 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHFMCA: Orthonormal Feature Learning for EEG-based Brain Decoding
Feb 04, 2026Electroencephalography (EEG) analysis is critical for brain-computer interfaces and neuroscience, but the intrinsic noise and high dimensionality of EEG signals hinder effective feature learning. We propose a self-supervised framework based on the Hierarchical Functional Maximal Correlation Algorithm (HFMCA), which learns orthonormal EEG representations by enforcing feature decorrelation and reducing redundancy. This design enables robust capture of essential brain dynamics for various EEG recognition tasks. We validate HFMCA on two benchmark datasets, SEED and BCIC-2A, where pretraining with HFMCA consistently outperforms competitive self-supervised baselines, achieving notable gains in classification accuracy. Across diverse EEG tasks, our method demonstrates superior cross-subject generalization under leave-one-subject-out validation, advancing state-of-the-art by 2.71\% on SEED emotion recognition and 2.57\% on BCIC-2A motor imagery classification.
Nix and Fix: Targeting 1000x Compression of 3D Gaussian Splatting with Diffusion Models
Feb 04, 20263D Gaussian Splatting (3DGS) revolutionized novel view rendering. Instead of inferring from dense spatial points, as implicit representations do, 3DGS uses sparse Gaussians. This enables real-time performance but increases space requirements, hindering applications such as immersive communication. 3DGS compression emerged as a field aimed at alleviating this issue. While impressive progress has been made, at low rates, compression introduces artifacts that degrade visual quality significantly. We introduce NiFi, a method for extreme 3DGS compression through restoration via artifact-aware, diffusion-based one-step distillation. We show that our method achieves state-of-the-art perceptual quality at extremely low rates, down to 0.1 MB, and towards 1000x rate improvement over 3DGS at comparable perceptual performance. The code will be open-sourced upon acceptance.
How I Met Your Bias: Investigating Bias Amplification in Diffusion Models
Dec 23, 2025Diffusion-based generative models demonstrate state-of-the-art performance across various image synthesis tasks, yet their tendency to replicate and amplify dataset biases remains poorly understood. Although previous research has viewed bias amplification as an inherent characteristic of diffusion models, this work provides the first analysis of how sampling algorithms and their hyperparameters influence bias amplification. We empirically demonstrate that samplers for diffusion models -- commonly optimized for sample quality and speed -- have a significant and measurable effect on bias amplification. Through controlled studies with models trained on Biased MNIST, Multi-Color MNIST and BFFHQ, and with Stable Diffusion, we show that sampling hyperparameters can induce both bias reduction and amplification, even when the trained model is fixed. Source code is available at https://github.com/How-I-met-your-bias/how_i_met_your_bias.
Beyond Low-rank Decomposition: A Shortcut Approach for Efficient On-Device Learning
May 08, 2025On-device learning has emerged as a promising direction for AI development, particularly because of its potential to reduce latency issues and mitigate privacy risks associated with device-server communication, while improving energy efficiency. Despite these advantages, significant memory and computational constraints still represent major challenges for its deployment. Drawing on previous studies on low-rank decomposition methods that address activation memory bottlenecks in backpropagation, we propose a novel shortcut approach as an alternative. Our analysis and experiments demonstrate that our method can reduce activation memory usage, even up to $120.09\times$ compared to vanilla training, while also reducing overall training FLOPs up to $1.86\times$ when evaluated on traditional benchmarks.
I-INR: Iterative Implicit Neural Representations
Apr 24, 2025Implicit Neural Representations (INRs) have revolutionized signal processing and computer vision by modeling signals as continuous, differentiable functions parameterized by neural networks. However, their inherent formulation as a regression problem makes them prone to regression to the mean, limiting their ability to capture fine details, retain high-frequency information, and handle noise effectively. To address these challenges, we propose Iterative Implicit Neural Representations (I-INRs) a novel plug-and-play framework that enhances signal reconstruction through an iterative refinement process. I-INRs effectively recover high-frequency details, improve robustness to noise, and achieve superior reconstruction quality. Our framework seamlessly integrates with existing INR architectures, delivering substantial performance gains across various tasks. Extensive experiments show that I-INRs outperform baseline methods, including WIRE, SIREN, and Gauss, in diverse computer vision applications such as image restoration, image denoising, and object occupancy prediction.
