 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning or top-tuning? Transfer learning with pretrained features and fast kernel methods
Sep 16, 2022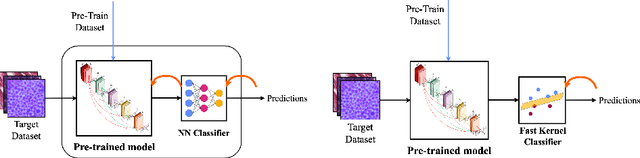

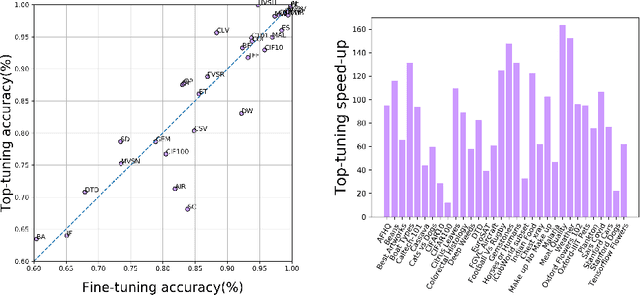

The impressive performances of deep learning architectures is associated to massive increase of models complexity. Millions of parameters need be tuned, with training and inference time scaling accordingly. But is massive fine-tuning necessary? In this paper, focusing on image classification, we consider a simple transfer learning approach exploiting pretrained convolutional features as input for a fast kernel method. We refer to this approach as top-tuning, since only the kernel classifier is trained. By performing more than 2500 training processes we show that this top-tuning approach provides comparable accuracy w.r.t. fine-tuning, with a training time that is between one and two orders of magnitude smaller. These results suggest that top-tuning provides a useful alternative to fine-tuning in small/medium datasets, especially when training efficiency is crucial.
Efficient Unsupervised Learning for Plankton Images
Sep 14, 2022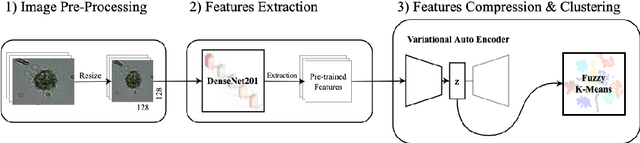

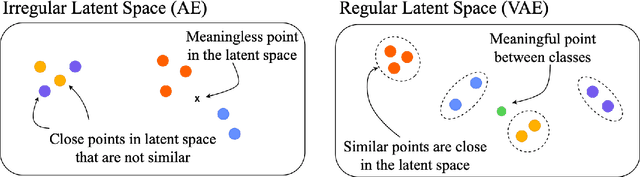

Monitoring plankton populations in situ is fundamental to preserve the aquatic ecosystem. Plankton microorganisms are in fact susceptible of minor environmental perturbations, that can reflect into consequent morphological and dynamical modifications. Nowadays, the availability of advanced automatic or semi-automatic acquisition systems has been allowing the production of an increasingly large amount of plankton image data. The adoption of machine learning algorithms to classify such data may be affected by the significant cost of manual annotation, due to both the huge quantity of acquired data and the numerosity of plankton species. To address these challenges, we propose an efficient unsupervised learning pipeline to provide accurate classification of plankton microorganisms. We build a set of image descriptors exploiting a two-step procedure. First, a Variational Autoencoder (VAE) is trained on features extracted by a pre-trained neural network. We then use the learnt latent space as image descriptor for clustering. We compare our method with state-of-the-art unsupervised approaches, where a set of pre-defined hand-crafted features is used for clustering of plankton images. The proposed pipeline outperforms the benchmark algorithms for all the plankton datasets included in our analysis, providing better image embedding properties.