 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-to-Label: Multi-View Consistency for Self-Supervised 3D Object Detection
May 29, 2023
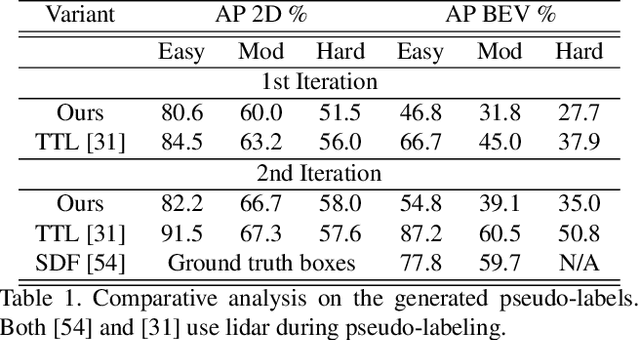

For autonomous vehicles, driving safely is highly dependent on the capability to correctly perceive the environment in 3D space, hence the task of 3D object detection represents a fundamental aspect of perception. While 3D sensors deliver accurate metric perception, monocular approaches enjoy cost and availability advantages that are valuable in a wide range of applications. Unfortunately, training monocular methods requires a vast amount of annotated data. Interestingly, self-supervised approaches have recently been successfully applied to ease the training process and unlock access to widely available unlabelled data. While related research leverages different priors including LIDAR scans and stereo images, such priors again limit usability. Therefore, in this work, we propose a novel approach to self-supervise 3D object detection purely from RGB sequences alone, leveraging multi-view constraints and weak labels. Our experiments on KITTI 3D dataset demonstrate performance on par with state-of-the-art self-supervised methods using LIDAR scans or stereo images.
FasterVideo: Efficient Online Joint Object Detection And Tracking
Apr 15, 2022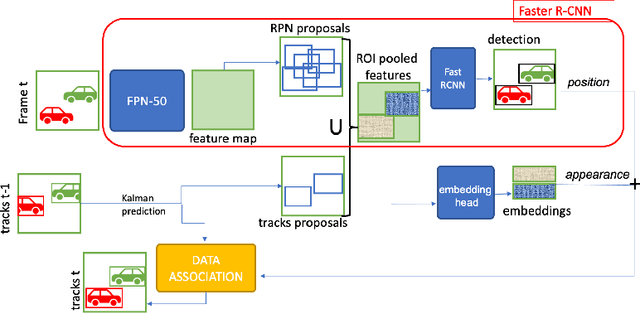

