancement technique of constrained RL, which enhances the feasibility of policy using generalized control barrier function (GCBF) defined on the distance to constraint boundary. By using the model information, the policy can be optimized safely without violating actual safety constraints, and the sample efficiency is increased. The major difficulty of infeasibility in solving the constrained policy gradient is handled by an adaptive coefficient mechanism. We evaluate the proposed method in both simulations and real vehicle experiments in a complex autonomous driving collision avoidance task. The proposed method achieves up to four times fewer constraint violations and converges 3.36 times faster than baseline constrained RL approaches.
Recurrent Model Predictive Control
Feb 23, 2021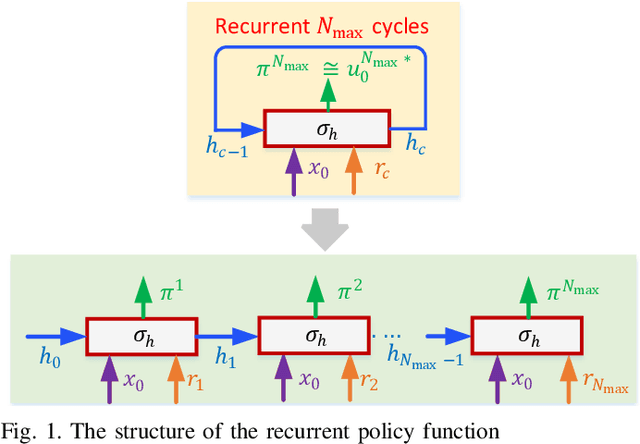



This paper proposes an off-line algorithm, called Recurrent Model Predictive Control (RMPC), to solve general nonlinear finite-horizon optimal control problems. Unlike traditional Model Predictive Control (MPC) algorithms, it can make full use of the current computing resources and adaptively select the longest model prediction horizon. Our algorithm employs a recurrent function to approximate the optimal policy, which maps the system states and reference values directly to the control inputs. The number of prediction steps is equal to the number of recurrent cycles of the learned policy function. With an arbitrary initial policy function, the proposed RMPC algorithm can converge to the optimal policy by directly minimizing the designed loss function. We further prove the convergence and optimality of the RMPC algorithm thorough Bellman optimality principle, and demonstrate its generality and efficiency using two numerical examples.