 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Landmark Detection for assessing hip conditions: A Cross-Modality Validation of MRI versus X-ray
Jan 26, 2026Many clinical screening decisions are based on angle measurements. In particular, FemoroAcetabular Impingement (FAI) screening relies on angles traditionally measured on X-rays. However, assessing the height and span of the impingement area requires also a 3D view through an MRI scan. The two modalities inform the surgeon on different aspects of the condition. In this work, we conduct a matched-cohort validation study (89 patients, paired MRI/X-ray) using standard heatmap regression architectures to assess cross-modality clinical equivalence. Seen that landmark detection has been proven effective on X-rays, we show that MRI also achieves equivalent localisation and diagnostic accuracy for cam-type impingement. Our method demonstrates clinical feasibility for FAI assessment in coronal views of 3D MRI volumes, opening the possibility for volumetric analysis through placing further landmarks. These results support integrating automated FAI assessment into routine MRI workflows. Code is released at https://github.com/Malga-Vision/Landmarks-Hip-Conditions
USV Obstacles Detection and Tracking in Marine Environments
Nov 11, 2025Developing a robust and effective obstacle detection and tracking system for Unmanned Surface Vehicle (USV) at marine environments is a challenging task. Research efforts have been made in this area during the past years by GRAAL lab at the university of Genova that resulted in a methodology for detecting and tracking obstacles on the image plane and, then, locating them in the 3D LiDAR point cloud. In this work, we continue on the developed system by, firstly, evaluating its performance on recently published marine datasets. Then, we integrate the different blocks of the system on ROS platform where we could test it in real-time on synchronized LiDAR and camera data collected in various marine conditions available in the MIT marine datasets. We present a thorough experimental analysis of the results obtained using two approaches; one that uses sensor fusion between the camera and LiDAR to detect and track the obstacles and the other uses only the LiDAR point cloud for the detection and tracking. In the end, we propose a hybrid approach that merges the advantages of both approaches to build an informative obstacles map of the surrounding environment to the USV.
Disentangled representations of microscopy images
Jun 25, 2025Microscopy image analysis is fundamental for different applications, from diagnosis to synthetic engineering and environmental monitoring. Modern acquisition systems have granted the possibility to acquire an escalating amount of images, requiring a consequent development of a large collection of deep learning-based automatic image analysis methods. Although deep neural networks have demonstrated great performance in this field, interpretability, an essential requirement for microscopy image analysis, remains an open challenge. This work proposes a Disentangled Representation Learning (DRL) methodology to enhance model interpretability for microscopy image classification. Exploiting benchmark datasets from three different microscopic image domains (plankton, yeast vacuoles, and human cells), we show how a DRL framework, based on transferring a representation learnt from synthetic data, can provide a good trade-off between accuracy and interpretability in this domain.
Diffusing DeBias: a Recipe for Turning a Bug into a Feature
Feb 13, 2025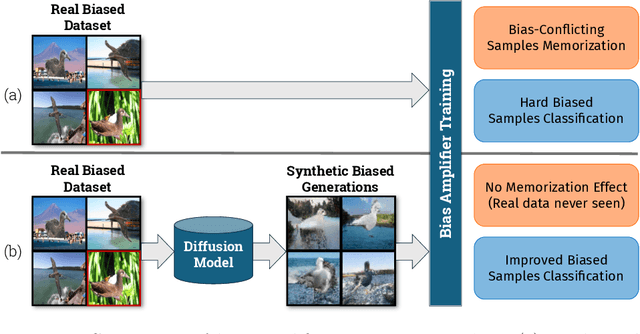
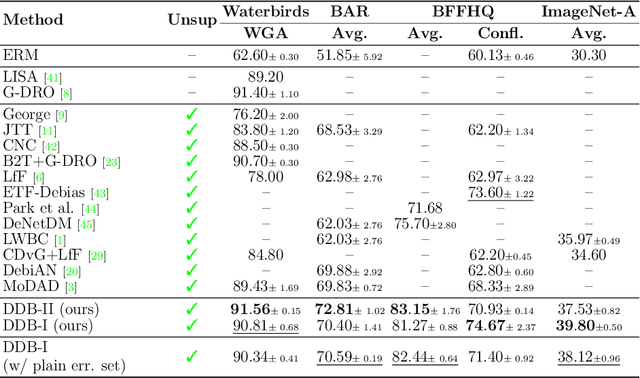
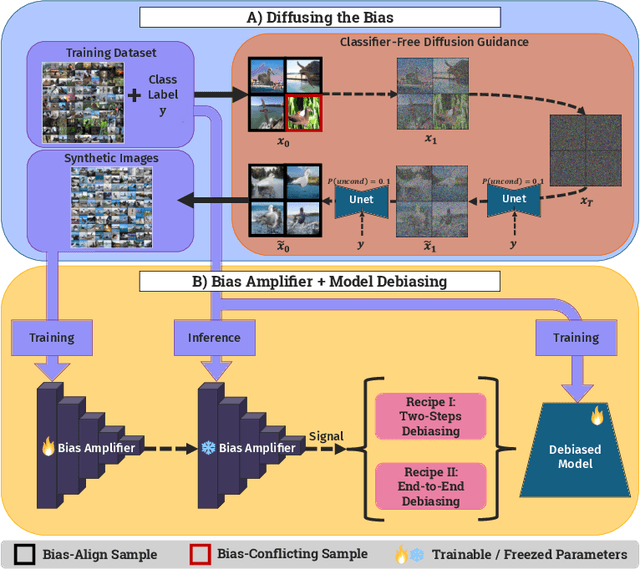