Efficient Adaptation of Deep Neural Networks for Semantic Segmentation in Space Applications
Apr 22, 2025In recent years, the application of Deep Learning techniques has shown remarkable success in various computer vision tasks, paving the way for their deployment in extraterrestrial exploration. Transfer learning has emerged as a powerful strategy for addressing the scarcity of labeled data in these novel environments. This paper represents one of the first efforts in evaluating the feasibility of employing adapters toward efficient transfer learning for rock segmentation in extraterrestrial landscapes, mainly focusing on lunar and martian terrains. Our work suggests that the use of adapters, strategically integrated into a pre-trained backbone model, can be successful in reducing both bandwidth and memory requirements for the target extraterrestrial device. In this study, we considered two memory-saving strategies: layer fusion (to reduce to zero the inference overhead) and an ``adapter ranking'' (to also reduce the transmission cost). Finally, we evaluate these results in terms of task performance, memory, and computation on embedded devices, evidencing trade-offs that open the road to more research in the field.
RD Efficient FPGA Deployment of Learned Image Compression: Knowledge Distillation and Hybrid Quantization
Mar 05, 2025



Learnable Image Compression (LIC) has shown the potential to outperform standardized video codecs in RD efficiency, prompting the research for hardware-friendly implementations. Most existing LIC hardware implementations prioritize latency to RD-efficiency and through an extensive exploration of the hardware design space. We present a novel design paradigm where the burden of tuning the design for a specific hardware platform is shifted towards model dimensioning and without compromising on RD-efficiency. First, we design a framework for distilling a leaner student LIC model from a reference teacher: by tuning a single model hyperparameters, we can meet the constraints of different hardware platforms without a complex hardware design exploration. Second, we propose a hardware-friendly implementation of the Generalized Divisive Normalization (GDN) activation that preserves RD efficiency even post parameter quantization. Third, we design a pipelined FPGA configuration which takes full advantage of available FPGA resources by leveraging parallel processing and optimizing resource allocation. Our experiments with a state of the art LIC model show that we outperform all existing FPGA implementations while performing very close to the original model in terms of RD efficiency.
Diffusing DeBias: a Recipe for Turning a Bug into a Feature
