 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking at Model Debiasing through the Lens of Anomaly Detection
Jul 25, 2024


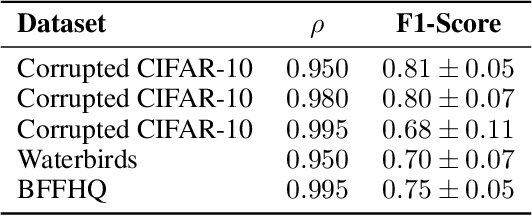
It is widely recognized that deep neural networks are sensitive to bias in the data. This means that during training these models are likely to learn spurious correlations between data and labels, resulting in limited generalization abilities and low performance. In this context, model debiasing approaches can be devised aiming at reducing the model's dependency on such unwanted correlations, either leveraging the knowledge of bias information or not. In this work, we focus on the latter and more realistic scenario, showing the importance of accurately predicting the bias-conflicting and bias-aligned samples to obtain compelling performance in bias mitigation. On this ground, we propose to conceive the problem of model bias from an out-of-distribution perspective, introducing a new bias identification method based on anomaly detection. We claim that when data is mostly biased, bias-conflicting samples can be regarded as outliers with respect to the bias-aligned distribution in the feature space of a biased model, thus allowing for precisely detecting them with an anomaly detection method. Coupling the proposed bias identification approach with bias-conflicting data upsampling and augmentation in a two-step strategy, we reach state-of-the-art performance on synthetic and real benchmark datasets. Ultimately, our proposed approach shows that the data bias issue does not necessarily require complex debiasing methods, given that an accurate bias identification procedure is defined.