 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusing DeBias: a Recipe for Turning a Bug into a Feature
Feb 13, 2025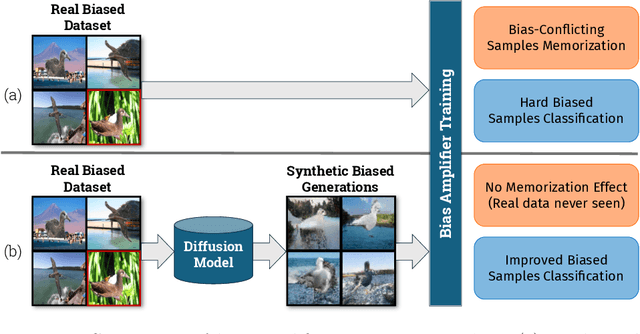
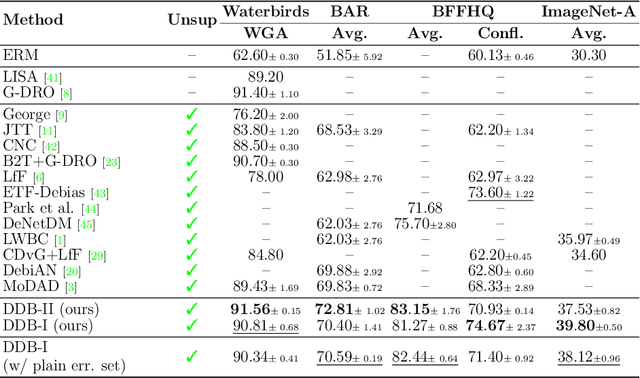
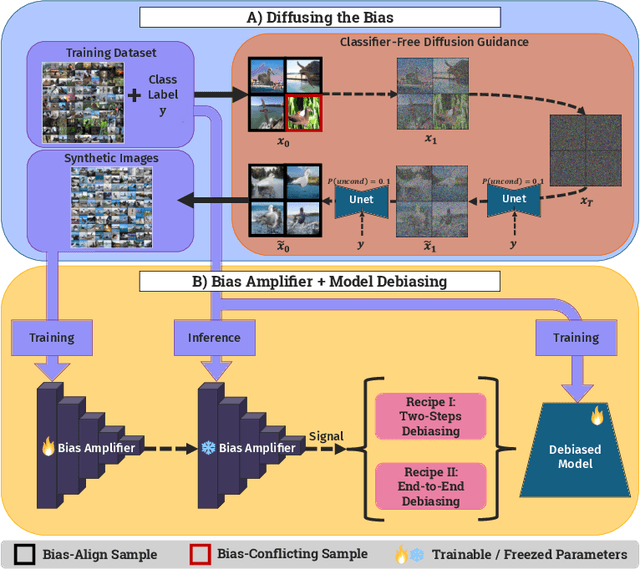

Deep learning model effectiveness in classification tasks is often challenged by the quality and quantity of training data which, whenever containing strong spurious correlations between specific attributes and target labels, can result in unrecoverable biases in model predictions. Tackling these biases is crucial in improving model generalization and trust, especially in real-world scenarios. This paper presents Diffusing DeBias (DDB), a novel approach acting as a plug-in for common methods in model debiasing while exploiting the inherent bias-learning tendency of diffusion models. Our approach leverages conditional diffusion models to generate synthetic bias-aligned images, used to train a bias amplifier model, to be further employed as an auxiliary method in different unsupervised debiasing approaches. Our proposed method, which also tackles the common issue of training set memorization typical of this type of tech- niques, beats current state-of-the-art in multiple benchmark datasets by significant margins, demonstrating its potential as a versatile and effective tool for tackling dataset bias in deep learning applications.
Say My Name: a Model's Bias Discovery Framework
Aug 18, 2024In the last few years, due to the broad applicability of deep learning to downstream tasks and end-to-end training capabilities, increasingly more concerns about potential biases to specific, non-representative patterns have been raised. Many works focusing on unsupervised debiasing usually leverage the tendency of deep models to learn ``easier'' samples, for example by clustering the latent space to obtain bias pseudo-labels. However, the interpretation of such pseudo-labels is not trivial, especially for a non-expert end user, as it does not provide semantic information about the bias features. To address this issue, we introduce ``Say My Name'' (SaMyNa), the first tool to identify biases within deep models semantically. Unlike existing methods, our approach focuses on biases learned by the model. Our text-based pipeline enhances explainability and supports debiasing efforts: applicable during either training or post-hoc validation, our method can disentangle task-related information and proposes itself as a tool to analyze biases. Evaluation on traditional benchmarks demonstrates its effectiveness in detecting biases and even disclaiming them, showcasing its broad applicability for model diagnosis.
Looking at Model Debiasing through the Lens of Anomaly Detection
Jul 25, 2024


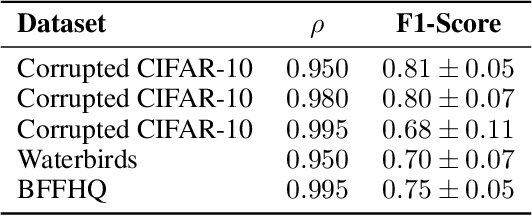
It is widely recognized that deep neural networks are sensitive to bias in the data. This means that during training these models are likely to learn spurious correlations between data and labels, resulting in limited generalization abilities and low performance. In this context, model debiasing approaches can be devised aiming at reducing the model's dependency on such unwanted correlations, either leveraging the knowledge of bias information or not. In this work, we focus on the latter and more realistic scenario, showing the importance of accurately predicting the bias-conflicting and bias-aligned samples to obtain compelling performance in bias mitigation. On this ground, we propose to conceive the problem of model bias from an out-of-distribution perspective, introducing a new bias identification method based on anomaly detection. We claim that when data is mostly biased, bias-conflicting samples can be regarded as outliers with respect to the bias-aligned distribution in the feature space of a biased model, thus allowing for precisely detecting them with an anomaly detection method. Coupling the proposed bias identification approach with bias-conflicting data upsampling and augmentation in a two-step strategy, we reach state-of-the-art performance on synthetic and real benchmark datasets. Ultimately, our proposed approach shows that the data bias issue does not necessarily require complex debiasing methods, given that an accurate bias identification procedure is defined.