 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-to-Label: Temporal Consistency for Self-Supervised Monocular 3D Object Detection
Paper and Code
Mar 04, 2022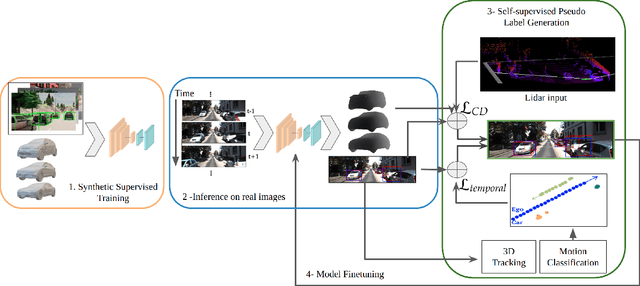
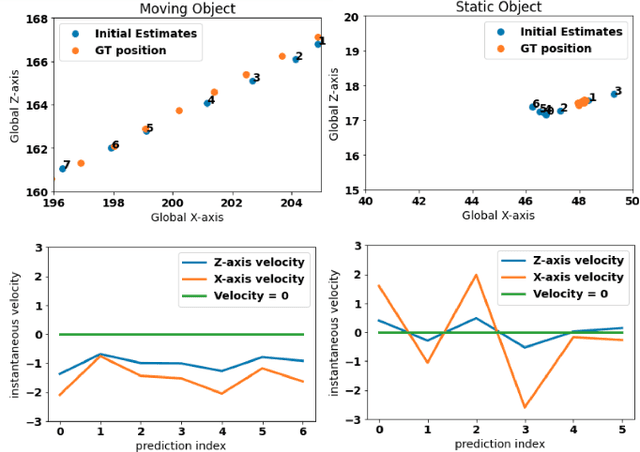

Monocular 3D object detection continues to attract attention due to the cost benefits and wider availability of RGB cameras. Despite the recent advances and the ability to acquire data at scale, annotation cost and complexity still limit the size of 3D object detection datasets in the supervised settings. Self-supervised methods, on the other hand, aim at training deep networks relying on pretext tasks or various consistency constraints. Moreover, other 3D perception tasks (such as depth estimation) have shown the benefits of temporal priors as a self-supervision signal. In this work, we argue that the temporal consistency on the level of object poses, provides an important supervision signal given the strong prior on physical motion. Specifically, we propose a self-supervised loss which uses this consistency, in addition to render-and-compare losses, to refine noisy pose predictions and derive high-quality pseudo labels. To assess the effectiveness of the proposed method, we finetune a synthetically trained monocular 3D object detection model using the pseudo-labels that we generated on real data. Evaluation on the standard KITTI3D benchmark demonstrates that our method reaches competitive performance compared to other monocular self-supervised and supervised methods.