Deep learning model effectiveness in classification tasks is often challenged by the quality and quantity of training data which, whenever containing strong spurious correlations between specific attributes and target labels, can result in unrecoverable biases in model predictions. Tackling these biases is crucial in improving model generalization and trust, especially in real-world scenarios. This paper presents Diffusing DeBias (DDB), a novel approach acting as a plug-in for common methods in model debiasing while exploiting the inherent bias-learning tendency of diffusion models. Our approach leverages conditional diffusion models to generate synthetic bias-aligned images, used to train a bias amplifier model, to be further employed as an auxiliary method in different unsupervised debiasing approaches. Our proposed method, which also tackles the common issue of training set memorization typical of this type of tech- niques, beats current state-of-the-art in multiple benchmark datasets by significant margins, demonstrating its potential as a versatile and effective tool for tackling dataset bias in deep learning applications.
Transferring disentangled representations: bridging the gap between synthetic and real images
Sep 26, 2024


Developing meaningful and efficient representations that separate the fundamental structure of the data generation mechanism is crucial in representation learning. However, Disentangled Representation Learning has not fully shown its potential on real images, because of correlated generative factors, their resolution and limited access to ground truth labels. Specifically on the latter, we investigate the possibility of leveraging synthetic data to learn general-purpose disentangled representations applicable to real data, discussing the effect of fine-tuning and what properties of disentanglement are preserved after the transfer. We provide an extensive empirical study to address these issues. In addition, we propose a new interpretable intervention-based metric, to measure the quality of factors encoding in the representation. Our results indicate that some level of disentanglement, transferring a representation from synthetic to real data, is possible and effective.
Looking at Model Debiasing through the Lens of Anomaly Detection
Jul 25, 2024


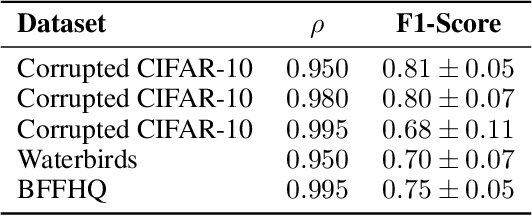
It is widely recognized that deep neural networks are sensitive to bias in the data. This means that during training these models are likely to learn spurious correlations between data and labels, resulting in limited generalization abilities and low performance. In this context, model debiasing approaches can be devised aiming at reducing the model's dependency on such unwanted correlations, either leveraging the knowledge of bias information or not. In this work, we focus on the latter and more realistic scenario, showing the importance of accurately predicting the bias-conflicting and bias-aligned samples to obtain compelling performance in bias mitigation. On this ground, we propose to conceive the problem of model bias from an out-of-distribution perspective, introducing a new bias identification method based on anomaly detection. We claim that when data is mostly biased, bias-conflicting samples can be regarded as outliers with respect to the bias-aligned distribution in the feature space of a biased model, thus allowing for precisely detecting them with an anomaly detection method. Coupling the proposed bias identification approach with bias-conflicting data upsampling and augmentation in a two-step strategy, we reach state-of-the-art performance on synthetic and real benchmark datasets. Ultimately, our proposed approach shows that the data bias issue does not necessarily require complex debiasing methods, given that an accurate bias identification procedure is defined.
Self-supervised pre-training with diffusion model for few-shot landmark detection in x-ray images
Jul 25, 2024
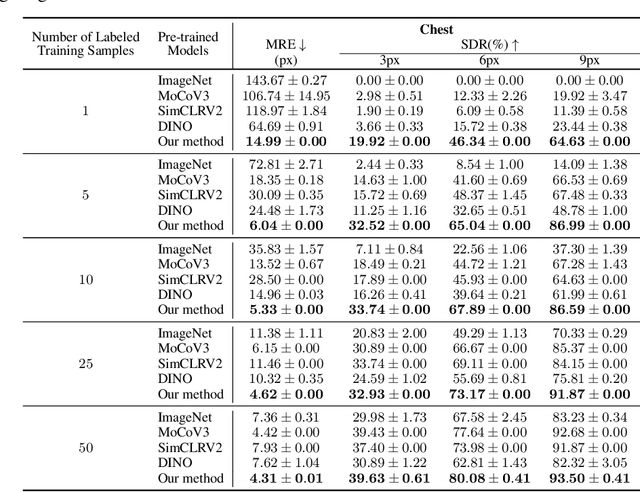