Feb 13, 2025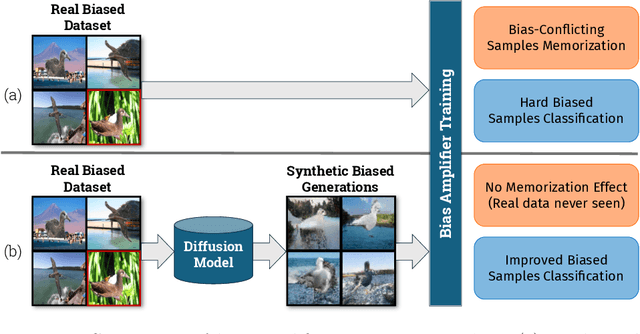
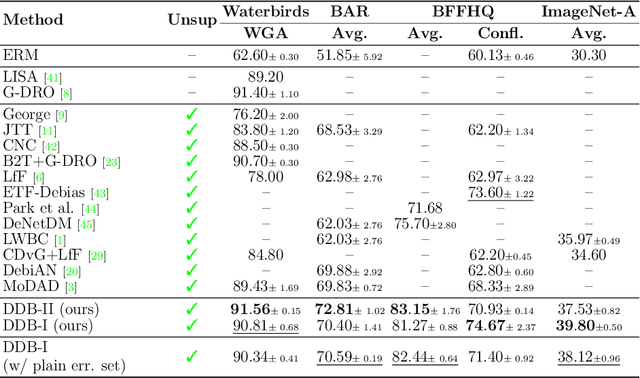
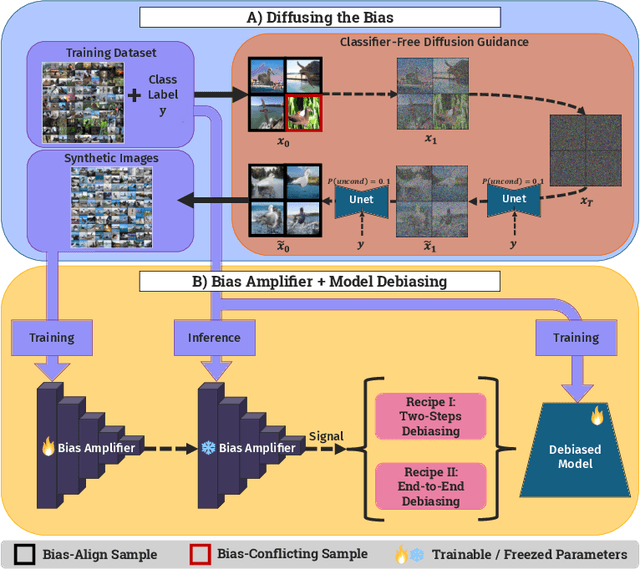

Deep learning model effectiveness in classification tasks is often challenged by the quality and quantity of training data which, whenever containing strong spurious correlations between specific attributes and target labels, can result in unrecoverable biases in model predictions. Tackling these biases is crucial in improving model generalization and trust, especially in real-world scenarios. This paper presents Diffusing DeBias (DDB), a novel approach acting as a plug-in for common methods in model debiasing while exploiting the inherent bias-learning tendency of diffusion models. Our approach leverages conditional diffusion models to generate synthetic bias-aligned images, used to train a bias amplifier model, to be further employed as an auxiliary method in different unsupervised debiasing approaches. Our proposed method, which also tackles the common issue of training set memorization typical of this type of tech- niques, beats current state-of-the-art in multiple benchmark datasets by significant margins, demonstrating its potential as a versatile and effective tool for tackling dataset bias in deep learning applications.
No Images, No Problem: Retaining Knowledge in Continual VQA with Questions-Only Memory
Feb 06, 2025Continual Learning in Visual Question Answering (VQACL) requires models to learn new visual-linguistic tasks (plasticity) while retaining knowledge from previous tasks (stability). The multimodal nature of VQACL presents unique challenges, requiring models to balance stability across visual and textual domains while maintaining plasticity to adapt to novel objects and reasoning tasks. Existing methods, predominantly designed for unimodal tasks, often struggle to balance these demands effectively. In this work, we introduce QUestion-only replay with Attention Distillation (QUAD), a novel approach for VQACL that leverages only past task questions for regularisation, eliminating the need to store visual data and addressing both memory and privacy concerns. QUAD achieves stability by introducing a question-only replay mechanism that selectively uses questions from previous tasks to prevent overfitting to the current task's answer space, thereby mitigating the out-of-answer-set problem. Complementing this, we propose attention consistency distillation, which uniquely enforces both intra-modal and inter-modal attention consistency across tasks, preserving essential visual-linguistic associations. Extensive experiments on VQAv2 and NExT-QA demonstrate that QUAD significantly outperforms state-of-the-art methods, achieving robust performance in continual VQA.