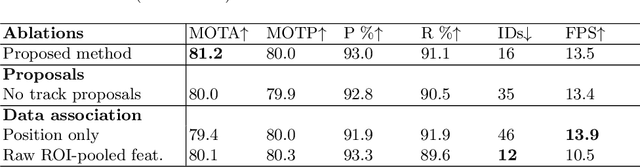
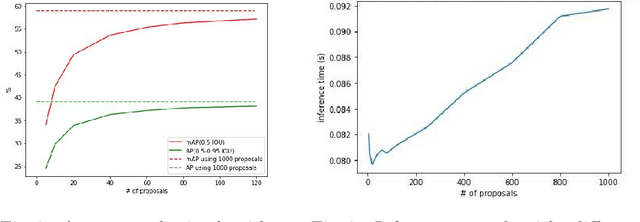
Object detection and tracking in videos represent essential and computationally demanding building blocks for current and future visual perception systems. In order to reduce the efficiency gap between available methods and computational requirements of real-world applications, we propose to re-think one of the most successful methods for image object detection, Faster R-CNN, and extend it to the video domain. Specifically, we extend the detection framework to learn instance-level embeddings which prove beneficial for data association and re-identification purposes. Focusing on the computational aspects of detection and tracking, our proposed method reaches a very high computational efficiency necessary for relevant applications, while still managing to compete with recent and state-of-the-art methods as shown in the experiments we conduct on standard object tracking benchmarks
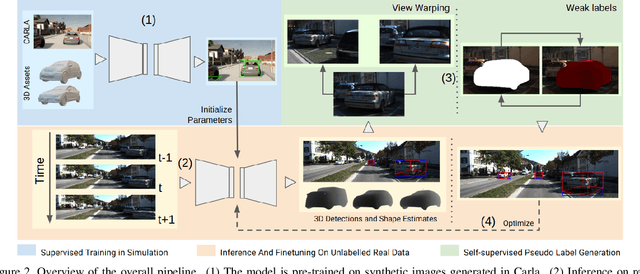
Time-to-Label: Temporal Consistency for Self-Supervised Monocular 3D Object Detection
Mar 04, 2022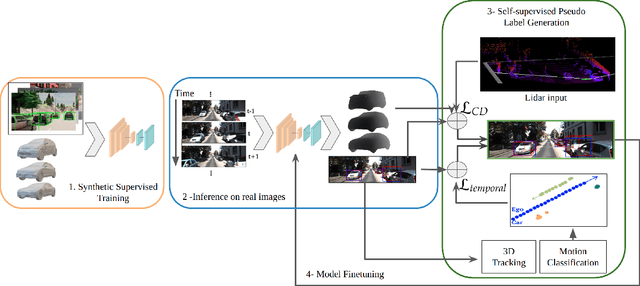
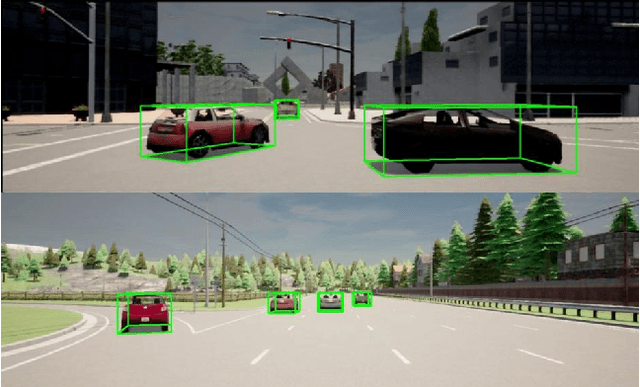
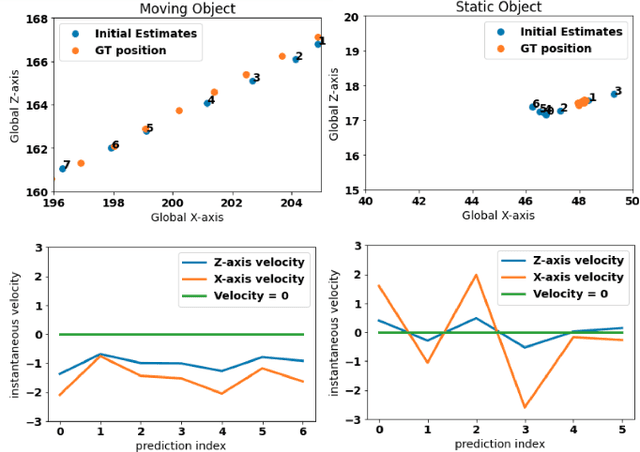

Monocular 3D object detection continues to attract attention due to the cost benefits and wider availability of RGB cameras. Despite the recent advances and the ability to acquire data at scale, annotation cost and complexity still limit the size of 3D object detection datasets in the supervised settings. Self-supervised methods, on the other hand, aim at training deep networks relying on pretext tasks or various consistency constraints. Moreover, other 3D perception tasks (such as depth estimation) have shown the benefits of temporal priors as a self-supervision signal. In this work, we argue that the temporal consistency on the level of object poses, provides an important supervision signal given the strong prior on physical motion. Specifically, we propose a self-supervised loss which uses this consistency, in addition to render-and-compare losses, to refine noisy pose predictions and derive high-quality pseudo labels. To assess the effectiveness of the proposed method, we finetune a synthetically trained monocular 3D object detection model using the pseudo-labels that we generated on real data. Evaluation on the standard KITTI3D benchmark demonstrates that our method reaches competitive performance compared to other monocular self-supervised and supervised methods.