In the last few years, deep neural networks have been extensively applied in the medical domain for different tasks, ranging from image classification and segmentation to landmark detection. However, the application of these technologies in the medical domain is often hindered by data scarcity, both in terms of available annotations and images. This study introduces a new self-supervised pre-training protocol based on diffusion models for landmark detection in x-ray images. Our results show that the proposed self-supervised framework can provide accurate landmark detection with a minimal number of available annotated training images (up to 50), outperforming ImageNet supervised pre-training and state-of-the-art self-supervised pre-trainings for three popular x-ray benchmark datasets. To our knowledge, this is the first exploration of diffusion models for self-supervised learning in landmark detection, which may offer a valuable pre-training approach in few-shot regimes, for mitigating data scarcity.
Is in-domain data beneficial in transfer learning for landmarks detection in x-ray images?
Mar 03, 2024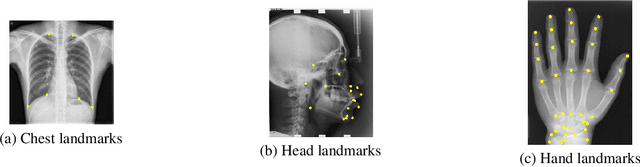
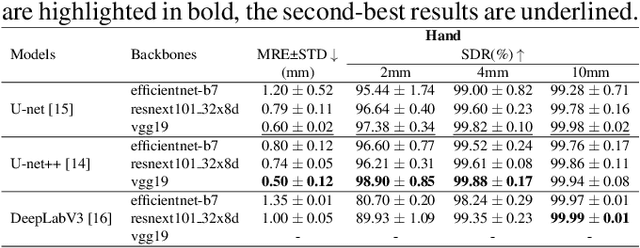
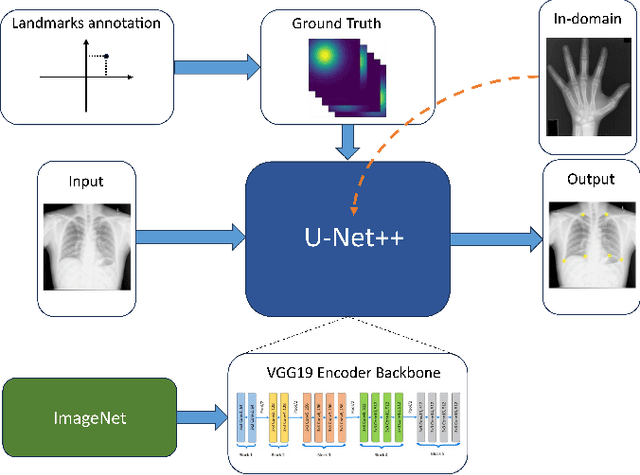