FOLDER: Accelerating Multi-modal Large Language Models with Enhanced Performance
Jan 05, 2025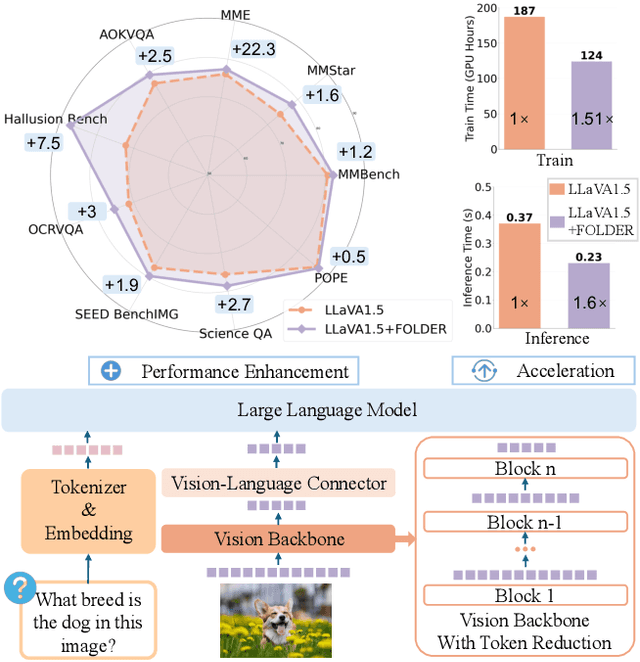
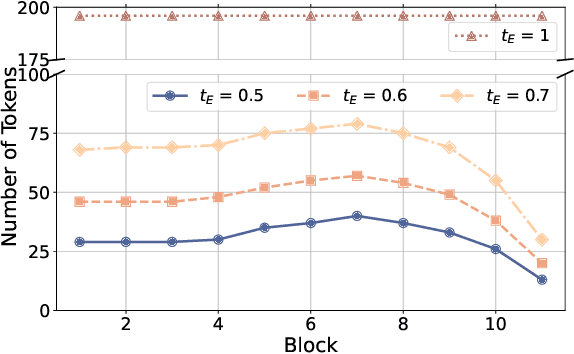
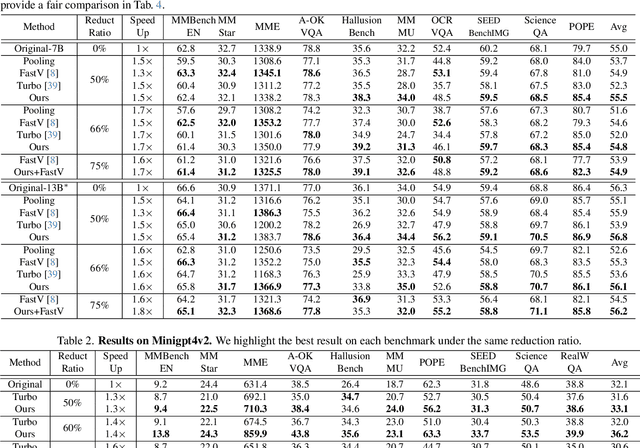
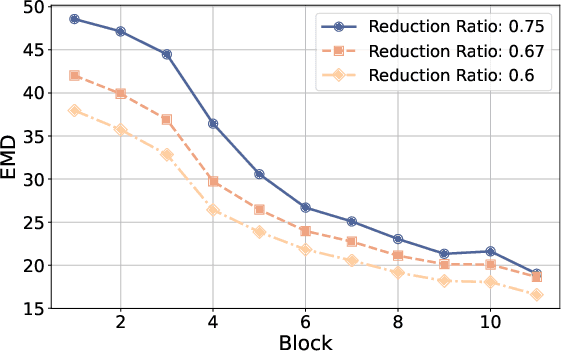
Recently, Multi-modal Large Language Models (MLLMs) have shown remarkable effectiveness for multi-modal tasks due to their abilities to generate and understand cross-modal data. However, processing long sequences of visual tokens extracted from visual backbones poses a challenge for deployment in real-time applications. To address this issue, we introduce FOLDER, a simple yet effective plug-and-play module designed to reduce the length of the visual token sequence, mitigating both computational and memory demands during training and inference. Through a comprehensive analysis of the token reduction process, we analyze the information loss introduced by different reduction strategies and develop FOLDER to preserve key information while removing visual redundancy. We showcase the effectiveness of FOLDER by integrating it into the visual backbone of several MLLMs, significantly accelerating the inference phase. Furthermore, we evaluate its utility as a training accelerator or even performance booster for MLLMs. In both contexts, FOLDER achieves comparable or even better performance than the original models, while dramatically reducing complexity by removing up to 70% of visual tokens.