In recent years, deep learning has emerged as a promising technique for medical image analysis. However, this application domain is likely to suffer from a limited availability of large public datasets and annotations. A common solution to these challenges in deep learning is the usage of a transfer learning framework, typically with a fine-tuning protocol, where a large-scale source dataset is used to pre-train a model, further fine-tuned on the target dataset. In this paper, we present a systematic study analyzing whether the usage of small-scale in-domain x-ray image datasets may provide any improvement for landmark detection over models pre-trained on large natural image datasets only. We focus on the multi-landmark localization task for three datasets, including chest, head, and hand x-ray images. Our results show that using in-domain source datasets brings marginal or no benefit with respect to an ImageNet out-of-domain pre-training. Our findings can provide an indication for the development of robust landmark detection systems in medical images when no large annotated dataset is available.
View-to-Label: Multi-View Consistency for Self-Supervised 3D Object Detection
May 29, 2023
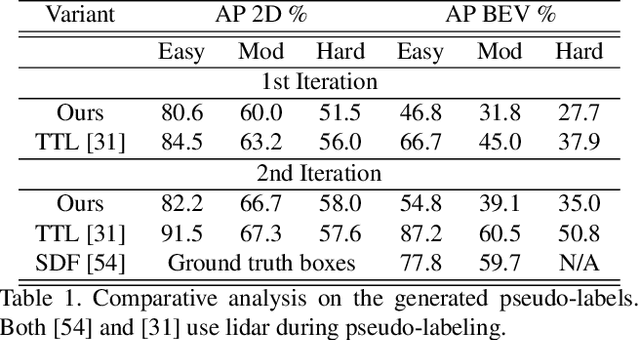
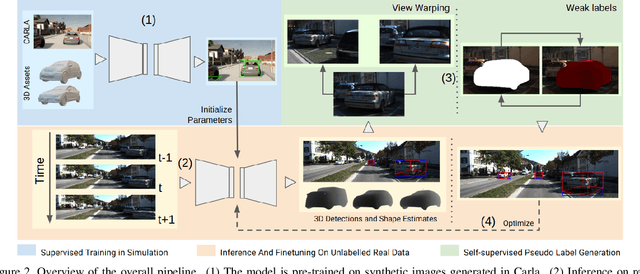

For autonomous vehicles, driving safely is highly dependent on the capability to correctly perceive the environment in 3D space, hence the task of 3D object detection represents a fundamental aspect of perception. While 3D sensors deliver accurate metric perception, monocular approaches enjoy cost and availability advantages that are valuable in a wide range of applications. Unfortunately, training monocular methods requires a vast amount of annotated data. Interestingly, self-supervised approaches have recently been successfully applied to ease the training process and unlock access to widely available unlabelled data. While related research leverages different priors including LIDAR scans and stereo images, such priors again limit usability. Therefore, in this work, we propose a novel approach to self-supervise 3D object detection purely from RGB sequences alone, leveraging multi-view constraints and weak labels. Our experiments on KITTI 3D dataset demonstrate performance on par with state-of-the-art self-supervised methods using LIDAR scans or stereo images.
Fine-tuning or top-tuning? Transfer learning with pretrained features and fast kernel methods
Sep 16, 2022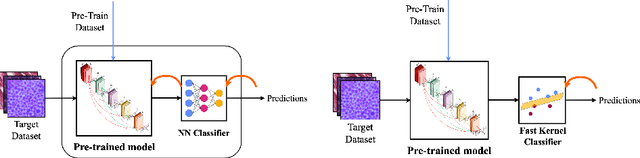

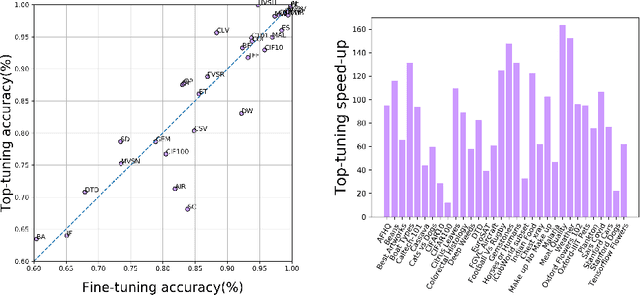

The impressive performances of deep learning architectures is associated to massive increase of models complexity. Millions of parameters need be tuned, with training and inference time scaling accordingly. But is massive fine-tuning necessary? In this paper, focusing on image classification, we consider a simple transfer learning approach exploiting pretrained convolutional features as input for a fast kernel method. We refer to this approach as top-tuning, since only the kernel classifier is trained. By performing more than 2500 training processes we show that this top-tuning approach provides comparable accuracy w.r.t. fine-tuning, with a training time that is between one and two orders of magnitude smaller. These results suggest that top-tuning provides a useful alternative to fine-tuning in small/medium datasets, especially when training efficiency is crucial.